Spark-RDD算子
一、Spark-RDD算子简介
RDD(Resilient Distributed DataSet)是分布式数据集。RDD是Spark最基本的数据的抽象。
scala中的集合。RDD相当于一个不可变、可分区、里面的元素可以并行计算的集合。 RDD特点:
具有数据流模型的特点
自动容错
位置感知调度
可伸缩性
RDD允许用户在执行多个查询时将工作集缓存在内存中,可以重用工作集,大大的提升了查询速度。 RDD类型分为:
1)Transformation
转换
2)Action
动作
二、RDD创建
RDD分为两种类型:
1)Transformation(lazy-》懒加载)
2)Action(触发任务)
例子:
scala> sc.textFile("/root/words.txt")
res8: org.apache.spark.rdd.RDD[String] = /root/words.txt MapPartitionsRDD[28] at textFile at <console>:25
scala> sc.textFile("/root/words.txt").flatMap(_.split(" "))
res9: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[31] at flatMap at <console>:25
scala> res8
res10: org.apache.spark.rdd.RDD[String] = /root/words.txt MapPartitionsRDD[28] at textFile at <console>:25
scala> res8.flatMap(_.split(" "))
res11: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[32] at flatMap at <console>:27
scala> res8.flatMap(_.split(" ")).map((_,1))
res12: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[34] at map at <console>:27
scala> res8.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res13: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[37] at reduceByKey at <console>:27
scala> res13.collect
res14: Array[(String, Int)] = Array((is,1), (love,2), (capital,1), (Beijing,2), (China,2), (I,2), (of,1), (the,1))
scala> val rdd1 = sc.textFile("/root/words.txt")
rdd1: org.apache.spark.rdd.RDD[String] = /root/words.txt MapPartitionsRDD[39] at textFile at <console>:24
scala> rdd1.count
res15: Long = 3
scala> val list = List(1,3,5,7)
list: List[Int] = List(1, 3, 5, 7)
scala> list.map(_ * 100)
res16: List[Int] = List(100, 300, 500, 700)
scala> val rdd1 = sc.parallelize(list)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[40] at parallelize at <console>:26
scala> rdd1.map(_ * 100)
res17: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[41] at map at <console>:29
scala> res17.collect
res18: Array[Int] = Array(100, 300, 500, 700)
scala> val rdd2 = sc.makeRDD(list)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[42] at makeRDD at <console>:26
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5),3)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[43] at parallelize at <console>:24
scala> val rdd2 = rdd1.map(_ * 1000)
rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[44] at map at <console>:26
scala> rdd2.collect
res19: Array[Int] = Array(1000, 2000, 3000, 4000, 5000)
三、常用Transformation
Transformation特点:
1)生成新的RDD
2)lazy懒加载 等待处理
3)并不会存储真正的数据,记录了转换关系
1、map(func)
2、flatMap(func)
3、sortby
4、reduceByKey
scala> sc.textFile("/root/words.txt")
res8: org.apache.spark.rdd.RDD[String] = /root/words.txt MapPartitionsRDD[28] at textFile at <console>:25
scala> res8.flatMap(_.split(" "))
res11: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[32] at flatMap at <console>:27
scala> res8.flatMap(_.split(" ")).map((_,1))
res12: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[34] at map at <console>:27
scala> res8.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res13: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[37] at reduceByKey at <console>:27
5、filter 过滤
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[48] at parallelize at <console>:24 scala> rdd1.filter(_ % 2 == 0)
res24: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[49] at filter at <console>:27 scala> res24.collect
res25: Array[Int] = Array(2, 4)
6、union 并集
scala> val rdd2 = sc.parallelize(List(1,2,3,4,5,6,7))
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[50] at parallelize at <console>:24 scala> rdd1.union(rdd2)
res26: org.apache.spark.rdd.RDD[Int] = UnionRDD[51] at union at <console>:29 scala> res26.collect
res27: Array[Int] = Array(1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 7) scala> rdd1 union rdd2
res28: org.apache.spark.rdd.RDD[Int] = UnionRDD[52] at union at <console>:29 scala> res28.collect
res29: Array[Int] = Array(1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 7)
7、groupByKey 分组
scala> val rdd3 = sc.parallelize(List(("Tom",18),("John",16),("Tom",20),("Mary",17),("John",23)))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[53] at parallelize at <console>:24
scala> rdd3.groupByKey
res30: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[54] at groupByKey at <console>:27
scala> res30.collect
res31: Array[(String, Iterable[Int])] = Array((John,CompactBuffer(16, 23)), (Tom,CompactBuffer(18, 20)), (Mary,CompactBuffer(17)))
8、intersection 交集
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[55] at parallelize at <console>:24 scala> val rdd2 = sc.parallelize(List(1,2,3,4,5,6,7))
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at parallelize at <console>:24 scala> rdd1.intersection(rdd2)
res33: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[62] at intersection at <console>:29 scala> res33.collect
res34: Array[Int] = Array(3, 4, 1, 5, 2)
9、join 关联
scala> val rdd1 = sc.parallelize(List(("Tom",18),("John",16),("Mary",21)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[65] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(List(("Tom",28),("John",26),("Cat",17)))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[66] at parallelize at <console>:24
scala> rdd1.join(rdd2)
res39: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[69] at join at <console>:29
scala> res39.collect
res40: Array[(String, (Int, Int))] = Array((John,(16,26)), (Tom,(18,28)))
10、leftOuterJoin 左连接
保留左侧RDD,右侧如果join上保留,没join上None
scala> val rdd1 = sc.parallelize(List(("Tom",18),("John",16),("Mary",21)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[65] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(List(("Tom",28),("John",26),("Cat",17)))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[66] at parallelize at <console>:24
scala> rdd1.leftOuterJoin(rdd2)
res41: org.apache.spark.rdd.RDD[(String, (Int, Option[Int]))] = MapPartitionsRDD[72] at leftOuterJoin at <console>:29
scala> res41.collect
res42: Array[(String, (Int, Option[Int]))] = Array((John,(16,Some(26))), (Tom,(18,Some(28))), (Mary,(21,None)))
11、rightOuterJoin 右连接
scala> val rdd1 = sc.parallelize(List(("Tom",18),("John",16),("Mary",21)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[65] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(List(("Tom",28),("John",26),("Cat",17)))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[66] at parallelize at <console>:24
scala> rdd1.rightOuterJoin(rdd2).collect
res43: Array[(String, (Option[Int], Int))] = Array((John,(Some(16),26)), (Tom,(Some(18),28)), (Cat,(None,17)))
12、cartesian 笛卡尔积
scala> val rdd1 = sc.parallelize(List("Tom","Mary"))
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[76] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(List("John","Joe"))
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[77] at parallelize at <console>:24
scala> rdd1.cartesian(rdd2)
res45: org.apache.spark.rdd.RDD[(String, String)] = CartesianRDD[78] at cartesian at <console>:29
scala> res45.collect
res46: Array[(String, String)] = Array((Tom,John), (Tom,Joe), (Mary,John), (Mary,Joe))
四、常用的Action
1、collect 收集
scala> val rdd1 = sc.parallelize(List(1,2,3,4))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> rdd1.collect
res0: Array[Int] = Array(1, 2, 3, 4)
2、saveAsTextFile(path) 存储文件
三份数据:5B 5B 600B
理想切分:5+5+600=610 610/3 = 203
5B一片
5B一片
203一片
203一片
203一片
1一片
scala> val rdd1 = sc.parallelize(List(1,2,3,4))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> rdd1.saveAsTextFile("/root/RDD1") //查看分区数
scala> rdd1.partitions.length
res3: Int = 4
3、count 计数
scala> val rdd1 = sc.parallelize(List(1,2,3,4))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> rdd1.count
res2: Long = 4
4、reduce 聚合
scala> val rdd2 = sc.parallelize(List(1,2,3,4),2)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at <console>:24 scala> rdd2.partitions.length
res4: Int = 2 scala> rdd2.reduce(_+_)
res5: Int = 10
5、countByKey() 根据key计数
scala> sc.parallelize(List(("Tom",18),("Tom",28),("John",14),("Mary",16)))
res9: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[4] at parallelize at <console>:25
scala> res9.count
res10: Long = 4
scala> res9.countByKey()
res11: scala.collection.Map[String,Long] = Map(Tom -> 2, Mary -> 1, John -> 1)
scala> res9.reduceByKey(_+_)
res12: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[7] at reduceByKey at <console>:27
scala> res9.reduceByKey(_+_).collect
res13: Array[(String, Int)] = Array((Tom,46), (Mary,16), (John,14))
6、take(n) 取出多少个元素
scala> val rdd1 = sc.parallelize(List(1,2,3,4))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> rdd1.take(2)
res15: Array[Int] = Array(1, 2) scala> val rdd3 = sc.parallelize(List(3,2,8,1,7))
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:24 scala> rdd3.take(2)
res17: Array[Int] = Array(3, 2)
7、first 返回RDD的第一个元素
scala> val rdd3 = sc.parallelize(List(3,2,8,1,7))
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:24 scala> rdd3.first
res18: Int = 3
8、takeOrdered(n) 取出多少个元素 默认正序
scala> val rdd3 = sc.parallelize(List(3,2,8,1,7))
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:24 scala> rdd3.takeOrdered(2)
res19: Array[Int] = Array(1, 2)
9、top(n) 倒序排序 取出元素
scala> val rdd3 = sc.parallelize(List(3,2,8,1,7))
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:24 scala> rdd3.top(2)
res20: Array[Int] = Array(8, 7)
五、spark高级算子
1、mapPartitionsWithIndex(func)
设置分区,并且查看每个分区中存放的元素
查看每个分区中元素
需要传递函数作为参数
val func = (index:Int,iter:Iterator[(Int)]) => {iter.toList.map(x => "partID:" + index + "," + "datas:" + x + "]").iterator}
scala> val rdd3 = sc.parallelize(List(1,2,3,4,5,6,7),2)
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:24 scala> val func = (index:Int,iter:Iterator[(Int)]) => {iter.toList.map(x => "partID:" + index + "," + "datas:" + x + "]").iterator}
func: (Int, Iterator[Int]) => Iterator[String] = <function2> scala> rdd3.mapPartitionsWithIndex(func)
res21: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[13] at mapPartitionsWithIndex at <console>:29 scala> rdd3.mapPartitionsWithIndex(func).collect
res22: Array[String] = Array(partID:0,datas:1], partID:0,datas:2], partID:0,datas:3], partID:1,datas:4], partID:1,datas:5], partID:1,datas:6], partID:1,datas:7])
2、aggregate
聚合,先局部后全局
max 取最大值
min 取最小值
scala> val rdd3 = sc.parallelize(List(1,2,3,4,5,6,7),2)
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:24 scala> rdd3.aggregate(0)(_+_,_+_)
res23: Int = 28 scala> rdd3.max
res24: Int = 7 scala> rdd3.min
res25: Int = 1 scala> val rdd3 = sc.parallelize(List(1,2,3,4,5,6,7),2)
rdd3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:24 scala> rdd3.aggregate(0)(math.max(_,_),_+_)
res29: Int = 10 scala> rdd3.aggregate(10)(math.max(_,_),_+_)
res31: Int = 30 // 1+2+3+20 + 4+5+6+7+20 + 20 = 88
scala> rdd3.aggregate(20)(_+_,_+_)
res32: Int = 88 scala> val rdd4 = sc.parallelize(List("a","b","c","d","e"),2)
rdd4: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[17] at parallelize at <console>:24 scala> rdd4.aggregate("|")(_+_,_+_)
res33: String = ||ab|cde scala> rdd4.aggregate("|")(_+_,_+_)
res34: String = ||cde|ab scala> val rdd5 = sc.parallelize(List("12","23","234","3456"),2)
rdd5: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[18] at parallelize at <console>:24 scala> rdd5.aggregate("")((x,y) => math.max(x.length,y.length).toString,(x,y) => x+y)
res35: String = 24 scala> rdd5.aggregate("")((x,y) => math.max(x.length,y.length).toString,(x,y) => x+y)
res36: String = 42 scala> rdd5.aggregate("")((x,y) => math.max(x.length,y.length).toString,(x,y) => x+y)
res37: String = 24 scala> rdd5.aggregate("")((x,y) => math.max(x.length,y.length).toString,(x,y) => x+y)
res38: String = 42 scala> val rdd6 = sc.parallelize(List("12","23","345",""),2)
rdd6: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[19] at parallelize at <console>:24 scala> rdd6.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res41: String = 01 scala> rdd6.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res42: String = 10 scala> rdd6.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res43: String = 01 scala> rdd6.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res48: String = 10 scala> val rdd7 = sc.parallelize(List("12","23","","456"),2)
rdd7: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> rdd7.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res1: String = 11 scala> ("").length
res2: Int = 0 scala> 0.length
<console>:24: error: value length is not a member of Int
0.length
^ scala> 0.toString.length
res5: Int = 1 scala> rdd7.aggregate("0")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res6: String = 011 scala> rdd7.aggregate("0")((x,y) => math.min(x.length,y.length).toString,(x,y) => x+y)
res7: String = 011
3、aggregateByKey
根据key聚合,先局部再全局
scala> val rdd8 = sc.parallelize(List(("cat",3),("cat",8),("mouse",6),("dog",8)))
rdd8: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> def func(index:Int,iter:Iterator[(String,Int)]):Iterator[String] = {iter.toList.map(x => "partID:" + index + "," + "values:" + x + "]").iterator}
func: (index: Int, iter: Iterator[(String, Int)])Iterator[String]
scala> rdd8.mapPartitionsWithIndex(func).collect
res34: Array[String] = Array(partID:0,values:(cat,3)], partID:1,values:(cat,8)], partID:2,values:(mouse,6)], partID:3,values:(dog,8)])
scala> rdd8.aggregateByKey(0)(_+_,_+_).collect
res35: Array[(String, Int)] = Array((dog,8), (mouse,6), (cat,11))
4、combineByKey
aggregateByKey和reduceByKey底层调用都是combineByKey
最底层的方法,先局部累加,再全局累加
scala> val rdd1 = sc.textFile("hdfs://192.168.146.111:9000/words.txt").flatMap(_.split("\t")).map((_,1)).reduceByKey(_+_).collect
rdd1: Array[(String, Int)] = Array((haha,1), (heihei,1), (hello,3), (Beijing,1), (world,1), (China,1))
scala> val rdd2 = sc.textFile("hdfs://192.168.146.111:9000/words.txt").flatMap(_.split("\t")).map((_,1)).combineByKey(x => x,(m:Int,n:Int) => (m+n),(a:Int,b:Int) => (a+b)).collect
rdd2: Array[(String, Int)] = Array((haha,1), (heihei,1), (hello,3), (Beijing,1), (world,1), (China,1))
5、coalesce
coalesce(4,true)
分区数4
是否shuffle
repartition的实现,已默认加了shuffle
scala> val rdd2 = sc.parallelize(List(1,2,3,4,5,6,7,8,9),2)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[15] at parallelize at <console>:24 scala> rdd2.partitions.length
res42: Int = 2 scala> val rdd3 = rdd2.coalesce(4,true)
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[19] at coalesce at <console>:26 scala> rdd3.partitions.length
res43: Int = 4 scala> val rdd4 = rdd3.repartition(5)
rdd4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[23] at repartition at <console>:28 scala> rdd4.partitions.length
res44: Int = 5
6、filterByRange
过滤出指定范围的元素
scala> val rdd6 = sc.parallelize(List(("a",3),("b",2),("d",5),("e",8)))
rdd6: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[24] at parallelize at <console>:24
scala> rdd6.filterByRange("b","d").collect
res45: Array[(String, Int)] = Array((b,2), (d,5))
scala> rdd6.filterByRange("b","e").collect
res46: Array[(String, Int)] = Array((b,2), (d,5), (e,8))
7、flatMapValues
切分出每个元素
scala> val rdd7 = sc.parallelize(List(("a","3 6"),("b","2 5"),("d","5 8")))
rdd7: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[27] at parallelize at <console>:24
scala> rdd7.flatMapValues(_.split(" ")).collect
res47: Array[(String, String)] = Array((a,3), (a,6), (b,2), (b,5), (d,5), (d,8))
8、foldByKey
需求:根据key来拼接字符串
scala> val rdd8 = sc.parallelize(List("Tom","John","Mary","Joe"),2)
rdd8: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[31] at parallelize at <console>:24
scala> val rdd9 = rdd8.map(x => (x.length,x))
rdd9: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[32] at map at <console>:26
scala> rdd9.collect
res48: Array[(Int, String)] = Array((3,Tom), (4,John), (4,Mary), (3,Joe))
scala> rdd9.foldByKey("")(_+_).collect
res49: Array[(Int, String)] = Array((4,JohnMary), (3,JoeTom))
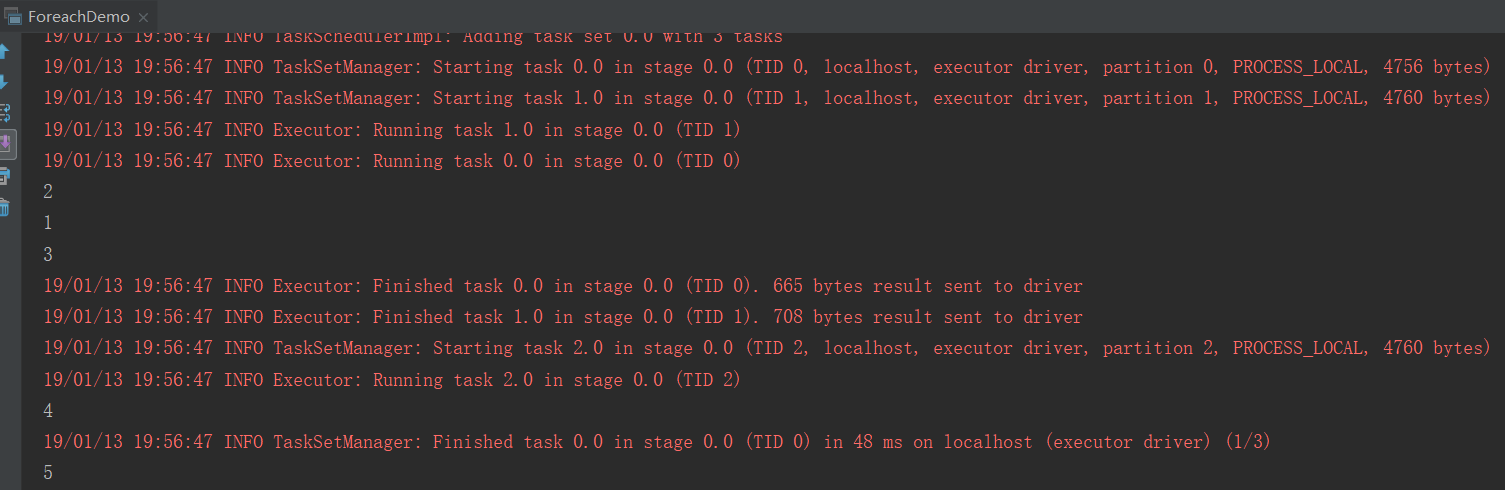
9、foreach
遍历元素
import org.apache.spark.{SparkConf, SparkContext}
object ForeachDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ForeachDemo").setMaster("local[2]")
val sc = new SparkContext(conf)
//创建rdd
val rdd1 = sc.parallelize(List(1,2,3,4,5),3)
rdd1.foreach(println(_))
sc.stop()
}
}
结果:
10、keyBy
以什么为key
keys values
拿到key 拿到value
scala> val rdd2 = sc.parallelize(List("Tom","John","Jack"),3)
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[37] at parallelize at <console>:24
scala> val rdd3 = rdd2.keyBy(_.length)
rdd3: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[38] at keyBy at <console>:26
scala> rdd3.collect
res60: Array[(Int, String)] = Array((3,Tom), (4,John), (4,Jack))
scala> rdd3.keys.collect
res61: Array[Int] = Array(3, 4, 4)
scala> rdd3.values.collect
res62: Array[String] = Array(Tom, John, Jack)
六、RDD并行化流程
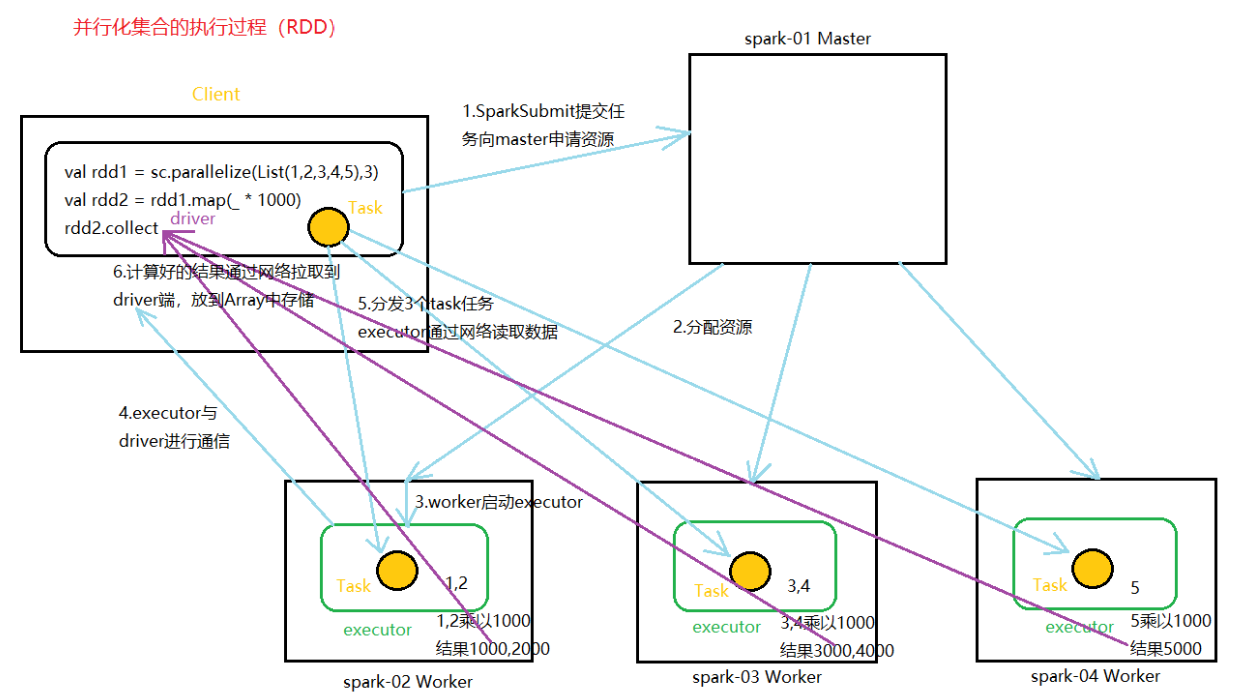
Spark-RDD算子的更多相关文章
- Spark RDD 算子总结
Spark算子总结 算子分类 Transformation(转换) 转换算子 含义 map(func) 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 filter(func) ...
- Spark RDD算子介绍
Spark学习笔记总结 01. Spark基础 1. 介绍 Spark可以用于批处理.交互式查询(Spark SQL).实时流处理(Spark Streaming).机器学习(Spark MLlib) ...
- Spark RDD概念学习系列之Spark的算子的分类(十一)
Spark的算子的分类 从大方向来说,Spark 算子大致可以分为以下两类: 1)Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理. Transformat ...
- Spark RDD概念学习系列之Spark的算子的作用(十四)
Spark的算子的作用 首先,关于spark算子的分类,详细见 http://www.cnblogs.com/zlslch/p/5723857.html 1.Transformation 变换/转换算 ...
- Spark操作算子本质-RDD的容错
Spark操作算子本质-RDD的容错spark模式1.standalone master 资源调度 worker2.yarn resourcemanager 资源调度 nodemanager在一个集群 ...
- spark教程(四)-SparkContext 和 RDD 算子
SparkContext SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点: 它表示连接到 spark,在进行 spark 操作之前必须先创建一个 Spark ...
- Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优 ...
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- Spark中普通集合与RDD算子的sortBy()有什么区别
分别观察一下集合与算子的sortBy()的参数列表 普通集合的sortBy() RDD算子的sortBy() 结论:普通集合的sortBy就没有false参数,也就是说只能默认的升序排. 如果需要对普 ...
- Spark RDD的依赖解读
在Spark中, RDD是有依赖关系的,这种依赖关系有两种类型 窄依赖(Narrow Dependency) 宽依赖(Wide Dependency) 以下图说明RDD的窄依赖和宽依赖 窄依赖 窄依赖 ...
随机推荐
- 【Java面试题】17 如何把一个逗号分隔的字符串转换为数组? 关于String类中split方法的使用,超级详细!!!
split 方法:将一个字符串分割为子字符串,然后将结果作为字符串数组返回. stringObj.split([separator],[limit])参数:stringObj 必选项.要被分解的 ...
- Linux美化终端
终端美化 不管你是Kali 还是 Centos 还是Ubuntu... 请先用你的安装器安装 zsh 这里以Ubuntu 为例: 终端美化使用的on-my-zsh 首先先介绍一下什么是zsh,zsh ...
- [转]JVM运行时内存结构
[转]http://www.cnblogs.com/dolphin0520/p/3783345.html 目录[-] 1.为什么会有年轻代 2.年轻代中的GC 3.一个对象的这一辈子 4.有关年轻代的 ...
- IPV6设置
C:\Windows\System32\drivers\etc 目录下修改hosts文件. 网上有更新的ipv6 hosts文件,复制下来~ 别人不断更新的: https://raw.githubus ...
- 基于nodejs的开源博客
https://github.com/hexojs/hexo https://hexo.io/zh-cn/docs/ markdown编辑器 http://pandao.github.io/edito ...
- 【java】java设计模式(5):原型模式(Prototype)
原型模式虽然是创建型的模式,但是与工程模式没有关系,从名字即可看出,该模式的思想就是将一个对象作为原型,对其进行复制.克隆,产生一个和原对象类似的新对象.本小结会通过对象的复制,进行讲解.在Java中 ...
- 更改VS2010的[默认开发语言]
1.菜单-->"工具"-->"导入导出设置".例如以下图: 2.选择"重置全部设置",例如以下图: 3.重置设置,例如以下图: ...
- mybatis由浅入深day01_4.9删除用户_4.10更新用户
4.9 删除用户 4.9.1 映射文件 4.9.2 代码: 控制台: 4.10 更新用户 4.10.1 映射文件 4.10.2 代码 控制台:
- redis客户端使用密码
./redis-cli -h 127.0.0.1 -p 6379 -a password
- EventBus 简单原理(一)
EventBus 1.根据文章最前面所讲的EventBus使用步骤,首先我们需要定义一个消息事件类: public class MessageEvent { private String messag ...