十、spark graphx的scala示例
简介
spark graphx官网:http://spark.apache.org/docs/latest/graphx-programming-guide.html#overview
spark graphx是基于spark core之上的一个图计算组件,graphx扩展了spark RDD,是spark对于图计算的一种抽象。
这里的图,不是“图画”的意思,是一种数据结构。这种数据结构由“点”和“线”组成,拿用户关系图来说,“点”描述的就是用户,“线”描述的就是这些用户之间的关系,所以由“点”和“线”组成了一张“用户关系图”,如图:
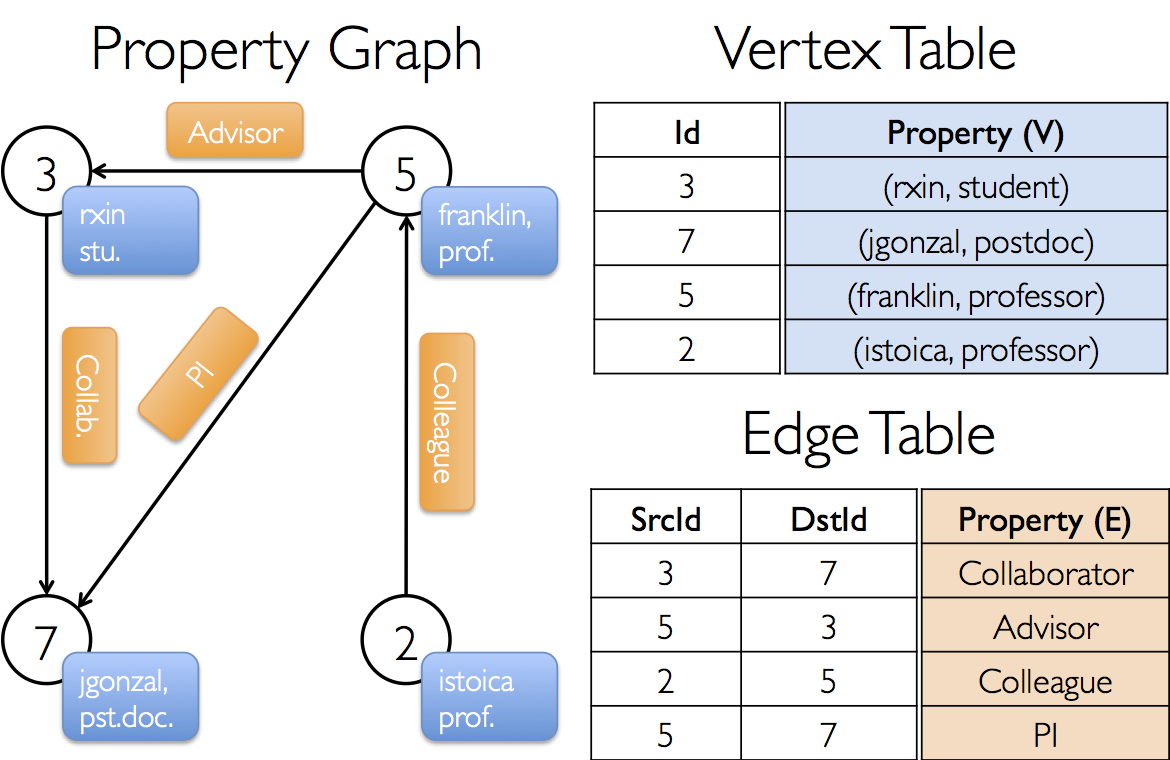
vertex table: 点,是由ID和Property属性组成的,ID必须是Long类型
edge table:线,是由起始ID,终点ID,property属性组成的,ID也必须为Long类型
property graph:图,由vertex和edge的数据,就可以构建出一张graph图数据结构
而spark graphx就是将这种数据结构创建出来,并提供简单易用的API来操作这个数据结构,如:查询、转换、关联、聚合等
代码示例
下面是scala语言的代码示例:
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description spark graphx demo
* @Author lay
* @Date 2018/12/09 20:19
*/
object SparkGraphxDemo {
var conf: SparkConf = _
var sc: SparkContext = _
var userData: Array[String] = Array("1 lay", "2 marry", "3 gary")
var relationData: Array[String] = Array("1 2 朋友", "1 3 同事", "2 3 姐弟")
var userRDD: RDD[(Long, String)] = _
var relationRDD: RDD[Edge[String]] = _
def init(): Unit = {
conf = new SparkConf().setAppName("spark graphx demo").setMaster("local")
sc = new SparkContext(conf)
}
def loadRdd(): Unit = {
userRDD = sc.parallelize(userData).map { x => val lines = x.split(" "); (lines(0).toLong, lines(1)) }
relationRDD = sc.parallelize(relationData).map { x => val lines = x.split(" "); Edge(lines(0).toLong, lines(1).toLong, lines(2)) }
}
def main(args: Array[String]): Unit = {
// 初始化
init()
// 加载rdd
loadRdd()
// 创建graph
var graph = Graph(userRDD, relationRDD)
// 找出和lay有关系的人
graph.triplets.filter(x => x.srcId == 1L).foreach{x => printf("%s是%s的%s", x.dstAttr, x.srcAttr, x.attr);println()}
}
}
我们将userRDD和relationRDD构建成了一个抽象结构Graph,然后过滤出了和lay有关系的人,并循环打印出结果,如下:
marry是lay的朋友
gary是lay的同事
十、spark graphx的scala示例的更多相关文章
- 十二、spark MLlib的scala示例
简介 spark MLlib官网:http://spark.apache.org/docs/latest/ml-guide.html mllib是spark core之上的算法库,包含了丰富的机器学习 ...
- 十一、spark SQL的scala示例
简介 spark SQL官网:http://spark.apache.org/docs/latest/sql-programming-guide.html sparkSQL是构建在sparkCore之 ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- 转载:Spark GraphX详解
1.GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求. ...
- Spark GraphX 的数据可视化
概述 Spark GraphX 本身并不提供可视化的支持, 我们通过第三方库 GraphStream 和 Breeze 来实现这一目标 详细 代码下载:http://www.demodashi.com ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 转载:四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍
四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍 时间 2016-07-22 16:57:00 炼数成金 相似文章 (5) 原文 http://www.dataguru.cn/ ...
- Spark GraphX从入门到实战
第1章 Spark GraphX 概述 1.1 什么是 Spark GraphX Spark GraphX 是一个分布式图处理框架,它是基于 Spark 平台提供对图计算和图挖掘简洁易用的而丰 ...
- Spark—GraphX编程指南
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
随机推荐
- git删除未监视的文件
新增的文件使用git status查看会提示Untracked files,如果想要删除Untracked files,可以使用如下命令: git clean -f # 删除Untracked fil ...
- 【OCP-052】052最新考试题库分析整理-第7题
7.Which is true about external tables? A) The ORACLE_DATAPUMP access driver can be used to write dat ...
- JAVA中Date类的使用
一. Date类 Date类对象的创建: 1.创建一个当前时间的Date对象 //创建一个代表系统当前日期的Date对象 Date d = new Date(); 2.创建一个我们指定的时间的Date ...
- LOJ#3085. 「GXOI / GZOI2019」特技飞行(KDtree+坐标系变换)
题面 传送门 前置芝士 请确定您会曼哈顿距离和切比雪夫距离之间的转换,以及\(KDtree\)对切比雪夫距离的操作 题解 我们发现\(AB\)和\(C\)没有任何关系,所以关于\(C\)可以直接暴力数 ...
- Vulnhub Billu_b0x
1.信息收集 1.1.获取IP地址: map scan report for 192.168.118.137 Host is up (0.00017s latency). Not shown: 998 ...
- redis cluster 的ERR max number of clients reached 问题排查
早上发现微服务连不上redis cluster了,看来下日志如下 [root@win-jrh378d7scu 7005]# bin/redis-cli -c -h 15.31.213.183 -p 7 ...
- linux安装scala环境
(安装scala的前提是已经安装好了jdk) 1.下载scala的安装包 wget https://scala-lang.org/files/archive/scala-2.11.0-M2.tgz 2 ...
- IOS----UIScrollerView的使用
刚刚遛狗回来,前段时间创建的这篇博客一直没有填充内容,今天把scrollerview正好整理一下. 1.scrollerview的主要作用:当界面显示不开要显示的内容,scrollerview提供了滑 ...
- mysqladmin常用用法
mysqladmin 工具的使用格式:mysqladmin [option] command [command option] command ...... 参数选项: -c number 自动运行次 ...
- idea 验证码
N757JE0KCT-eyJsaWNlbnNlSWQiOiJONzU3SkUwS0NUIiwibGljZW5zZWVOYW1lIjoid3UgYW5qdW4iLCJhc3NpZ25lZU5hbWUiO ...