LambdaMART简介——基于Ranklib源码(一 lambda计算)
学习Machine Learning,阅读文献,看各种数学公式的推导,其实是一件很枯燥的事情。有的时候即使理解了数学推导过程,也仍然会一知半解,离自己写程序实现,似乎还有一道鸿沟。所幸的是,现在很多主流的Machine Learning方法,网上都有open source的实现,进一步的阅读这些源码,多做一些实验,有助于深入的理解方法。
Ranklib就是一套优秀的Learning to Rank领域的开源实现,其主页在:http://people.cs.umass.edu/~vdang/ranklib.html,从主页中可以看到实现了哪些方法。其中由微软发布的LambdaMART是IR业内常用的Learning to Rank模型,本文介绍RanklibV2.1(当前最新的时RanklibV2.3,应该大同小异)中的LambdaMART实现,用以帮助理解paper中阐述的方法。
LambdaMART.java中的LambdaMART.learn()是学习流程的管控函数,学习过程主要有下面四步构成:
1. 计算deltaNDCG以及lambda;
2. 以lambda作为label训练一棵regression tree;
3. 在tree的每个叶子节点通过预测的regression lambda值还原出gamma,即最终输出得分;
4. 用3的模型预测所有训练集合上的得分(+learningRate*gamma),然后用这个得分对每个query的结果排序,计算新的每个query的base ndcg,以此为基础回到第1步,组成森林。
重复这个步骤,直到满足下列两个收敛条件之一:
1. 树的个数达到训练参数设置;
2. Random Forest在validation集合上没有变好。
下面用一组实际的数据来说明整个计算过程,假设我们有10个query的训练数据,每个query下有10个doc,每个q-d对有10个feature,如下:
0 qid:1830 1:0.002736 2:0.000000 3:0.000000 4:0.000000 5:0.002736 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
0 qid:1830 1:0.025992 2:0.125000 3:0.000000 4:0.000000 5:0.027360 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
0 qid:1830 1:0.001368 2:0.000000 3:0.000000 4:0.000000 5:0.001368 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
1 qid:1830 1:0.188782 2:0.375000 3:0.333333 4:1.000000 5:0.195622 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
1 qid:1830 1:0.077975 2:0.500000 3:0.666667 4:0.000000 5:0.086183 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
0 qid:1830 1:0.075239 2:0.125000 3:0.333333 4:0.000000 5:0.077975 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
1 qid:1830 1:0.079343 2:0.250000 3:0.666667 4:0.000000 5:0.084815 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
1 qid:1830 1:0.147743 2:0.000000 3:0.000000 4:0.000000 5:0.147743 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
0 qid:1830 1:0.058824 2:0.000000 3:0.000000 4:0.000000 5:0.058824 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
0 qid:1830 1:0.071135 2:0.125000 3:0.333333 4:0.000000 5:0.073871 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
1 qid:1840 1:0.007364 2:0.200000 3:1.000000 4:0.500000 5:0.013158 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
1 qid:1840 1:0.097202 2:0.000000 3:0.000000 4:0.000000 5:0.096491 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
2 qid:1840 1:0.169367 2:0.000000 3:0.500000 4:0.000000 5:0.169591 6:0.000000 7:0.000000 8:0.000000 9:0.000000 10:0.000000
......
为了简便,省略了余下的数据。上面的数据格式是按照Ranklib readme中要求的格式组织(类似于svmlight),除了行号之外,第一列是q-d对的实际label(人标注数据),第二列是qid,后面10列都是feature。
这份数据每组qid中的doc初始顺序可以是随机的,也可以是从实际的系统中获得的当前顺序。总之这个是计算ndcg的初始状态。对于qid=1830,它的10个doc的初始顺序的label序列是:0, 0, 0, 1, 1, 0, 1, 1, 0, 0(虽然这份序列中只有label值为0和1的,实际中也会有2,3等,由自己的标注标准决定)。我们知道dcg的计算公式是:
\begin{equation} dcg(i)=\frac{2^{label(i)}-1}{log_{2}{(i+1)}} \end{equation}
i表示当前doc在这个qid下的位置(从1开始,避免分母为0),label(i)是doc(i)的标注值。而一个query的dcg则是其下所有doc的加和:
\begin{equation} dcg(query)=\sum_{i}^{ }\frac{2^{label(i)}-1}{log_{2}{(i+1)}} \end{equation}
根据上式可以计算初始状态下每个qid的dcg:
$ dcg(qid=1830)=\frac{2^{0}-1}{log_{2}{(1+1)}}+\frac{2^{0}-1}{log_{2}{(2+1)}}+...+\frac{2^{0}-1}{log_{2}{(10+1)}} $
$ =0+0+0+0.431+0.387+0+0.333+0.315+0+0=1.466 $
要计算ndcg,还需要计算理想集的dcg,将初始状态按照label排序,qid=1830得到的序列是1,1,1,1,0,0,0,0,0,0,计算dcg:
$ ideal\_dcg(qid=1830)=\frac{2^{1}-1}{log_{2}{(1+1)}}+\frac{2^{1}-1}{log_{2}{(2+1)}}+...+\frac{2^{0}-1}{log_{2}{(10+1)}} $
$ =1+0.631+0.5+0.431+0+0+0+0+0+0=2.562 $
两者相除得到初始状态下qid=1830的ndcg:
$ ndcg(qid=1830)=\frac{dcg(qid=1830)}{ideal\_ndcg(qid=1830)}=\frac{1.466}{2.562}=0.572 $
下面要计算每一个doc的deltaNDCG,公式如下:
\begin{equation} deltaNDCG(i,j)=\left |ndcg(original\ sequence)-ndcg(swap(i,j)\ sequence)\right | \end{equation}
deltaNDCG(i,j)是将位置i和位置j的位置互换后产生的ndcg变化(其他位置均不变),显然有相同label的deltaNDCG(i,j)=0。
在qid=1830的初始序列0, 0, 0, 1, 1, 0, 1, 1, 0, 0,由于前3的label都一样,所以deltaNDCG(1,2)=deltaNDCG(1,3)=0,不为0的是deltaNDCG(1,4), deltaNDCG(1,5), deltaNDCG(1,7), deltaNDCG(1,8)。
将1,4位置互换,序列变为1, 0, 0, 0, 1, 0, 1, 1, 0, 0,计算得到dcg=2.036,整个deltaNDCG(1,4)的计算过程如下:
$ dcg(qid=1830,swap(1,4))=\frac{2^{1}-1}{log_{2}{(1+1)}}+\frac{2^{0}-1}{log_{2}{(2+1)}}+...+\frac{2^{0}-1}{log_{2}{(10+1)}} $
$ =1+0+0+0+0.387+0+0.333+0.315+0+0=2.036 $
$ ndcg(swap(1,4))=\frac{dcg(swap(1,4))}{ideal\_dcg}=\frac{2.036}{2.562}=0.795 $
$ deltaNDCG(1,4)=detalNDCG(4,1)=\left |ndcg(original\ sequence)-ndcg(swap(1,4))\right |=\left |0.572-0.795\right |=0.222 $
同样过程可以计算出deltaNDCG(1,5)=0.239, deltaNDCG(1,7)=0.260, deltaNDCG(1,8)=0.267等。
进一步,要计算lambda(i),根据paper,还需要ρ值,ρ可以理解为doci比docj差的概率,其计算公式为:
\begin{equation} \rho _{ij}=\frac{1}{1+e^{\sigma (s_i-s_j)}} \end{equation}
Ranklib中直接取σ=1(σ的值决定rho的S曲线陡峭程度),如下图,蓝,红,绿三种颜色分别对应σ=1,2,4时ρ函数的曲线情形(横坐标是si-sj):
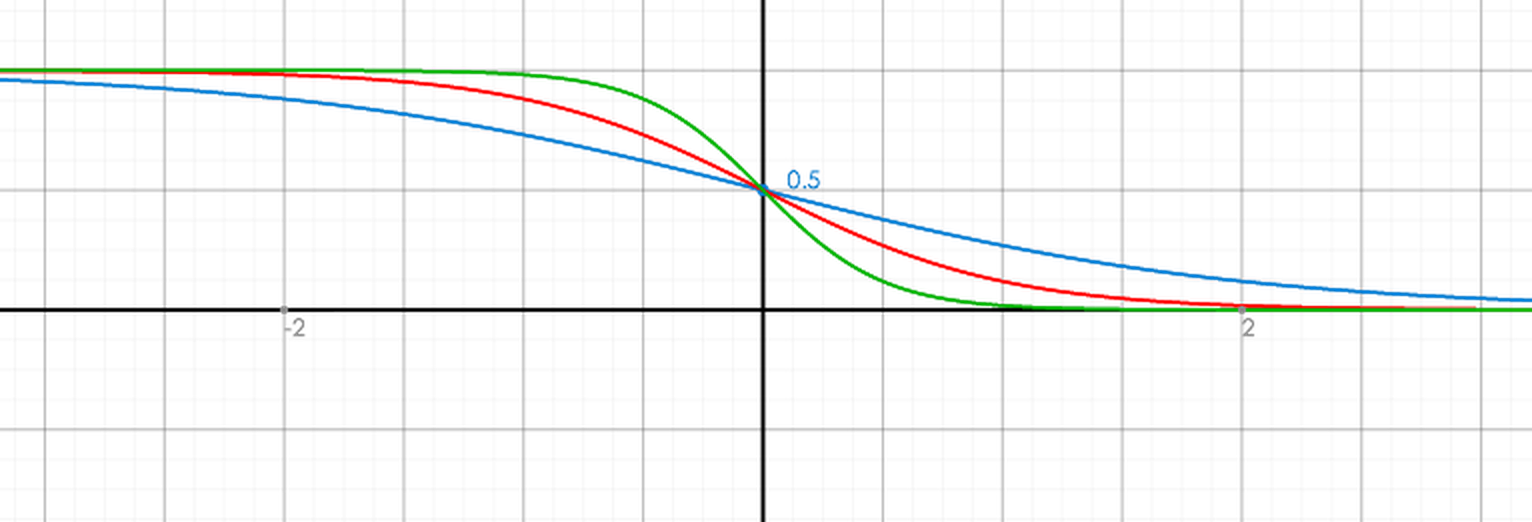
初始时,模型为空,所有模型预测得分都是0,所以si=sj=0,ρij≡1/2,lambda(i,j)的计算公式为:
\begin{equation} \lambda _{ij}=\rho_{ij}*\left |deltaNDCG(i,j)\right | \end{equation}
上式为Ranklib中实际使用的公式,而在paper中,还需要再乘以-σ,在σ=1时,就是符号正好相反,这两种方式是等价的,符号并不影响模型训练结果(其实大可以把代码中lambda的值前面加一个负号,只是注意在每轮计算train, valid和最后计算test的ndcg的时候,模型预测的得分modelScores要按升序排列——越负的doc越好,而不是源代码中按降序。最后训练出的模型是一样的,这说明这两种方式完全对称,所以符号的问题可以省略。甚至不乘以-σ,更符合人的习惯——分数越大越好,降序排列结果。):
\begin{equation} \lambda _{i}=\sum_{j(label(i)>label(j))}{\lambda_{ij}}-\sum_{j(label(i)<label(j))}{\lambda_{ij}} \end{equation}
计算lambda(1),由于label(1)=0,qid=1830中的其他doc的label都大于或者等于0,所以lamda(1)的计算中所有的lambda(1,j)都为负项。将之前计算的各deltaNDCG(1,j)代入,且初始状态下ρij≡1/2,所以:
$ \lambda_1=-0.5*(deltaNDCG(1,3)+deltaNDCG(1,4)+deltaNDCG(1,6)+deltaNDCG(1,7)) $
$ =-0.5*(0.222+ 0.239+ 0.260+ 0.267)=-0.495 $
可以计算出初始状态下qid=1830各个doc的lambda值,如下:
qId=1830 0.000 0.000 0.000 -0.111 -0.120 0.000 -0.130 -0.134 0.000 0.000 lambda(1): -0.495
qId=1830 0.000 0.000 0.000 -0.039 -0.048 0.000 -0.058 -0.062 0.000 0.000 lambda(2): -0.206
qId=1830 0.000 0.000 0.000 -0.014 -0.022 0.000 -0.033 -0.036 0.000 0.000 lambda(3): -0.104
qId=1830 0.111 0.039 0.014 0.000 0.000 0.015 0.000 0.000 0.025 0.028 lambda(4): 0.231
qId=1830 0.120 0.048 0.022 0.000 0.000 0.006 0.000 0.000 0.017 0.019 lambda(5): 0.231
qId=1830 0.000 0.000 0.000 -0.015 -0.006 0.000 -0.004 -0.008 0.000 0.000 lambda(6): -0.033
qId=1830 0.130 0.058 0.033 0.000 0.000 0.004 0.000 0.000 0.006 0.009 lambda(7): 0.240
qId=1830 0.134 0.062 0.036 0.000 0.000 0.008 0.000 0.000 0.003 0.005 lambda(8): 0.247
qId=1830 0.000 0.000 0.000 -0.025 -0.017 0.000 -0.006 -0.003 0.000 0.000 lambda(9): -0.051
qId=1830 0.000 0.000 0.000 -0.028 -0.019 0.000 -0.009 -0.005 0.000 0.000 lambda(10): -0.061
上表中每一列都是考虑了符号的lamda(i,j),即如果label(i)<label(j),则为负值,反之为正值,每行结尾的lamda(i)是前面的加和,即为最终的lambda(i)。
可以看到,lambda(i)在系统中表达了doc(i)上升或者下降的强度,label越高,位置越后,lambda(i)为正值,越大,表示趋向上升的方向,力度也越大;label越小,位置越靠前,lambda(i)为负值,越小,表示趋向下降的方向,力度也大(lambda(i)的绝对值表达了力度。)
然后Regression Tree开始以每个doc的lamda值为目标,训练模型。
LambdaMART简介——基于Ranklib源码(一 lambda计算)的更多相关文章
- LambdaMART简介——基于Ranklib源码(二 Regression Tree训练)
上一节中介绍了 $ \lambda $ 的计算,lambdaMART就以计算的每个doc的 $\lambda$ 值作为label,训练Regression Tree,并在最后对叶子节点上的样本 $la ...
- Java_io体系之PipedWriter、PipedReader简介、走进源码及示例——14
Java_io体系之PipedWriter.PipedReader简介.走进源码及示例——14 ——管道字符输出流.必须建立在管道输入流之上.所以先介绍管道字符输出流.可以先看示例或者总结.总结写的有 ...
- Java_io体系之BufferedWriter、BufferedReader简介、走进源码及示例——16
Java_io体系之BufferedWriter.BufferedReader简介.走进源码及示例——16 一:BufferedWriter 1.类功能简介: BufferedWriter.缓存字符输 ...
- Java_io体系之RandomAccessFile简介、走进源码及示例——20
Java_io体系之RandomAccessFile简介.走进源码及示例——20 RandomAccessFile 1. 类功能简介: 文件随机访问流.关心几个特点: 1.他实现的接口不再 ...
- Ranklib源码剖析--LambdaMart
Ranklib是一套优秀的Learning to Rank领域的开源实现,其中有实现了MART,RankNet,RankBoost,LambdaMart,Random Forest等模型.其中由微软发 ...
- 基于dubbo源码包通过Maven构建dubbo的详细步骤
通过Maven构建dubbo 既然可以下载得到源码以及发布包,那么为什么要去构建dubbo呢?,我们先来看下dubbo的主要模块: 我们不仅要使用dubbo的核心框架,还要使用它的一些服务,比如管理控 ...
- 基于u-boot源码的简单shell软件实现
一.概述 1.shell概念 Shell(命令解析器),它用于接收用户输入的命令,进行解析,然后调用相应的应用程序,为使用者提供了使用软件的界面. shell是操作系统最外面的一层.shell管理你与 ...
- drf 简介以及部分源码分析
目录 复习 drf框架 全称:django-rest framework 知识点 接口 restful接口规范 基于restful规范的原生Django接口 主路由:url.py api组件的子路由: ...
- 深入浅出Mybatis系列(二)---配置简介(mybatis源码篇)
上篇文章<深入浅出Mybatis系列(一)---Mybatis入门>, 写了一个Demo简单体现了一下Mybatis的流程.本次,将简单介绍一下Mybatis的配置文件: 上次例子中,我们 ...
随机推荐
- (转)SSIS_数据流转换(Union All&合并联接&合并)
Union All : 与sql语言 Union All 一样,不用排序,上下合并多个表.Union All转换替代合并转换:输入输出无需排序,合并超过两个表 合并联接 : 有左连接.内连接.完全连接 ...
- And Design:拓荒笔记——Form表单
And Design:拓荒笔记——Form表单 Form.create(options) Form.create()可以对包含Form表单的组件进行改造升级,会返回一个新的react组件. 经 For ...
- js动态创建Form表单并提交
javascript动态创建Form表单和表单项,然后提交表单请求,最后删除表单,代码片段如下(Firefox测试通过): var dlform = document.createElement('f ...
- Python笔记 #06# NumPy Basis & Subsetting NumPy Arrays
原始的 Python list 虽然很好用,但是不具备能够“整体”进行数学运算的性质,并且速度也不够快(按照视频上的说法),而 Numpy.array 恰好可以弥补这些缺陷. 初步应用就是“整体数学运 ...
- Javaworkers团队最终项目总结
Javaworkers团队最终项目总结 小组成员 20145205武钰 20145222黄亚奇 20145235李涛 20145103冯文华 团队项目总结 案例提出及工程用时 本次项目由十一到十六周共 ...
- POJ 3268 Silver Cow Party(最短路&Dijkstra)题解
题意:有n个地点,有m条路,问从所有点走到指定点x再走回去的最短路中的最长路径 思路:用Floyd超时的,这里用的Dijkstra. Dijkstra感觉和Prim和Kruskal的思路很像啊.我们把 ...
- 如何解决Nginx php 50x 错误
SEO反馈百度爬虫经常504,一般情况下是由nginx默认的fastcgi进程响应慢引起的,但也有其他情况,这里我总结了一些解决办法供大家参考. 方法/步骤 一般50x状态码问题分析: Nginx ...
- 【安装】Nginx安装
系统平台:CentOS release 6.5 (Final) 64位. 安装编译工具及库文件 yum -y install make zlib zlib-devel gcc-c++ libtool ...
- 利用ES6中的Array.find/ Array.findIndex来判断数组中已存在某个对象
前端开发过程中,我们会经常遇到这样的情景:比如选中某个指标obj,将其加入到数组checkedArr中({id: 1234, name: 'zzz', ...}),但是在将其选中之前要校验该指标是否已 ...
- Composite(组合)
意图: 将对象组合成树形结构以表示“部分-整体”的层次结构.C o m p o s i t e 使得用户对单个对象和组合对象的使用具有一致性. 适用性: 你想表示对象的部分-整体层次结构. 你希望用户 ...