asp.net core microservices 架构之分布式自动计算(三)-kafka日志同步至elasticsearch和kibana展示
一 kafka consumer准备
前面的章节进行了分布式job的自动计算的概念讲解以及实践。上次分布式日志说过日志写进kafka,是需要进行处理,以便合理的进行展示,分布式日志的量和我们对日志的重视程度,决定了我们必须要有一个大数据检索,和友好展示的需求。那么自然就是elasticsearch和kibana,elasticsearch是可以检索TB级别数据的一个分布式NOSQL数据库,而kibana,不仅仅可以展示详情,而且有针对不同展示需求的功能,并且定制了很多很多日志格式的模板和采集数据的插件,这里不多介绍了,我自己感觉是比percona的pmm强大很多。
书归正传,我们这一节是要做同步前的准备工作。第一,对kafka的consumer进行封装。第二,读取kafka数据是需要一个后台程序去处理,但是不需要job,我们上次做的框架是基于zookeeper的分布式job,而kafka的分布式是在服务器端的,当然将job分布式设计方案用在轮询或者阻塞方式的后台程序,也是可以的,但是这次就不讲解了。下面我们就将kafka分布式的原理分析下,kafka的客户端有一个组的概念,borker端有一个topic的概念,product在发送消息的时候,会有一个key值。因为kafka存数据就是以key-value的方式存储数据的,所以broker就是用product传递过来的这个key进行运算,合理的将数据存储到某个topic的某个分区。而consumer端订阅topic,可以订阅多个topic,它的分派是这样的,每一个topic下的分区会有多个consuer,但是这些consumer必须属于不同的组,而每一个consumer可以订阅多个topic下的分区,但是不能重复。下面看图吧,以我们这次实际的日志为例,在kafka中mylog topic有5个分区。

那么如果我们有三个程序需要用这个mylog topic怎么办?而且我们需要很快的处理完这个数据,所以有可能这三个程序每一个程序都要两台服务器。想着都很头大,对吧?当然如果有我们前面讲解的分布式job也可以处理,但是要把分布式的功能迁移到这个后台程序,避免不了又大动干戈,开发,调试,测试,修改bug,直到程序稳定,那又是一场苦功。但是在kafka这里,不用担心,三个程序,比如订单,库存,顾客,我们为这三个程序的kafka客户端对应的设置为三个组,每一个组中consumer数量只要不超过5个,假如订单需要用到名为mylog的topic的消息,只要订单处理这个topic的实例数量,必须不能超过5个,当然可以少于5个,也可以等于0个。而同时一个consumer又可以去订阅多个topic,这也是kafka可以媲美rabbit的重要的一个原因,先天支持并发和扩展。我们看图:
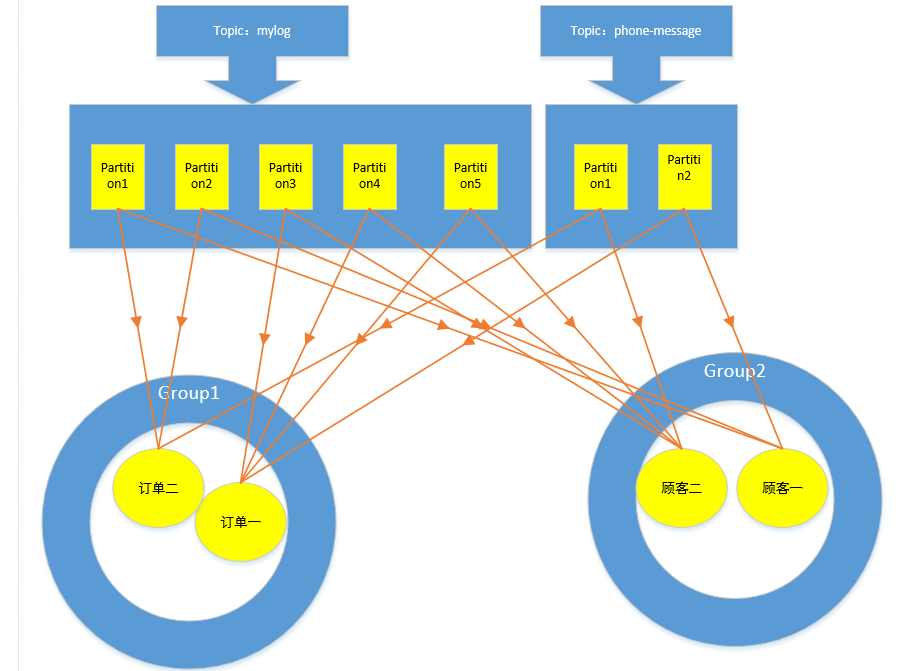
如果一个组的consumer数量没有topic的分区多,kafka会自动分派给这个组的consumer,如果某一个consumer失败,kafka也会自动的将这个consumer的offset记录并且分派给另外一个consumer。
但是要注意一点,kafka的topic中的每个分区是线性的,但是所有的分区看起来就不会是线性的,如果需要topic是线性的,就必须将分区设置为1个。
下面看看我们封装的kafka客户端方法:
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
using Confluent.Kafka;
using Microsoft.Extensions.Options; namespace Walt.Framework.Service.Kafka
{
public class KafkaService : IKafkaService
{ private KafkaOptions _kafkaOptions;
private Producer _producer;
private Consumer _consumer; public Action<Message> GetMessageDele{ get; set; } public Action<Error> ErrorDele{ get; set; } public Action<LogMessage> LogDele{ get; set; } public KafkaService(IOptionsMonitor<KafkaOptions> kafkaOptions)
{
_kafkaOptions=kafkaOptions.CurrentValue;
kafkaOptions.OnChange((kafkaOpt,s)=>{
_kafkaOptions=kafkaOpt;
System.Diagnostics.Debug
.WriteLine(Newtonsoft.Json.JsonConvert.SerializeObject(kafkaOpt)+"---"+s);
});
_producer=new Producer(_kafkaOptions.Properties); _consumer=new Consumer(_kafkaOptions.Properties);
} private byte[] ConvertToByte(string str)
{
return System.Text.Encoding.Default.GetBytes(str);
} public async Task<Message> Producer<T>(string topic,string key,T t)
{
if(string.IsNullOrEmpty(topic)
|| t==null)
{
throw new ArgumentNullException("topic或者value不能为null.");
}
string data = Newtonsoft.Json.JsonConvert.SerializeObject(t);
var task= await _producer.ProduceAsync(topic,ConvertToByte(key),ConvertToByte(data));
return task;
} public void AddProductEvent()
{
_producer.OnError+=new EventHandler<Error>(Error);
_producer.OnLog+=new EventHandler<LogMessage>(Log);
}
///以事件的方式获取message
public void AddConsumerEvent(IEnumerable<string> topics)
{
_consumer.Subscribe(topics);
_consumer.OnMessage += new EventHandler<Message>(GetMessage);
_consumer.OnError += new EventHandler<Error>(Error);
_consumer.OnLog += new EventHandler<LogMessage>(Log);
} private void GetMessage(object sender, Message mess)
{
if(GetMessageDele!=null)
{
GetMessageDele(mess);
}
} private void Error(object sender, Error mess)
{
if(ErrorDele!=null)
{
ErrorDele(mess);
}
} private void Log(object sender, LogMessage mess)
{
if(LogDele!=null)
{
LogDele(mess);
}
}
//以轮询的方式获取message
public Message Poll(int timeoutMilliseconds)
{
Message message =default(Message);
_consumer.Consume(out message, timeoutMilliseconds);
return message;
}
}
}
以事件激发的方式,因为是线程安全的方式调用,而本实例是后台方式执行,少不了多线程,所以还是以轮询的方式。以轮询的方式,这样的程序需要放那块尼?就是我们的后台程序框架。
二 后台程序管理框架开发
他的原理和job几乎差不多,比job要简单多了。看入口程序:
using System;
using System.Collections.Generic;
using System.Collections.ObjectModel;
using System.IO;
using System.Linq;
using System.Reflection;
using System.Threading.Tasks;
using Microsoft.AspNetCore;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
using EnvironmentName = Microsoft.Extensions.Hosting.EnvironmentName;
using Walt.Framework.Log;
using Walt.Framework.Service;
using Walt.Framework.Service.Kafka;
using Walt.Framework.Configuration;
using MySql.Data.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore;
using System.Threading;
using IApplicationLife =Microsoft.Extensions.Hosting;
using IApplicationLifetime = Microsoft.Extensions.Hosting.IApplicationLifetime; namespace Walt.Framework.Console
{
public class Program
{
public static void Main(string[] args)
{
//这里获取程序及和工作线程配置信息
Dictionary<string, Assembly> assmblyColl = new Dictionary<string, Assembly>();
var host = new HostBuilder()
.UseEnvironment(EnvironmentName.Development) .ConfigureAppConfiguration((hostContext, configApp) =>
{
//这里netcore支持多数据源,所以可以扩展到数据库或者redis,集中进行配置。
//
configApp.SetBasePath(Directory.GetCurrentDirectory());
configApp.AddJsonFile(
$"appsettings.{hostContext.HostingEnvironment.EnvironmentName}.json",
optional: true);
configApp.AddEnvironmentVariables("PREFIX_");
configApp.AddCommandLine(args);
}).ConfigureLogging((hostContext, configBuild) =>
{
configBuild.AddConfiguration(hostContext.Configuration.GetSection("Logging"));
configBuild.AddConsole();
configBuild.AddCustomizationLogger();
})
.ConfigureServices((hostContext, service) =>
{
service.Configure<HostOptions>(option =>
{
option.ShutdownTimeout = System.TimeSpan.FromSeconds();
}); service.AddKafka(KafkaBuilder =>
{
KafkaBuilder.AddConfiguration(hostContext.Configuration.GetSection("KafkaService"));
});
service.AddElasticsearchClient(config=>{
config.AddConfiguration(hostContext.Configuration.GetSection("ElasticsearchService"));
}); service.AddDbContext<ConsoleDbContext>(option =>
option.UseMySQL(hostContext.Configuration.GetConnectionString("ConsoleDatabase")), ServiceLifetime.Transient, ServiceLifetime.Transient);
///TODO 待实现从数据库中pull数据,再将任务添加进DI
service.AddSingleton<IConsole,KafkaToElasticsearch>();
})
.Build();
CancellationTokenSource source = new CancellationTokenSource();
CancellationToken token = source.Token;
var task=Task.Run(async () =>{
IConsole console = host.Services.GetService<IConsole>();
await console.AsyncExcute(source.Token);
},source.Token);
Dictionary<string, Task> dictTask = new Dictionary<string, Task>();
dictTask.Add("kafkatoelasticsearch", task); int recordRunCount = ;
var fact = host.Services.GetService<ILoggerFactory>();
var log = fact.CreateLogger<Program>();
var disp = Task.Run(() =>
{
while (true)
{
if (!token.IsCancellationRequested)
{
++recordRunCount;
foreach (KeyValuePair<string, Task> item in dictTask)
{
if (item.Value.IsCanceled
|| item.Value.IsCompleted
|| item.Value.IsCompletedSuccessfully
|| item.Value.IsFaulted)
{
log.LogWarning("console任务:{0},参数:{1},执行异常,task状态:{2}", item.Key, "", item.Value.Status);
if (item.Value.Exception != null)
{
log.LogError(item.Value.Exception, "task:{0},参数:{1},执行错误.", item.Key, "");
//TODO 根据参数更新数据库状态,以便被监控到。
}
//更新数据库状态。
}
}
}
System.Threading.Thread.Sleep();
log.LogInformation("循环:{0}次,接下来等待2秒。", recordRunCount);
}
},source.Token); IApplicationLifetime appLiftTime = host.Services.GetService<IApplicationLifetime>();
appLiftTime.ApplicationStopping.Register(()=>{
log.LogInformation("程序停止中。");
source.Cancel();
log.LogInformation("程序停止完成。");
});
host.RunAsync().GetAwaiter().GetResult();
}
}
}
因为分布式job有quartz,是有自己的设计理念,但是这个console后台框架不需要,是自己开发,所以完全和Host通用主机兼容,所有的部件都可以DI。设计原理就是以数据库的配置,构造Task,然后使用
CancellationTokenSource和TaskCompletionSource去管理Task。运行结果根据状态去更新数据库,以便监控。当然咱们这个例子功能没实现全,后面可以完善
,感兴趣的可以去我的github上pull代码。咱们看任务中的例子代码:
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks;
using Confluent.Kafka;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Logging;
using Nest;
using Walt.Framework.Log;
using Walt.Framework.Service.Elasticsearch;
using Walt.Framework.Service.Kafka; namespace Walt.Framework.Console
{
public class KafkaToElasticsearch : IConsole
{
ILoggerFactory _logFact; IConfiguration _config; IElasticsearchService _elasticsearch; IKafkaService _kafkaService; public KafkaToElasticsearch(ILoggerFactory logFact,IConfiguration config
,IElasticsearchService elasticsearch
,IKafkaService kafkaService)
{
_logFact = logFact;
_config = config;
_elasticsearch = elasticsearch;
_kafkaService = kafkaService;
}
public async Task AsyncExcute(CancellationToken cancel=default(CancellationToken))
{
var log = _logFact.CreateLogger<KafkaToElasticsearch>();
_kafkaService.AddConsumerEvent(new List<string>(){"mylog"}); //以事件方式获取message不工作,因为跨线程
// _kafkaService.GetMessageDele = (message) => {
// var id = message.Key;
// var offset = string.Format("{0}---{2}",message.Offset.IsSpecial,message.Offset.Value);
// var topic = message.Topic;
// var topicPartition = message.TopicPartition.Partition.ToString();
// var topicPartitionOffsetValue = message.TopicPartitionOffset.Offset.Value;
// // log.LogInformation("id:{0},offset:{1},topic:{2},topicpatiton:{3},topicPartitionOffsetValue:{4}"
// // ,id,offset,topic,topicPartition,topicPartitionOffsetValue);
// };
// _kafkaService.ErrorDele = (message) => {
// log.LogError(message.ToString());
// };
// _kafkaService.LogDele = (message) => {
// log.LogInformation(message.ToString());
// };
// log.LogInformation("事件添加完毕");
// var waitForStop =
// new TaskCompletionSource<object>(TaskCreationOptions.RunContinuationsAsynchronously);
// cancel.Register(()=>{
// log.LogInformation("task执行被取消回掉函数");
// waitForStop.SetResult(null);
// });
// waitForStop.Task.Wait();
// log.LogInformation("任务已经被取消。");
//下面以轮询方式。
if(!cancel.IsCancellationRequested)
{
while (true)
{
Message message = _kafkaService.Poll();
if (message != null)
{
if(message.Error!=null&&message.Error.Code!=ErrorCode.NoError)
{
//log.LogError("consumer获取message出错,详细信息:{0}",message.Error);
System.Console.WriteLine("consumer获取message出错,详细信息:{0}",message.Error);
System.Threading.Thread.Sleep();
continue;
}
var id =message.Key==null?"":System.Text.Encoding.Default.GetString(message.Key);
var offset = string.Format("{0}---{1}", message.Offset.IsSpecial, message.Offset.Value);
var topic = message.Topic;
var topicPartition = message.TopicPartition.Partition.ToString();
var topicPartitionOffsetValue = message.TopicPartitionOffset.Offset.Value;
var val =System.Text.Encoding.Default.GetString( message.Value);
EntityMessages entityMess =
Newtonsoft.Json.JsonConvert.DeserializeObject<EntityMessages>(val);
await _elasticsearch.CreateIndexIfNoExists<LogElasticsearch>("mylog"+entityMess.OtherFlag);
// _elasticsearch.CreateMappingIfNoExists<LogElasticsearch>("mylog"+entityMess.OtherFlag
// ,"mylog"+entityMess.OtherFlag+"type",null); //为elasticsearch添加document
var addDocumentResponse = await _elasticsearch.CreateDocument<LogElasticsearch>("mylog" + entityMess.OtherFlag
, new LogElasticsearch()
{
Id = entityMess.Id,
Time = entityMess.DateTime,
LogLevel = entityMess.LogLevel,
Exception = entityMess.Message
}
);
if (addDocumentResponse != null)
{
if (!addDocumentResponse.ApiCall.Success)
{ }
}
}
}
}
return ;
}
}
}
三 elasticsearch 服务开发
服务已经开发很多了,主要就是构建和配置的设计,还有就是对组件的封装,看程序结构:

配置:
{
"Logging": {
"LogLevel": {
"Default": "Information",
"System": "Information",
"Microsoft": "Information"
},
"KafkaLog":{
"Prix":"console", //目前这个属性,可以放程序类别,比如用户中心,商品等。
"LogStoreTopic":"mylog"
}
},
"KafkaService":{
"Properties":{
"bootstrap.servers":"192.168.249.106:9092",
"group.id":"group2"
}
},
"ConnectionStrings": {
"ConsoleDatabase":"Server=192.168.249.106;Database=quartz;Uid=quartz;Pwd=quartz"
},
"ElasticsearchService":{
"Host":["http://192.168.249.105:9200","http://localhost:9200"],
"TimeOut":"10000",
"User":"",
"Pass":""
}
}
服务类:这里有必要说下,elasticsearch是基于api的接口,最底层就是http请求,在接口上,实现了一个高级的接口和一个低级别的接口,当然低级别的接口需要熟悉elasticsearch的协议,
而高级别的api,使用强类型去使用,对开发很有帮助。下面是封装elasticsearch的服务类:
using System;
using System.Net.Http;
using Elasticsearch.Net;
using Microsoft.Extensions.Options;
using System.Threading.Tasks;
using Microsoft.Extensions.Logging;
using Nest; namespace Walt.Framework.Service.Elasticsearch
{
public class ElasticsearchService:IElasticsearchService
{ private ElasticsearchOptions _elasticsearchOptions=null; private ElasticClient _elasticClient = null; private ILoggerFactory _loggerFac; public ElasticsearchService(IOptionsMonitor<ElasticsearchOptions> options
,ILoggerFactory loggerFac)
{
_elasticsearchOptions = options.CurrentValue;
options.OnChange((elasticsearchOpt,s)=>{
_elasticsearchOptions=elasticsearchOpt;
System.Diagnostics.Debug
.WriteLine(Newtonsoft.Json.JsonConvert.SerializeObject(elasticsearchOpt)+"---"+s);
});
//连接客户端需,支持多个节点,防止单点故障
var lowlevelClient = new ElasticLowLevelClient();
var urlColl = new Uri[_elasticsearchOptions.Host.Length];
for (int i = ; i < _elasticsearchOptions.Host.Length;i++)
{
urlColl[i] = new Uri(_elasticsearchOptions.Host[i]);
}
_loggerFac = loggerFac;
var connectionPool = new SniffingConnectionPool(urlColl);
var settings = new ConnectionSettings(connectionPool)
.RequestTimeout(TimeSpan.FromMinutes(_elasticsearchOptions.TimeOut))
.DefaultIndex("mylogjob");//设置默认的index
_elasticClient = new ElasticClient(settings);
}
//如果index存在,则返回,如果不存在,则创建,type的创建方式是为文档类型打标签ElasticsearchTypeAttribute
public async Task<bool> CreateIndexIfNoExists<T>(string indexName) where T : class
{ var log = _loggerFac.CreateLogger<ElasticsearchService>();
var exists = await _elasticClient.IndexExistsAsync(Indices.Index(indexName));
if (exists.Exists)
{
log.LogWarning("index:{0}已经存在", indexName.ToString());
return await Task.FromResult(true);
}
var response = await _elasticClient.CreateIndexAsync(indexName
,c=>c.Mappings(mm=>mm.Map<T>(m=>m.AutoMap())));//将类型的属性自动映射到index的type上,也可以打标签控制那个可以映射,那些不可以
log.LogInformation(response.DebugInformation);
if (response.Acknowledged)
{
log.LogInformation("index:{0},创建成功", indexName.ToString());
return await Task.FromResult(false);
}
else
{
log.LogError(response.ServerError.ToString());
log.LogError(response.OriginalException.ToString());
return await Task.FromResult(false);
}
} //创建document
public async Task<ICreateResponse> CreateDocument<T>(string indexName,T t) where T:class
{
var log=_loggerFac.CreateLogger<ElasticsearchService>();
if(t==null)
{
log.LogError("bulk 参数不能为空。");
return null;
}
IndexRequest<T> request = new IndexRequest<T>(indexName, TypeName.From<T>()) { Document = t }; var createResponse = await _elasticClient.CreateDocumentAsync<T>(t);
log.LogInformation(createResponse.DebugInformation);
if (createResponse.ApiCall.Success)
{
log.LogInformation("index:{0},type:{1},创建成功", createResponse.Index, createResponse.Type);
return createResponse;
}
else
{
log.LogError(createResponse.ServerError.ToString());
log.LogError(createResponse.OriginalException.ToString());
return null;
}
}
}
}
poco类型,这个类会和index的typ相关联的:
using System;
using Nest; namespace Walt.Framework.Console
{
[ElasticsearchTypeAttribute(Name="LogElasticsearchDefaultType")] //可以使用类型生成和查找type
public class LogElasticsearch
{
public string Id { get; set; } public DateTime Time { get; set; } public string LogLevel{ get; set; } public string Exception{ get; set; } public string Mess{ get; set; }
}
}
然后就是执行我们console后台程序,就可以在kibana看到日志被同步的情况:

所有程序都提交到github,如果调试代码,再看这篇文章,或许理解能更快。
asp.net core microservices 架构之分布式自动计算(三)-kafka日志同步至elasticsearch和kibana展示的更多相关文章
- asp.net core microservices 架构之 分布式自动计算(一)
一:简介 自动计算都是常驻内存的,没有人机交互.我们经常用到的就是console job和sql job了.sqljob有自己的宿主,与数据库产品有很关联,暂时不提.console job使 ...
- asp.net core microservices 架构之 分布式自动计算(二)
一 简介 上一篇介绍了zookeeper如何进行分布式协调,这次主要讲解quartz使用zookeeper进行分布式计算,因为上一篇只是讲解原理,而这次实际使用, ...
- .net core microservices 架构之 分布式
.net core microservices 架构之 分布式 一:简介 自动计算都是常驻内存的,没有人机交互.我们经常用到的就是console job和sql job了.sqljob有自己的宿 ...
- asp.net core mcroservices 架构之 分布式日志(一)
一 简介 无论是微服务还是其他任何分布式系统,都需要一个统一处理日志的系统,这个系统 必须有收集,索引,分析查询的功能.asp .net core自己的日志是同步方式的,正如文档所言: 所以必须自己提 ...
- asp.net core microservices 架构之eureka服务发现
一 简介 微服务将需多的功能拆分为许多的轻量级的子应用,这些子应用相互调度.好处就是轻量级,完全符合了敏捷开发的精神.我们知道ut(单元测试),不仅仅提高我们的程序的健壮性,而且可以强制将类和方法的设 ...
- asp.net core mcroservices 架构之 分布式日志(三):集成kafka
一 kafka介绍 kafka是基于zookeeper的一个分布式流平台,既然是流,那么大家都能猜到它的存储结构基本上就是线性的了.硬盘大家都知道读写非常的慢,那是因为在随机情况下,线性下,硬盘的读写 ...
- asp.net core microservices 架构之Task 事务一致性 事件源 详解
一 aspnetcore之task的任务状态-CancellationToken 我有一篇文章讲解了asp.net的线程方面的知识.我们知道.net的针对于多线程的一个亮点就是Task,net clr ...
- asp.net core mcroservices 架构之 分布式日志(二)之自定义日志开发
netcore日志原理 netcore的日志是作为一个扩展库存在的,每个组件都有它的入口,那么作为研究这个组件的入口是最好的,首先看两种方式: 这个是源码例子提供的. var loggingConfi ...
- ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IDistributedCache、StackExchangeRedis
ASP.NET Core 使用 Redis 实现分布式缓存:Docker.IDistributedCache.StackExchangeRedis 前提:一台 Linux 服务器.已安装 Docker ...
随机推荐
- mongodb安装及副本集搭建
mongodb下载地址:https://www.mongodb.com/dr/fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel62-3.2.7.tg ...
- php \r \n 和 <br/> \t
利用\r \n 和 <br/> \t做了个实验,话不多说,看代码就很清楚的知道
- 70. Climbing Stairs(动态规划 爬台阶,一次只能爬1,2两节)
You are climbing a stair case. It takes n steps to reach to the top. Each time you can either climb ...
- Java 对比Vector、ArrayList、LinkedList
①引言 在日常生活中能高效的管理和操作数据是非常重要的.Java提供了强大的集合框架,大大提高了开发者的生产力,今天就了解一下有关集合框架方面的问题. Vector.ArrayList.LinkedL ...
- Android 自定义View-字母索引表(一)
在有些Android应用中,为了方便快速定位,经常会看到屏幕右侧有一个字母索引表,今天尝试使用自定义View的方式实现了索引表的基本布局. 字母索引表的样式如下面的示意图所示, 此时我们至少需要知道以 ...
- inline用法详解
(一)inline函数(摘自C++ Primer的第三版) 在函数声明或定义中函数返回类型前加上关键字inline即把min()指定为内联. inline int min(int first, int ...
- Python3.x:requests的用法
Python3.x:requests的用法 1,requests 比 urllib.request 容错能力更强: 2,通常用法: (1).认证.状态码.header.编码.json r = requ ...
- phpstorm2016.1 添加对Drupal的编程支持
一.前言 phpstorm作为目前对drupal支持最好的开发工具之一,是drupal模块开发的首选工具.今天我就来谈谈最新的phpstorm如何添加对drupal模块的支持. 相关环境:操作系统ub ...
- Tomcat启动报StackOverflowError
近期工程部署到Tomcat时,出现以下异常: 16-May-2018 09:35:25.590 严重 [localhost-startStop-1] org.apache.catalina.core. ...
- ESXi上的固态硬盘识别为非SSD
启动ESXi的SSH服务 通过SSH远程连接ESXi主机 输入如下命令 # esxcli storage nmp device list #列出储存清单(SSD设备的“device na ...