2.0 flume、sqoop、oozie/Azkaban
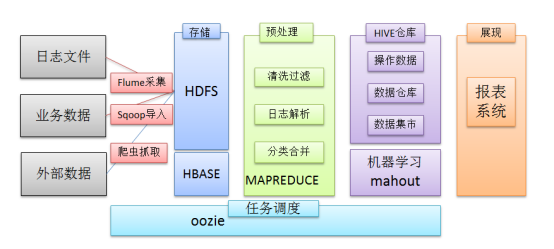
在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架。
1 日志采集框架Flume
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka队列等众多外部存储系统中
一般的采集需求,通过对flume的简单配置即可实现
Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
1.1运行过程
1、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2、 每一个agent相当于一个数据传递员,内部有三个组件:
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink
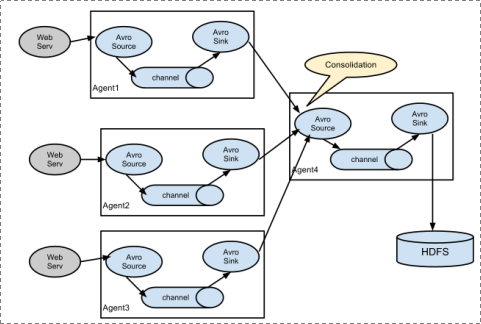
Flume支持众多的source和sink类型
1.2Flume的安装部署
1、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
2 工作流调度器azkaban
一个完整的数据分析系统通常都是由大量任务单元组成:
shell脚本程序,java程序,mapreduce程序、hive脚本等 各任务单元之间存在时间先后及前后依赖关系
l为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
简单的任务调度:直接使用linux的crontab来定义;
复杂的任务调度:开发调度平台
或使用现成的开源调度系统,比如ooize、azkaban等
2.1Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
它有如下功能特点:
² Web用户界面
² 方便上传工作流
² 方便设置任务之间的关系
² 调度工作流
² 认证/授权(权限的工作
² 能够杀死并重新启动工作流
² 模块化和可插拔的插件机制
² 项目工作区
² 工作流和任务的日志记录和审计
2.2Azkaban与Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
功能
两者均可以调度mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务
工作流定义
Azkaban使用Properties文件定义工作流
Oozie使用XML文件定义工作流
工作流传参
Azkaban支持直接传参,例如${input}
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
定时执行
Azkaban的定时执行任务是基于时间的
Oozie的定时执行任务基于时间和输入数据
资源管理
Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie暂无严格的权限控制
工作流执行
Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点)
Oozie作为工作流服务器运行,支持多用户和多工作流
工作流管理
Azkaban支持浏览器以及ajax方式操作工作流
Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
3 sqoop数据迁移
3.1作用
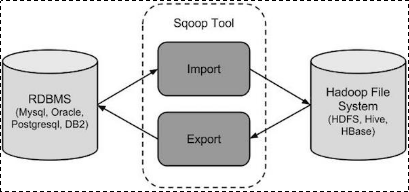
sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库
3.2工作机制
将导入或导出命令翻译成mapreduce程序来实现
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
3.3 sqoop安装
安装sqoop的前提是已经具备java和hadoop的环境
1、下载并解压
最新版下载地址http://ftp.wayne.edu/apache/sqoop/1.4.6/
2、修改配置文件
$ cd $SQOOP_HOME/conf
$ mv sqoop-env-template.sh sqoop-env.sh
打开sqoop-env.sh并编辑下面几行:
export HADOOP_COMMON_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HADOOP_MAPRED_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HIVE_HOME=/home/hadoop/apps/hive-1.2.1
3、加入mysql的jdbc驱动包
cp ~/app/hive/lib/mysql-connector-java-5.1.28.jar $SQOOP_HOME/lib/
4、验证启动
$ cd $SQOOP_HOME/bin
$ sqoop-version
预期的输出:
15/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Sqoop 1.4.6 git commit id 5b34accaca7de251fc91161733f906af2eddbe83
Compiled by abe on Fri Aug 1 11:19:26 PDT 2015
到这里,整个Sqoop安装工作完成。
2.0 flume、sqoop、oozie/Azkaban的更多相关文章
- [转]云计算之hadoop、hive、hue、oozie、sqoop、hbase、zookeeper环境搭建及配置文件
云计算之hadoop.hive.hue.oozie.sqoop.hbase.zookeeper环境搭建及配置文件已经托管到githubhttps://github.com/sxyx2008/clou ...
- 开源作业调度工具实现开源的Datax、Sqoop、Kettle等ETL工具的作业批量自动化调度
1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳 ...
- 数据集成工具Kettle、Sqoop、DataX的比较
数据集成工具很多,下面是几个使用比较多的开源工具. 1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).H ...
- ETL工具Datax、sqoop、kettle 的区别
一.Sqoop主要特点: 1.可以将关系型数据库中的数据导入到hdfs,hive,hbase等hadoop组件中,也可以将hadoop组件中的数据导入到关系型数据库中: 2.sqoop在导入导出数据时 ...
- 3.12-3.16 Hbase集成hive、sqoop、hue
一.Hbase集成hive https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration 1.说明 Hive与HBase整合在一起 ...
- hive、sqoop、MySQL间的数据传递
hdfs到MySQL csv/txt文件到hdfs MySQL到hdfs hive与hdfs的映射: drop table if exists emp;create table emp ( id i ...
- 基于Hadoop技术实现的离线电商分析平台(Flume、Hadoop、Hbase、SpringMVC、highcharts)
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解.尤其是在电商.旅游.银行.证券.游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握 ...
- 3-hive、sqoop
1.HIVE 1.交互命令 use db_name; create database db_name //创建数据库 create database if not exists db_name //创 ...
- HBase零基础高阶应用实战(CDH5、二级索引、实践、DBA)
HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利用了Google文件 ...
随机推荐
- echo图片延迟加载js
插件描述:和 Lazy Load 一样,Echo.js 也是一个用于图像延迟加载 JavaScript.不同的是 Lazy Load 是基于 jQuery 的插件,而 Echo.js 不依赖于 jQu ...
- Loadrunner手动关联详解
Loadrunner手动关联详解 一.关联的含义: 关联(correlation):在脚本回放过程中,客户端发出请求,通过关联函数所定义的左右边界值(也就是关联规则),在服务器所响应的内容中查找,得到 ...
- 修改 Hue 默认数据库
Hue 更改默认数据 1. 需要安装 mysql 一下包 mysql-server mysql-devel mysql-shared mysql-client mysql-python shared ...
- linux下安装protobuf及cmake编译
一.protobuf 安装 protobuf版本:2.6.1 下载地址:https://github.com/google/protobuf/archive/v2.6.1.zip 解压之后进入目录 修 ...
- python使用tablib库生成xls表格
参考文档:http://python-tablib.org Tablib是一个MIT许可的格式不可知的表格数据集库.它允许您导入,导出和操作表格数据集.高级功能包括隔离,动态列,标签和过滤,以及无缝格 ...
- python学习之python入门
一.第一句Python代码 1.在d:/test_py目录下新建一个test.py文件,并在其中写上如下内容: print("Hello World") 2.在cmd命令行下执行t ...
- 轻松解决U盘加密问题
很多小伙伴常常会遇到这样的问题,比如说有朋友或者同事想借用你的u盘,处于人情世故你又不得不借,但是又不喜欢自己的文件被别人看到或者担心丢失或被修改,在此提供一种给u盘加密或者给u盘里的文件加密的方法. ...
- 常见的Content-Type类型
Content-Type说明 MediaType,即是Internet Media Type,互联网媒体类型:也叫做MIME类型, 在Http协议消息头中,使用Content-Type来表示具体请求中 ...
- # 2017-2018-1 20155232《信息安全技术》实验二——Windows口令破解
2017-2018-1 20155232<信息安全技术>实验二--Windows口令破解 [实验目的] 了解Windows口令破解原理 对信息安全有直观感性认识 能够运用工具实现口令破解 ...
- 20155305乔磊2016-2017-2《Java程序设计》第十周学习总结
20155305乔磊2016-2017-2<Java程序设计>第十周学习总结 教材学习内容总结 Java的网络编程 网络编程 网络编程就是在两个或两个以上的设备(例如计算机)之间传输数据. ...