转:机器学习 规则化和模型选择(Regularization and model selection)
规则化和模型选择(Regularization and model selection)
转:http://www.cnblogs.com/jerrylead/archive/2011/03/27/1996799.html
1 问题
模型选择问题:对于一个学习问题,可以有多种模型选择。比如要拟合一组样本点,可以使用线性回归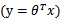 ,也可以用多项式回归
,也可以用多项式回归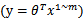 。那么使用哪种模型好呢(能够在偏差和方差之间达到平衡最优)?
。那么使用哪种模型好呢(能够在偏差和方差之间达到平衡最优)?
还有一类参数选择问题:如果我们想使用带权值的回归模型,那么怎么选择权重w公式里的参数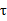 ?
?
形式化定义:假设可选的模型集合是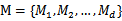 ,比如我们想分类,那么SVM、logistic回归、神经网络等模型都包含在M中。
,比如我们想分类,那么SVM、logistic回归、神经网络等模型都包含在M中。
2 交叉验证(Cross validation)
我们的第一个任务就是要从M中选择最好的模型。
假设训练集使用S来表示
如果我们想使用经验风险最小化来度量模型的好坏,那么我们可以这样来选择模型:
|
1、 使用S来训练每一个 2、 选择错误率最小的假设函数。 |
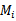 ,训练出参数后,也就可以得到假设函数
,训练出参数后,也就可以得到假设函数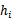 。(比如,线性模型中得到
。(比如,线性模型中得到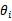 后,也就得到了假设函数
后,也就得到了假设函数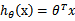 )
)遗憾的是这个算法不可行,比如我们需要拟合一些样本点,使用高阶的多项式回归肯定比线性回归错误率要小,偏差小,但是方差却很大,会过度拟合。因此,我们改进算法如下:
|
1、 从全部的训练数据S中随机选择70%的样例作为训练集 2、 在 3、 在 4、 选择具有最小经验错误 |
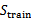 ,剩余的30%作为测试集
,剩余的30%作为测试集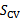 。
。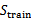 上训练每一个
上训练每一个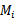 ,得到假设函数
,得到假设函数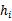 。
。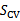 上测试每一个
上测试每一个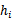 ,得到相应的经验错误
,得到相应的经验错误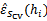 。
。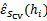 的
的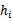 作为最佳模型。
作为最佳模型。这种方法称为hold-out cross validation或者称为简单交叉验证。
由于测试集是和训练集中是两个世界的,因此我们可以认为这里的经验错误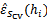 接近于泛化错误(generalization error)。这里测试集的比例一般占全部数据的1/4-1/3。30%是典型值。
接近于泛化错误(generalization error)。这里测试集的比例一般占全部数据的1/4-1/3。30%是典型值。
还可以对模型作改进,当选出最佳的模型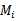 后,再在全部数据S上做一次训练,显然训练数据越多,模型参数越准确。
后,再在全部数据S上做一次训练,显然训练数据越多,模型参数越准确。
简单交叉验证方法的弱点在于得到的最佳模型是在70%的训练数据上选出来的,不代表在全部训练数据上是最佳的。还有当训练数据本来就很少时,再分出测试集后,训练数据就太少了。
我们对简单交叉验证方法再做一次改进,如下:
|
1、 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作{ 2、 每次从模型集合M中拿出来一个 { 3、 由于我们每次留下一个 4、 选出平均经验错误率最小的 |
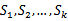 }。
}。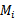 ,然后在训练子集中选择出k-1个
,然后在训练子集中选择出k-1个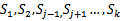 }(也就是每次只留下一个
}(也就是每次只留下一个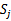 ),使用这k-1个子集训练
),使用这k-1个子集训练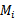 后,得到假设函数
后,得到假设函数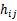 。最后使用剩下的一份
。最后使用剩下的一份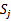 作测试,得到经验错误
作测试,得到经验错误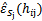 。
。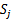 (j从1到k),因此会得到k个经验错误,那么对于一个
(j从1到k),因此会得到k个经验错误,那么对于一个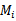 ,它的经验错误是这k个经验错误的平均。
,它的经验错误是这k个经验错误的平均。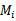 ,然后使用全部的S再做一次训练,得到最后的
,然后使用全部的S再做一次训练,得到最后的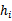 。
。这个方法称为k-fold cross validation(k-折叠交叉验证)。说白了,这个方法就是将简单交叉验证的测试集改为1/k,每个模型训练k次,测试k次,错误率为k次的平均。一般讲k取值为10。这样数据稀疏时基本上也能进行。显然,缺点就是训练和测试次数过多。
极端情况下,k可以取值为m,意味着每次留一个样例做测试,这个称为leave-one-out cross validation。
如果我们发明了一种新的学习模型或者算法,那么可以使用交叉验证来对模型进行评价。比如在NLP中,我们将训练集中分出一部分训练,一部分做测试。
3 特征选择(Feature selection)
特征选择严格来说也是模型选择中的一种。这里不去辨析他们的关系,重点说明问题。假设我们想对维度为n的样本点进行回归,然而,n可能大多以至于远远大于训练样例数m。但是我们感觉很多特征对于结果是无用的,想剔除n中的无用特征。n个特征就有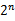 种去除情况(每个特征去或者保留),如果我们枚举这些情况,然后利用交叉验证逐一考察在该情况下模型的错误率,太不现实。因此需要一些启发式搜索方法。
种去除情况(每个特征去或者保留),如果我们枚举这些情况,然后利用交叉验证逐一考察在该情况下模型的错误率,太不现实。因此需要一些启发式搜索方法。
第一种,前向搜索:
|
1、 初始化特征集F为空。 2、 扫描i从1到n, 如果第i个特征不在F中,那么将特征i和F放在一起作为 在只使用 3、 从上步中得到的n个 如果F中的特征数达到了n或者预设定的阈值(如果有的话),那么输出整个搜索过程中最好的F,没达到转到2 |
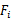 (即
(即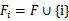 )
)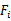 中特征的情况下,利用交叉验证来得到
中特征的情况下,利用交叉验证来得到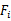 的错误率。
的错误率。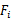 中选出错误率最小的
中选出错误率最小的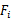 ,更新F为
,更新F为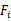 。
。前向搜索属于wrapper model feature selection。Wrapper这里指不断地使用不同的特征集来测试学习算法。前向搜索说白了就是每次增量地从剩余未选中的特征选出一个加入特征集中,待达到阈值或者n时,从所有的F中选出错误率最小的。
既然有增量加,那么也会有增量减,后者称为后向搜索。先将F设置为{1,2,..,n},然后每次删除一个特征,并评价,直到达到阈值或者为空,然后选择最佳的F。
这两种算法都可以工作,但是计算复杂度比较大。时间复杂度为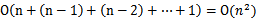 。
。
第二种,过滤特征选择(Filter feature selection):
过滤特征选择方法的想法是针对每一个特征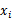 ,i从1到n,计算
,i从1到n,计算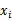 相对于类别标签
相对于类别标签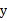 的信息量
的信息量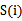 ,得到n个结果,然后将n个
,得到n个结果,然后将n个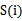 按照从大到小排名,输出前k个特征。显然,这样复杂度大大降低,为O(n)。
按照从大到小排名,输出前k个特征。显然,这样复杂度大大降低,为O(n)。
那么关键问题就是使用什么样的方法来度量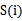 ,我们的目标是选取与y关联最密切的一些
,我们的目标是选取与y关联最密切的一些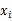 。而y和
。而y和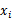 都是有概率分布的。因此我们想到使用互信息来度量
都是有概率分布的。因此我们想到使用互信息来度量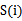 ,对于
,对于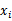 是离散值的情况更适用,不是离散值,将其转变为离散值,方法在第一篇《回归认识》中已经提到。
是离散值的情况更适用,不是离散值,将其转变为离散值,方法在第一篇《回归认识》中已经提到。
互信息(Mutual information)公式:
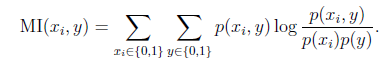
当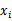 是0/1离散值的时候,这个公式如上。很容易推广到
是0/1离散值的时候,这个公式如上。很容易推广到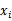 是多个离散值的情况。
是多个离散值的情况。
这里的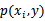 ,
,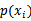 和
和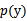 都是从训练集上得到的。
都是从训练集上得到的。
若问这个MI公式如何得来,请看它的KL距离(Kullback-Leibler)表述:

也就是说,MI衡量的是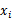 和y的独立性。如果它俩独立(
和y的独立性。如果它俩独立(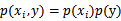 ),那么KL距离值为0,也就是说
),那么KL距离值为0,也就是说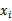 和y不相关了,可以去除
和y不相关了,可以去除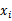 。相反,如果两者密切相关,那么MI值会很大。在对MI进行排名后,最后剩余的问题就是如何选择k值(前k个
。相反,如果两者密切相关,那么MI值会很大。在对MI进行排名后,最后剩余的问题就是如何选择k值(前k个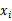 )。我们继续使用交叉验证的方法,将k从1扫描到n,取最大的F。不过这次复杂度是线性的了。比如,在使用朴素贝叶斯分类文本的时候,词表长度n很大。使用filter特征选择方法,能够增加分类器的精度。
)。我们继续使用交叉验证的方法,将k从1扫描到n,取最大的F。不过这次复杂度是线性的了。比如,在使用朴素贝叶斯分类文本的时候,词表长度n很大。使用filter特征选择方法,能够增加分类器的精度。
4 贝叶斯统计和规则化(Bayesian statistics and regularization)
题目有点绕,说白了就是要找更好的估计方法来减少过度拟合情况的发生。
回顾一下,线性回归中使用的估计方法是最小二乘法,logistic回归是条件概率的最大似然估计,朴素贝叶斯是联合概率的最大似然估计,SVM是二次规划。
以前我们使用的估计方法是最大似然估计(比如在logistic回归中使用的):
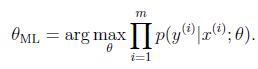
注意这里的最大似然估计与维基百科中的表述
http://zh.wikipedia.org/wiki/%E6%9C%80%E5%A4%A7%E5%90%8E%E9%AA%8C%E6%A6%82%E7%8E%87
有些出入,是因为维基百科只是将样本(观察数据)记为X,然后求P(X)的最大概率。然而,对于我们这里的样本而言,分为特征x和类标签y。我们需要具体计算P(X)。在判别模型(如logistic回归)中,我们看待P(X)=P(x,y)=P(y|x)P(x),而P(x)与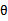 独立无关,因此最后的argmax P(X)由argmaxP(y|x)决定,也就是上式
独立无关,因此最后的argmax P(X)由argmaxP(y|x)决定,也就是上式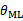 。严格来讲
。严格来讲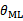 并不等于样本X的概率,只是P(X)决定于
并不等于样本X的概率,只是P(X)决定于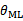 ,
,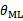 最大化时P(X)也最大化。在生成模型,如朴素贝叶斯中,我们看待P(X)=P(y)P(x|y),也就是在某个类标签y下出现特征x的概率与先验概率之积。而P(x|y)在x各个分量是条件独立情况下可以以概率相乘方式计算出,这里根本没有参数
最大化时P(X)也最大化。在生成模型,如朴素贝叶斯中,我们看待P(X)=P(y)P(x|y),也就是在某个类标签y下出现特征x的概率与先验概率之积。而P(x|y)在x各个分量是条件独立情况下可以以概率相乘方式计算出,这里根本没有参数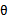 。因此最大似然估计直接估计P(x,y)即可,变成了联合分布概率。
。因此最大似然估计直接估计P(x,y)即可,变成了联合分布概率。
在该上式中,我们视参数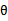 为未知的常数向量。我们的任务就是估计出未知的
为未知的常数向量。我们的任务就是估计出未知的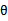 。
。
从大范围上说,最大似然估计看待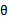 的视角称为频率学派(frequentist statistics),认为
的视角称为频率学派(frequentist statistics),认为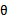 不是随机变量,只是一个未知的常量,因此我们没有把
不是随机变量,只是一个未知的常量,因此我们没有把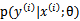 写成
写成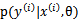 。
。
另一种视角称为贝叶斯学派(Bayesian),他们看待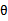 为随机变量,值未知。既然
为随机变量,值未知。既然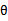 为随机变量,那么
为随机变量,那么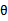 不同的值就有了不同的概率
不同的值就有了不同的概率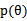 (称为先验概率),代表我们对特定的
(称为先验概率),代表我们对特定的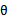 的相信度。我们将训练集表示成
的相信度。我们将训练集表示成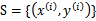 ,i从1到m。我们首先需要求出
,i从1到m。我们首先需要求出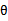 的后验概率:
的后验概率:
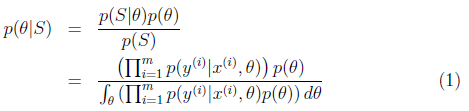
这个公式的推导其实比较蹊跷。第一步无可厚非,第二步中先看分子,分子中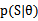 最完整的表达方式是
最完整的表达方式是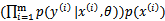 。由于在分母中也会出现
。由于在分母中也会出现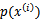 ,所以
,所以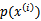 会被约掉。当然作者压根就没有考虑
会被约掉。当然作者压根就没有考虑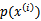 ,因为他看待P(S)的观点就是x->y,而不是(x,y)。再来看分母,分母写成这种形式后,意思是对所有的
,因为他看待P(S)的观点就是x->y,而不是(x,y)。再来看分母,分母写成这种形式后,意思是对所有的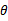 可能值做积分。括号里面的意思是
可能值做积分。括号里面的意思是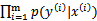 ,然后将其展开成分母的模样,从宏观上理解,就是在求每个样例的概率时,先以一定的概率确定
,然后将其展开成分母的模样,从宏观上理解,就是在求每个样例的概率时,先以一定的概率确定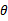 ,然后在
,然后在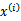 和
和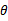 的作用下再确定
的作用下再确定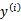 的概率。而如果让我推导这个公式,我可能会这样写分母
的概率。而如果让我推导这个公式,我可能会这样写分母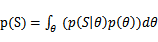 ,这样推导出的结果是
,这样推导出的结果是 。我不知道自己的想法对不对,分歧在于如何看待
。我不知道自己的想法对不对,分歧在于如何看待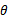 ,作者是为每个样例都重新选定
,作者是为每个样例都重新选定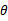 ,而我是对总体样本选择一个
,而我是对总体样本选择一个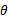 。
。
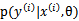 在不同的模型下计算方式不同。比如在贝叶斯logistic回归中,
在不同的模型下计算方式不同。比如在贝叶斯logistic回归中,
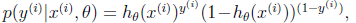
其中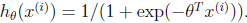 ,p的表现形式也就是伯努利分布了。
,p的表现形式也就是伯努利分布了。
在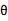 是随机变量的情况下,如果新来一个样例特征为x,那么为了预测y。我们可以使用下面的公式:
是随机变量的情况下,如果新来一个样例特征为x,那么为了预测y。我们可以使用下面的公式:
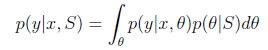
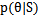 由前面的公式得到。假若我们要求期望值的话,那么套用求期望的公式即可:
由前面的公式得到。假若我们要求期望值的话,那么套用求期望的公式即可:
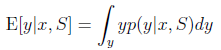
大多数时候我们只需求得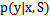 中最大的y即可(在y是离散值的情况下)。
中最大的y即可(在y是离散值的情况下)。
这次求解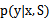 与之前的方式不同,以前是先求
与之前的方式不同,以前是先求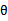 ,然后直接预测,这次是对所有可能的
,然后直接预测,这次是对所有可能的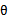 作积分。
作积分。
再总结一下两者的区别,最大似然估计没有将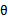 视作y的估计参数,认为
视作y的估计参数,认为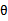 是一个常数,只是未知其值而已,比如我们经常使用常数c作为y=2x+c的后缀一样。但是
是一个常数,只是未知其值而已,比如我们经常使用常数c作为y=2x+c的后缀一样。但是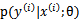 的计算公式中含有未知数
的计算公式中含有未知数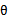 。所以再对极大似然估计求导后,可以求出
。所以再对极大似然估计求导后,可以求出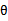 。
。
而贝叶斯估计将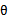 视为随机变量,
视为随机变量,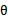 的值满足一定的分布,不是固定值,我们无法通过计算获得其值,只能在预测时计算积分。
的值满足一定的分布,不是固定值,我们无法通过计算获得其值,只能在预测时计算积分。
然而在上述贝叶斯估计方法中,虽然公式合理优美,但后验概率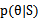 很难计算,看其公式知道计算分母时需要在所有的
很难计算,看其公式知道计算分母时需要在所有的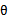 上作积分,然而对于一个高维的
上作积分,然而对于一个高维的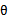 来说,枚举其所有的可能性太难了。
来说,枚举其所有的可能性太难了。
为了解决这个问题,我们需要改变思路。看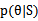 公式中的分母,分母其实就是P(S),而我们就是要让P(S)在各种参数的影响下能够最大(这里只有参数
公式中的分母,分母其实就是P(S),而我们就是要让P(S)在各种参数的影响下能够最大(这里只有参数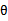 )。因此我们只需求出随机变量
)。因此我们只需求出随机变量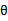 中最可能的取值,这样求出
中最可能的取值,这样求出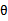 后,可将
后,可将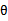 视为固定值,那么预测时就不用积分了,而是直接像最大似然估计中求出
视为固定值,那么预测时就不用积分了,而是直接像最大似然估计中求出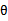 后一样进行预测,这样就变成了点估计。这种方法称为最大后验概率估计(Maximum a posteriori)方法
后一样进行预测,这样就变成了点估计。这种方法称为最大后验概率估计(Maximum a posteriori)方法
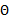 估计公式为
估计公式为
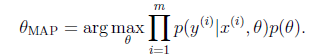
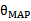 与
与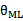 一样表示的是P(S),意义是在从随机变量分布中以一定概率
一样表示的是P(S),意义是在从随机变量分布中以一定概率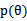 选定好
选定好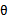 后,在给定样本特征
后,在给定样本特征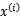 上
上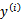 出现的概率积。
出现的概率积。
但是如果让我推导这个公式的时候,我会这么做,考虑后验概率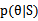 ,我们的目标是求出最有可能的
,我们的目标是求出最有可能的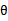 。而对于
。而对于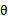 的所有值来说,分母是一样的,只有分子是不同的。因此
的所有值来说,分母是一样的,只有分子是不同的。因此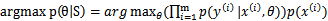 。也就是
。也就是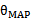 的推导式。但这个公式与上面的有些不同,同样还是看待每个样本一个
的推导式。但这个公式与上面的有些不同,同样还是看待每个样本一个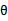 ,还是总体样本一个
,还是总体样本一个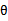 的问题。
的问题。
与最大似然估计对比发现,MAP只是将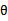 移进了条件概率中,并且多了一项
移进了条件概率中,并且多了一项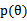 。一般情况下我们认为
。一般情况下我们认为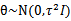 ,实际上,贝叶斯最大后验概率估计相对于最大似然估计来说更容易克服过度拟合问题。我想原因是这样的,过度拟合一般是极大化
,实际上,贝叶斯最大后验概率估计相对于最大似然估计来说更容易克服过度拟合问题。我想原因是这样的,过度拟合一般是极大化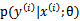 造成的。而在此公式中多了一个参数
造成的。而在此公式中多了一个参数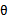 ,整个公式由两项组成,极大化
,整个公式由两项组成,极大化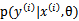 时,不代表此时
时,不代表此时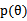 也能最大化。相反,
也能最大化。相反,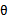 是多值高斯分布,极大化
是多值高斯分布,极大化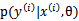 时,
时,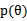 概率反而可能比较小。因此,要达到最大化
概率反而可能比较小。因此,要达到最大化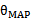 需要在两者之间达到平衡,也就靠近了偏差和方差线的交叉点。这个跟机器翻译里的噪声信道模型比较类似,由两个概率决定比有一个概率决定更靠谱。作者声称利用贝叶斯logistic回归(使用
需要在两者之间达到平衡,也就靠近了偏差和方差线的交叉点。这个跟机器翻译里的噪声信道模型比较类似,由两个概率决定比有一个概率决定更靠谱。作者声称利用贝叶斯logistic回归(使用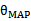 的logistic回归)应用于文本分类时,即使特征个数n远远大于样例个数m,也很有效。
的logistic回归)应用于文本分类时,即使特征个数n远远大于样例个数m,也很有效。
转:机器学习 规则化和模型选择(Regularization and model selection)的更多相关文章
- Bias vs. Variance(2)--regularization and bias/variance,如何选择合适的regularization parameter λ(model selection)
Linear regression with regularization 当我们的λ很大时,hθ(x)≍θ0,是一条直线,会出现underfit:当我们的λ很小时(=0时),即相当于没有做regul ...
- 机器学习 Regularization and model selection
Regularization and model selection 假设我们为了一个学习问题尝试从几个模型中选择一个合适的模型.例如,我们可能用一个多项式回归模型hθ(x)=g(θ0+θ1x+θ2x ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Regularization and model selection
Suppose we are trying select among several different models for a learning problem.For instance, we ...
- 机器学习-学习笔记(二) --> 模型评估与选择
目录 一.经验误差与过拟合 二.评估方法 模型评估方法 1. 留出法(hold-out) 2. 交叉验证法(cross validation) 3. 自助法(bootstrapping) 调参(par ...
- 机器学习中的范数规则化 L0、L1与L2范数 核范数与规则项参数选择
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的范数规则化之 L0、L1与L2范数、核范数与规则项参数选择
装载自:https://blog.csdn.net/u012467880/article/details/52852242 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理 ...
- paper 127:机器学习中的范数规则化之(二)核范数与规则项参数选择
机器学习中的范数规则化之(二)核范数与规则项参数选择 zouxy09@qq.com http://blog.csdn.net/zouxy09 上一篇博文,我们聊到了L0,L1和L2范数,这篇我们絮叨絮 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
随机推荐
- MySql Host is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts' 的解决方法
解决方法如下: 方法 1.在线修改提高允许的max_connection_errors数量: A. 登录Mysql数据库查看max_connection_errors: mysql>show ...
- C#:通过NuGet程序包下载CefSharp来加载谷歌浏览器
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 首先我讲明一下我要做的,公司有个C# wpf的项目需要我把一个开发好的网页嵌入到客户端当中,由于种种原因,我放 ...
- sqlserver 导出数据到Excel
1.导出非正式Excel EXEC master..xp_cmdshell 'bcp t.dbo.tcad out D:\MySelf\output\Temp.xls -c -q -S".& ...
- 存一下emacs配置
(global-set-key [f9] 'compile-file)(global-set-key [f10] 'gud-gdb)(global-set-key (kbd "C-z&quo ...
- Linux系统基础网络配置老鸟精华篇
对于linux高手看似简单的网络配置问题,也许要说出所以然来也并不轻松,因此仍然有太多的初学者徘徊在门外就不奇怪了,这里,老男孩老师花了一些时间总结了这个文档小结,也还不够完善,欢迎大家补充,交流.谢 ...
- Elasticsearch5.x版本中对Text类型进行聚合时提示illegal_argument_exception
Having this field in my mapping "answer": { "type": "text", "fiel ...
- 【MYSQL权限】数据库权限部署
背景:没有划分数据库权限,所有人共用一个账号 本人公司现有的数据库账号分布情况: 所有人用一个账号(包括程序里面访问数据库的的配置文件里面的账号),该账号除删库权限,其他权限大部分都有. 这样非数据库 ...
- 使用idea写ssm的时候提示源文件夹中的文件找不到
<context:property-placeholder location="classpath:db.properties"/>这一行idea提示找不到db.pro ...
- 初探C#
初探.NET底层原理 学习C#离不开.net平台,因为微软的开发平台真的是太强大了,它为每一个开发者都做了太多太多,但是我们不仅要知道怎么用,而且也应该知道其中的内部到底包含了什么.本篇文章不仅讲一些 ...
- hdu - 6276,2018CCPC湖南全国邀请赛A题,水题,二分
题意: 求H的最大值, H是指存在H篇论文,这H篇被引用的次数都大于等于H次. 思路:题意得, 最多只有N遍论文,所以H的最大值为N, 常识得知H的最小值为0. 所以H的答案在[0,N]之间,二分 ...