莫烦大大TensorFlow学习笔记(8)----优化器
一、TensorFlow中的优化器
- tf.train.GradientDescentOptimizer:梯度下降算法
- tf.train.AdadeltaOptimizer
- tf.train.AdagradOptimizer
- tf.train.MomentumOptimizer:动量梯度下降算法
- tf.train.AdamOptimizer:自适应矩估计优化算法
- tf.train.RMSPropOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizertf.train.RMSProOptimizer
(1)如果数据是稀疏的,使用自适应学习方法。
(2)RMSprop,Adadelta,Adam是非常相似的优化算法,Adam的bias-correction帮助其在最后优化期间梯度变稀疏的情况下略微战胜了RMSprop。整体来讲,Adam是最好的选择。
(3)很多论文中使用vanilla SGD without momentum。SGD通常能找到最小值,但是依赖健壮的初始化,并且容易陷入鞍点。因此,如果要获得更快的收敛速度和训练更深更复杂的神经网络,需要选择自适应学习方法。
https://blog.csdn.net/winycg/article/details/79363169
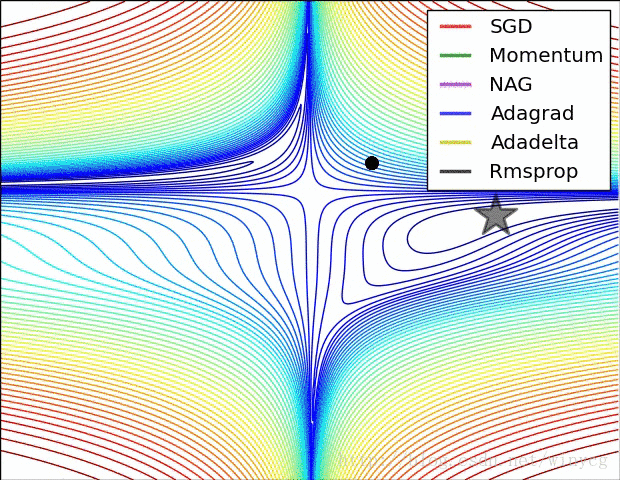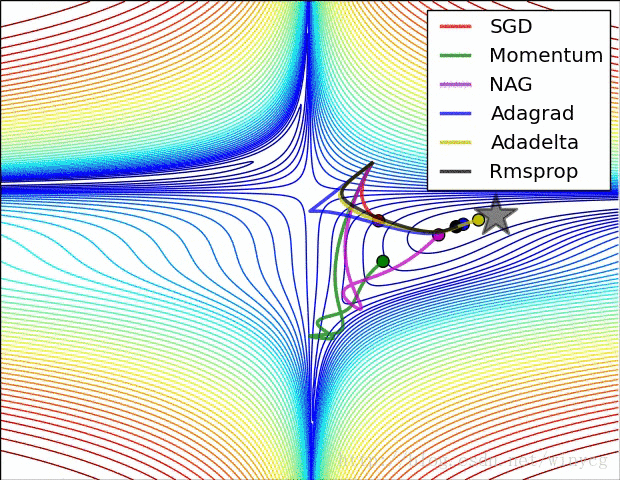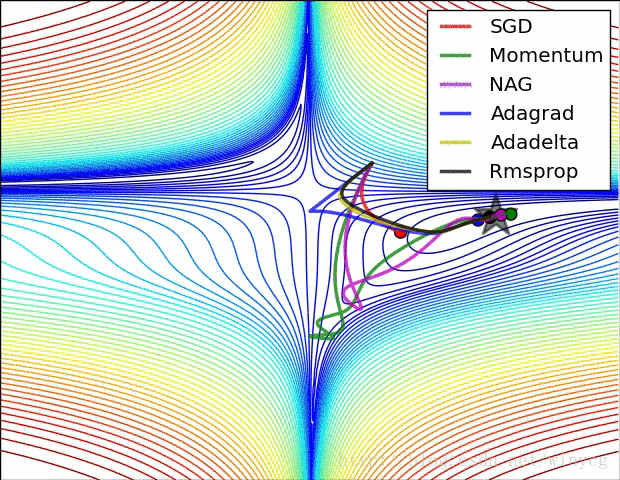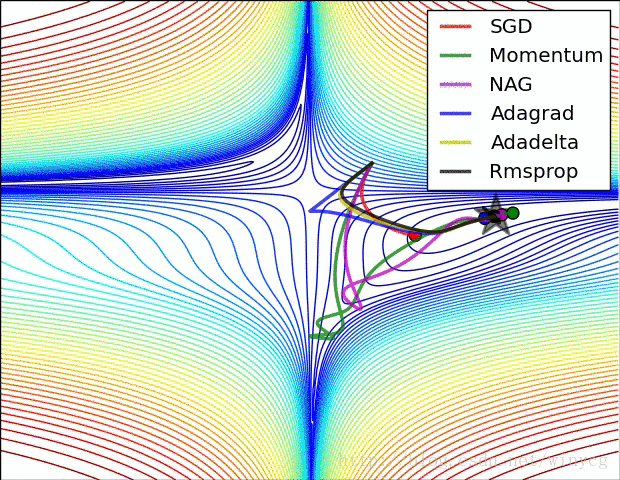
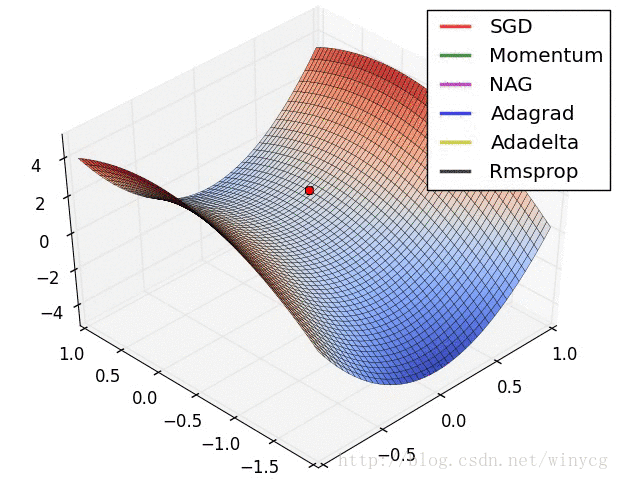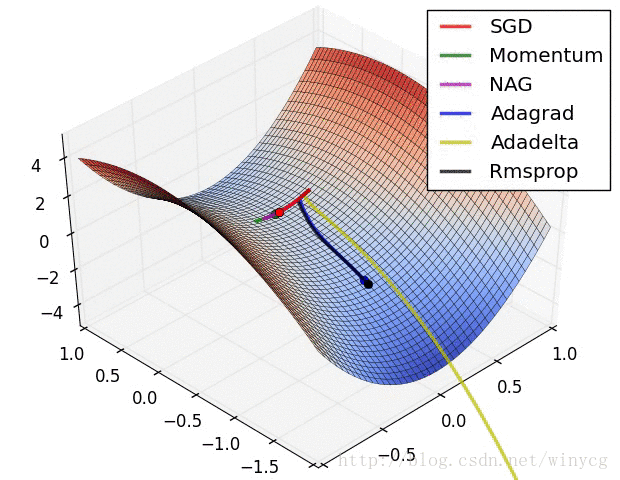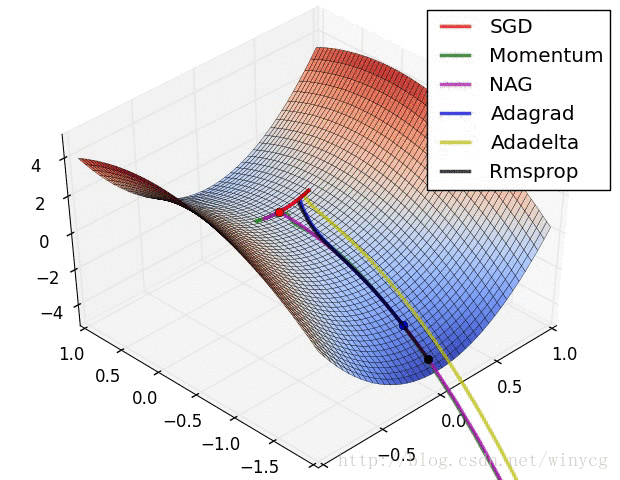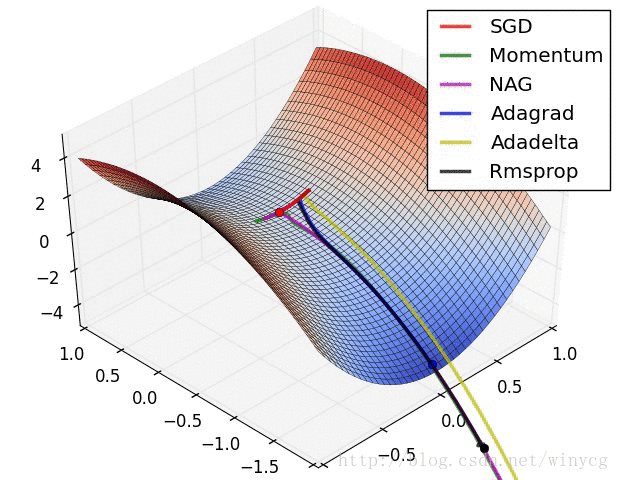
二、常用的种类:
1、tf.train.Optimizer:
2、tf.train.GradientDescentOptimizer:梯度下降
原理:
batch GD【全部样本,速度慢】
随机GD【随机一个样本,速度快,但局部最优】
mini-batch GD 【batch个样本,常在数据量较大时使用】
训练集样本数少【≤2000】:采用batchGD
训练集样本数多:采用mini-batch GD,batch大小一般为64-512. 训练时多尝试一下2的次方来找到最合适的batch大小。
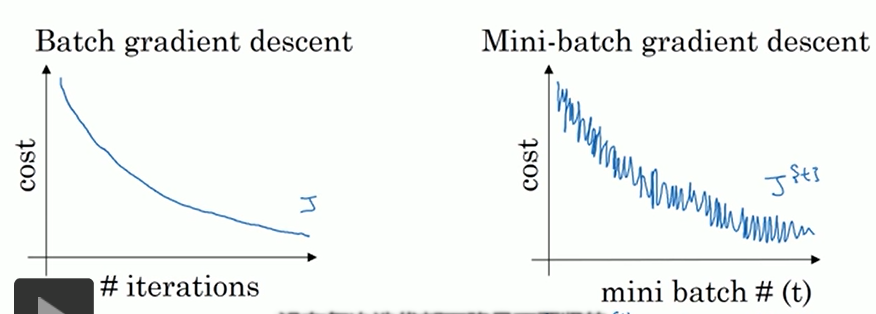
应用:
这个类是实现梯度下降算法的优化器。这个构造函数需要的一个学习率就行了。
构造函数:tf.train.GradientDescentOptimizer(0.001).minimize(loss,global_step=None,var_list=None,gate_gradients=GATE_OP,aggregation_method=None,colocate_gradients_with_ops=False,name=None,grad_loss=None)
__init__(
learning_rate,
use_locking=False,
name='GradientDescent'
)
learning_rate: (学习率)张量或者浮点数
use_locking: 为True时锁定更新
name: 梯度下降名称,默认为"GradientDescent".
3、tf.train.AdadeltaOptimizer:
实现了 Adadelta算法的优化器,可以算是下面的Adagrad算法改进版本。
构造函数: tf.train.AdadeltaOptimizer.init(learning_rate=0.001, rho=0.95, epsilon=1e-08, use_locking=False, name=’Adadelta’)
4、tf.train.AdagradOptimizer:
构造函数:tf.train.AdagradOptimizer.__init__(learning_rate, initial_accumulator_value=0.1, use_locking=False, name=’Adagrad’)
5、tf.train.MomentumOptimizer:
原理:


momentum表示要在多大程度上保留原来的更新方向,这个值在0-1之间,在训练开始时,由于梯度可能会很大,所以初始值一般选为0.5;当梯度不那么大时,改为0.9。 α是学习率,即当前batch的梯度多大程度上影响最终更新方向,跟普通的SGD含义相同。
应用:
构造函数:tf.train.MomentumOptimizer.__init__(learning_rate, momentum, use_locking=False, name=’Momentum’, use_nesterov=False)
__init__(
learning_rate,
momentum,
use_locking=False,
name='Momentum',
use_nesterov=False
)
learning_rate: (学习率)张量或者浮点数
momentum: (动量)张量或者浮点数
use_locking: 为True时锁定更新
name: 梯度下降名称,默认为 "Momentum".
use_nesterov: 为True时,使用 Nesterov Momentum.
6、tf.train.RMSPropOptimizer
目的和动量梯度一样,减小垂直方向,增大水平方向。W为水平方向,b为垂直方向。

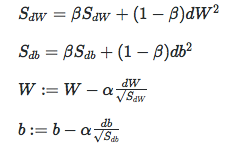
7、tf.train.AdamOptimizer:动量和RMSProp结合

应用:
__init__(
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
epsilon=1e-08,
use_locking=False,
name='Adam'
)
构造函数:tf.train.AdamOptimizer.__init__(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name=’Adam’)
learning_rate: (学习率)张量或者浮点数,需要调试
beta1: 浮点数或者常量张量 ,表示 The exponential decay rate for the 1st moment estimates.【推荐使用0.9】
beta2: 浮点数或者常量张量 ,表示 The exponential decay rate for the 2nd moment estimates.【推荐使用0.999】
epsilon: A small constant for numerical stability. This epsilon is "epsilon hat" in the Kingma and Ba paper (in the formula just before Section 2.1), not the epsilon in Algorithm 1 of the paper.
use_locking: 为True时锁定更新
name: 梯度下降名称,默认为 "Adam".
莫烦大大TensorFlow学习笔记(8)----优化器的更多相关文章
- 莫烦大大TensorFlow学习笔记(9)----可视化
一.Matplotlib[结果可视化] #import os #os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf i ...
- 莫烦python教程学习笔记——总结篇
一.机器学习算法分类: 监督学习:提供数据和数据分类标签.--分类.回归 非监督学习:只提供数据,不提供标签. 半监督学习 强化学习:尝试各种手段,自己去适应环境和规则.总结经验利用反馈,不断提高算法 ...
- 莫烦python教程学习笔记——保存模型、加载模型的两种方法
# View more python tutorials on my Youtube and Youku channel!!! # Youtube video tutorial: https://ww ...
- 莫烦python教程学习笔记——validation_curve用于调参
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——learn_curve曲线用于过拟合问题
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——利用交叉验证计算模型得分、选择模型参数
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——数据预处理之normalization
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 莫烦python教程学习笔记——线性回归模型的属性
#调用查看线性回归的几个属性 # Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg # ...
- 莫烦python教程学习笔记——使用波士顿数据集、生成用于回归的数据集
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
随机推荐
- 0123简单配置LNMP
简单配置LNMP不怕出现错误,就怕错误不知道出现在哪里?看日值tail -f /var/log/message -- 系统整个的日志tail -f /var/log/nginx/error.log - ...
- JAVA数据库连接的另一种实现及简单的数据插入及显示
教材是JDK8的,家里也可以正规的测试JDK8, 但公司电脑是JDK6的,所以代码要相应的变动一下下,以适应老的TRY语句. Message.java package cc.openhome; imp ...
- 第五节、矩阵分解之LU分解
一.A的LU分解:A=LU 我们之前探讨过矩阵消元,当时我们通过EA=U将A消元得到了U,这一节,我们从另一个角度分析A与U的关系 假设A是非奇异矩阵且消元过程中没有行交换,我们便可以将矩阵消元的EA ...
- [bzoj3062][Usaco13Feb]Taxi_贪心
Taxi bzoj-3062 Usaco13Feb 题目大意:有n个奶牛想坐出租车.第i头奶牛在起点a[i]等候,想坐出租车到b[i].Bessie从0出车,车上只能坐一头奶牛.她必须完成所有奶牛的要 ...
- codevs——T1219 骑士游历
http://codevs.cn/problem/1219/ 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Desc ...
- POJ 1106
先判断是否在圆内,然后用叉积判断是否在180度内.枚举判断就可以了... 感觉是数据弱了.. #include <iostream> #include <cstdio> #in ...
- DDos攻击,使用深度学习中 栈式自编码的算法
转自:http://www.airghc.top/2016/11/10/Dection-DDos/ 最近研究了一篇论文,关于检测DDos攻击,使用了深度学习中 栈式自编码的算法,现在简要介绍一下内容论 ...
- centos 80端口占用
netstat -lnp|grep 80 kill -9 1777 #杀掉编号为1777的进程(请根据实际情况输入)service httpd start #启动apache
- linux 标准输出和后台运行
一.后台运行程序 至需要在命令后面加上一个 & 即可 # command & 例如: python test.py & 二.标准输出.标准错误输出 # command > ...
- Ajax请求成功但是一直进入error的原因
1.在1.3版本的jQuery以后,严格要求了json格式,如果返回的值不是json格式,他就会执行error函数. 所以如果想让他走success函数的话,还是在后台把数据格式化成json格式吧. ...