Paper Reading - Deep Captioning with Multimodal Recurrent Neural Networks ( m-RNN ) ( ICLR 2015 ) ★
Link of the Paper: https://arxiv.org/pdf/1412.6632.pdf
Main Points:
- The authors propose a multimodal Recurrent Neural Networks ( AlexNet/VGGNet + a multimodal layer + RNNs ). Their work has two major differences from these methods. Firstly, they incorporate a two-layer word embedding system in the m-RNN network structure which learns the word representation more efficiently than the single-layer word embedding. Secondly, they do not use the recurrent layer to store the visual information. The image representation is inputted to the m-RNN model along with every word in the sentence description.
- Most of the sentence-image multimodal models use pre-computed word embedding vectors as the initialization of their models. In contrast, the authors randomly initialize their word embedding layers and learn them from the training data.
- The m-RNN model is trained using a log-likelihood cost function. The errors can be backpropagated to the three parts ( the vision part, the language part, and the ) of the m-RNN model to update the model parameters simultaneously.
- The hyperparameters, such as layer dimensions and the choice of the non-linear activation functions, are tuned via cross-validation on Flickr8K dataset and are then fixed across all the experiments.
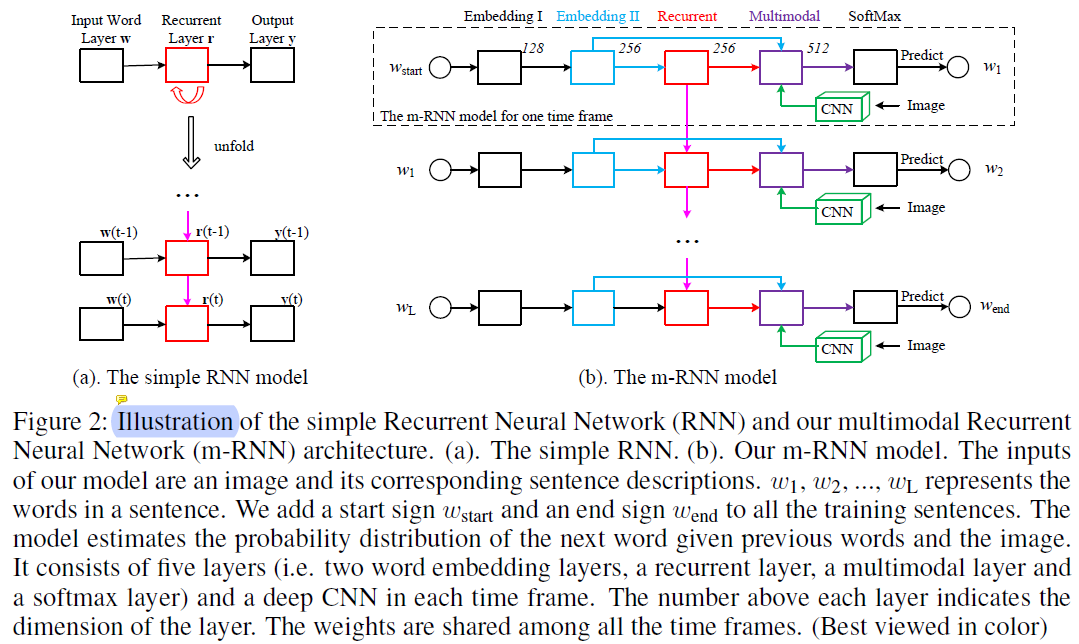
Other Key Points:
- Applications for Image Captioning: early childhood education, image retrieval, and navigation for the blind.
- There are generally three categories of methods for generating novel sentence descriptions for images. The first category assumes a specific rule of the language grammer. They parse the sentence and divide it into several parts. This kind of method generates sentences that are syntactically correct. The second category retrieves similar captioned images, and generates new descriptions by generalizing and re-composing the retrieved captions. The third category of methods, which is more related to our method, learns a probability density over the space of multimodal inputs, using for example, Deep Boltzmann Machines, and topic models. They generate sentences with richer and more flexible structure than the first group. The probability of generating sentences using the model can serve as the affinity metric for retrieval.
- Many previous methods treat the task of describing images as a retrieval task and formulate the problem as a ranking or embedding learning problem. They first extract the word and sentence features ( e.g. Socher et al.(2014) uses dependency tree Recursive Neural Network to extract sentence features ) as well as the image features. Then they optimize a ranking cost to learn an embedding model that maps both the sentence feature and the image feature to a common semantic feature space ( the same semantic space ). In this way, they can directly calculate the distance between images and sentences. These methods genarate image captions by retrieving them from a sentence database. Thus, they lack the ability of generating novel sentences or describing images that contain novel combinations of objects and scenes.
- Benchmark datasets for Image Captioning: IAPR TC-12 ( Grubinger et al.(2006) ), Flickr8K ( Rashtchian et al.(2010) ), Flickr30K ( Young et al.(2014) ) and MS COCO ( Lin et al.(2014) ).
- Evaluation Metrics for Sentence Generation: Sentence perplexity and BLUE scores.
- Tasks related to Image Captioning: Generating Novel Sentences, Retrieving Images Given a Sentence, Retrieving Sentences Given an Image.
- The m-RNN model is trained using Baidu's internal deep learning platform PADDLE.
Paper Reading - Deep Captioning with Multimodal Recurrent Neural Networks ( m-RNN ) ( ICLR 2015 ) ★的更多相关文章
- Paper Reading - Sequence to Sequence Learning with Neural Networks ( NIPS 2014 )
Link of the Paper: https://arxiv.org/pdf/1409.3215.pdf Main Points: Encoder-Decoder Model: Input seq ...
- 递归神经网络(Recurrent Neural Networks,RNN)
在深度学习领域,传统的多层感知机(MLP)具有出色的表现,取得了许多成功,它曾在许多不同的任务上——包括手写数字识别和目标分类上创造了记录.甚至到了今天,MLP在解决分类任务上始终都比其他方法要略胜一 ...
- Paper Reading - Deep Visual-Semantic Alignments for Generating Image Descriptions ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1412.2306 Main Points: An Alignment Model: Convolutional Ne ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
- Hyperspectral Image Classification Using Similarity Measurements-Based Deep Recurrent Neural Networks
用RNN来做像素分类,输入是一系列相近的像素,长度人为指定为l,相近是利用像素相似度或是范围相似度得到的,计算个欧氏距离或是SAM. 数据是两个高光谱数据 1.Pavia University,Ref ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- The Unreasonable Effectiveness of Recurrent Neural Networks (RNN)
http://karpathy.github.io/2015/05/21/rnn-effectiveness/ There’s something magical about Recurrent Ne ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- (zhuan) Attention in Long Short-Term Memory Recurrent Neural Networks
Attention in Long Short-Term Memory Recurrent Neural Networks by Jason Brownlee on June 30, 2017 in ...
随机推荐
- Java导包后在测试类中执行正确但在Servlet中执行错误报ClassNotFoundException或者ClassDefNotFoundException解决办法
将原来导的包remove from build path,并复制到Web-root下的lib目录中,再add to build path,
- c#的传输组件dotnetty
牛皮不多了,绩效吹起.... 最近一直看大家写的东西,了解的内容不少,我的牛皮也差不多吹完了.... 最后在说说最近测试的dotnetty.去年弄下来试了,不行,最近又弄下来了看看,可以了.哇哈哈哈哈 ...
- MySQL5.7.24安装笔记
一.下载mysql-5.7.24 wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.24-el7-x86_64.tar.gz 二 ...
- Wtrofms
一.安装 安装:pip3 install wtforms 二.使用1(登录) from flask import Flask, render_template, request, redirect f ...
- vue 解决跨域问题
1.后端处理允许跨域 2.反向代理跨域 代理服务器英文全称是Proxy Server,其功能就是代理网络用户去去的网络信息.形象的说:它是网络信息的中转站. vue中设置代理: 1.config/in ...
- [Golang学习笔记] 07 数组和切片
01-06回顾: Go语言开发环境配置, 常用源码文件写法, 程序实体(尤其是变量)及其相关各种概念和编程技巧: 类型推断,变量重声明,可重名变量,类型推断,类型转换,别名类型和潜在类型 数组: 数组 ...
- 核密度估计 Kernel Density Estimation (KDE) MATLAB
对于已经得到的样本集,核密度估计是一种可以求得样本的分布的概率密度函数的方法: 通过选取核函数和合适的带宽,可以得到样本的distribution probability,在这里核函数选取标准正态分布 ...
- 【洛谷】 3264 [JLOI2015] 管道连接
前言: 如果还不知道斯坦纳树的童鞋可以看这两篇博客: 我的:https://blog.csdn.net/jerry_wang119/article/details/80001711 我一开始学 ...
- 20155211实验二 Java面向对象程序设计
20155211实验二 Java面向对象程序设计 实验内容 1.初步掌握单元测试和TDD 2.理解并掌握面向对象三要素:封装.继承.多态 3.初步掌握UML建模 4.熟悉S.O.L.I.D原则 5.了 ...
- 20155302 实验三 敏捷开发与XP实践
20155302 实验三 敏捷开发与XP实践 实验内容 XP基础 XP核心实践 相关工具 实验内容及步骤 (一)编码标准 在IDEA中使用工具(Code->Reformate Code)把代码重 ...