移动端数据爬取和Scrapy框架
移动端数据爬取
注:抓包工具:青花瓷
1.配置fiddler
2.移动端安装fiddler证书
3.配置手机的网络
- 给手机设置一个代理IP:port
a. Fiddler设置
打开Fiddler软件,打开工具的设置。(Fiddler软件菜单栏:Tools->Options)
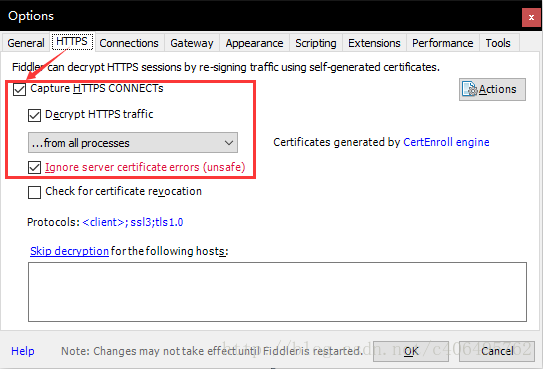
在HTTPS中设置如下:
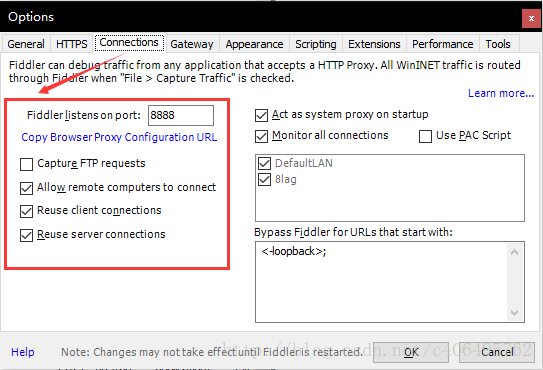
在Connections中设置如下,这里使用默认8888端口,当然也可以自己更改,但是注意不要与已经使用的端口冲突:
Allow remote computers to connect:允许别的机器把请求发送到fiddler上来
b. 安全证书下载
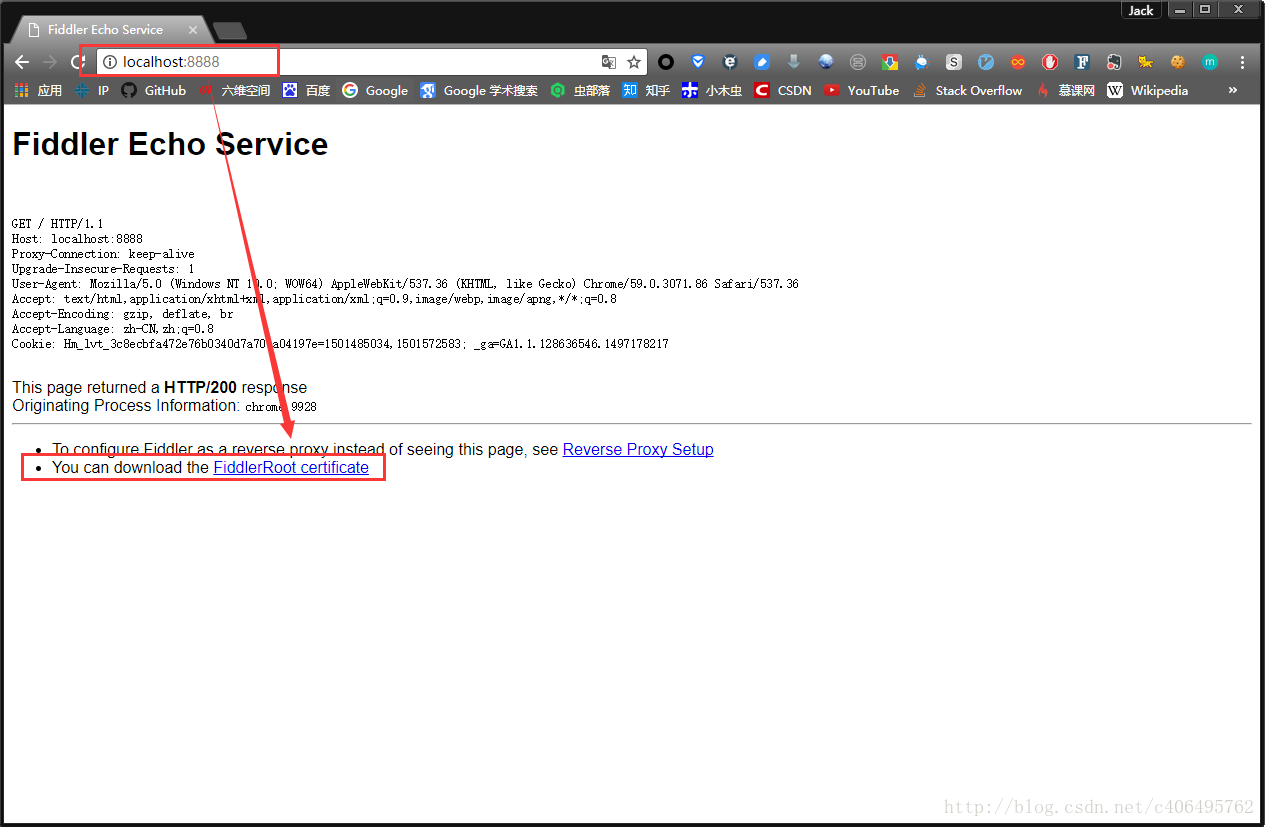
在电脑浏览器中输入地址:http://localhost:8888/,点击FiddlerRoot certificate,下载安全证书:
也可以

c. 安全证书安装(证书一定要安装且信任)
证书是需要在手机上进行安装的,这样在电脑Fiddler软件抓包的时候,手机使用电脑的网卡上网才不会报错。
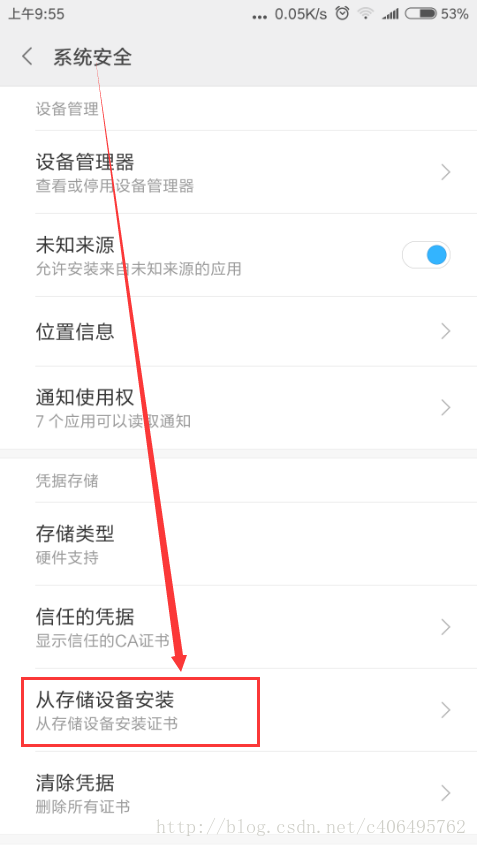
Android手机安装:把证书放入手机的内置或外置存储卡上,然后通过手机的"系统安全-》从存储设备安装"菜单安装证书。
然后找到拷贝的FiddlerRoot.cer进行安装即可。安装好之后,可以在信任的凭证中找到我们已经安装好的安全证书。
苹果手机安装:
- 保证手机网络和fiddler所在机器网络是同一个网段下的
- 在safari中访问http://fiddle机器ip:fiddler端口,进行证书下载。然后进行安装证书操作。
- 在手机中的设置-》通用-》关于本机-》证书信任设置-》开启fiddler证书信任
d. 局域网设置
想要使用Fiddler进行手机抓包,首先要确保手机和电脑的网络在一个内网中,可以使用让电脑和手机都连接同一个路由器。当然,也可以让电脑开放WIFI热点,手机连入。这里,我使用的方法是,让手机和电脑同时连入一个路由器中。最后,让手机使用电脑的代理IP进行上网。 在手机上,点击连接的WIFI进行网络修改,添加代理。进行手动设置,ip和端口号都是fiddler机器的ip和fiddler上设置的端口号。
e. Fiddler手机抓包测试
上述步骤都设置完成之后,用手机浏览器打开百度首页,我们就可以顺利抓包了
scrapy框架
(1)环境安装
linux:
pip install scrapy
windows:
有whell才能下载下载twisted框架: pips install whell
下载twisted框架(处理并发相关操作) : http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
进入下载目录,执行: pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
pip3 install pywin32
pip3 install scrapy
(2)新建一个项目
创建一个工程
scrapy startproject 工程名称
此时生成的工程目录


创建一个爬虫文件
注:要保证配置文件创建在当前工程目录下
cd firstblood #在工程目录下创建爬虫文件 会在apiders中出现
scrapy genspider first www.xxx.com #first代表爬虫文件的名称,www.xxx.com代表起始url
在first.py爬虫文件中


执行爬虫文件
scrapy crawl first
scrapy crawl first --nolog (不打印日志)
robots反爬机制的处理
被robots反爬机制拦截的反应


处理方式(在配置文件中修改此条为False)


User-Agent伪装反爬机制的处理
处理方式(在配置文件中修改此条)


数据解析
xpath表达式的使用以及获取Selector对象中的date中的值的两种方式
class FirstSpider(scrapy.Spider):
name = 'first'
# allowed_domains = ['www.xxx.com'] #在该文件中,只能爬取这个域名之下的url,通常注释掉这一句
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
div_list=response.xpath('//div[@id="content-left"]/div')
for div in div_list:
#得到的div是Selector类型的
title=div.xpath('./div/a[2]/h2/text()')[0].extract() #将Selector对象中的date中的值
title = div.xpath('./div/a[2]/h2/text()').extract_first() #直接得到列表中第0个元素
print(title)
持久化存储
1.基于终端指令的持久化存储(只能将path的返回值存到本地的文本中)
可以通过将终端指令的形式将parse方法的返回值中存储的数据进行本地磁盘的持久化存储
class FirstSpider(scrapy.Spider):
name = 'first'
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response)
div_list=response.xpath('//div[@id="content-left"]/div')
all_data=[]
dic={}
for div in div_list:
#得到的div是Selector类型的
content=div.xpath('./a/div/span/text()').extract_first()
title=div.xpath('./div/a[2]/h2/text()').extract_first()
dic={
"title":title,
"content":content
}
all_data.append(dic)
print(all_data)
return all_data
终端指令
scrapy crawl first -o qiubai.csv
注:限制文件存储的格式,只能是json,jsonlines,jl,csv,xml,marshal,pickle格式的文件
2.基于管道的持久化存储
新建工程
scrapy startproject bosspro
cd bosspro
创建爬虫文件
scrapy genspider boss www.baidu.com
修改两种反爬机制

爬取Boss直聘的数据
class BossSpider(scrapy.Spider):
name = 'boss'
#allowed_domains = ['www.baidu.com']
start_urls = ['https://www.zhipin.com/job_detail/?query=python爬虫&scity=101010100&industry=&position=']
def parse(self, response):
li_list=response.xpath('//*[@id="main"]/div/div[3]/ul/li')
for li in li_list:
name=li.xpath('./div/div/h3/a/div/text()').extract_first()
salary=li.xpath('./div/div/h3/a/span/text()').extract_first()
管道的使用
在items.py中
import scrapy
class BossproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 1.将爬虫文件中每一个要提交给管道的数据封装成这个类下的一个属性
salary = scrapy.Field(
在boss.py爬虫文件中
import scrapy
from bosspro.items import BossproItem #2.导入item中的类
class BossSpider(scrapy.Spider):
name = 'boss'
#allowed_domains = ['www.baidu.com']
start_urls = ['https://www.zhipin.com/job_detail/?query=python爬虫&scity=101010100&industry=&position=']
def parse(self, response):
li_list=response.xpath('//*[@id="main"]/div/div[3]/ul/li')
for li in li_list:
name=li.xpath('./div/div/h3/a/div/text()').extract_first()
salary=li.xpath('./div/div/h3/a/span/text()').extract_first()
item=BossproItem() #3.实例化一盒item对象
item['name']=name #4.将解析到的数据存储到item对象中
item['salary']=salary
yield item #5.将item对象提交给管道
在pipelines.py管道文件中
#此文件需要接受爬虫文件提交过来的数据,并对数据进行持久化存储(IO)
class BossproPipeline(object):
#爬虫文件每提交一次,该方法执行一次
def process_item(self, item, spider):
print(item['name'])
print(item['salary']) #6.在process_item函数中进行数据的持久化存储
return item
在settings.py配置文件中
#7.在配置文件中开启管道
ITEM_PIPELINES = {
'bosspro.pipelines.BossproPipeline': 300, #300表示的是优先级,数值越小优先级越高
}
#pipelines中声明的管道类都要在此处开启
数据的持久化存储(本地,mysql,redis)
#将数据保存到本地
class BossproPipeline(object):
f=None
# open_sipder只会在开始爬虫时执行一次
def open_spider(self,spider): #此处的spider是BossSpider类的一个实例对象
print("开始爬虫!")
self.f= open('./job.txt','w',encoding='utf-8')
def process_item(self, item, spider):
self.f.write(item['name']+':'+item['salary']+"\n")
return item #如果有其他的管道,process_item函数一定要有返回值
#close_sipder只会在结束爬虫时执行一次
def close_spider(self,spider):
print("结束爬虫!")
self.f.close()
#将数据保存到mysql
import pymysql
class Bosspro_mysql_Pipeline(object):
conn=None #连接对象
cursor=None #游标对象
def open_spider(self,spider):
self.conn=pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='pachong')
print("开始爬虫")
print(self.conn)
def process_item(self, item, spider):
self.cursor=self.conn.cursor()
sql='insert into boss values("%s","%s")' % (item["name"],item["salary"])
try:
self.cursor.execute(sql)
self.conn.commit()
print(sql)
except Exception as e:
print(e)
self.conn.rollback() #事务回滚
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
print('结束爬虫')
#将数据保存到redis
from redis import Redis
class Bosspro_redis_Pipeline(object):
conn=None
def open_spider(self,spider):
self.conn=Redis(host='127.0.0.1',port=6380)
print("开始爬虫了")
print(self.conn)
def process_item(self, item, spider):
dic={
"name":item["name"],
"title":item["salary"]
}
self.conn.lpush('Info',dic)
def close_spider(self,spider):
print('结束爬虫了')
注:开启线程
在配置文件中修改CONCURRENT_REQUESTS = 32即可
移动端数据爬取和Scrapy框架的更多相关文章
- 小爬爬5:重点回顾&&移动端数据爬取1
1. ()什么是selenium - 基于浏览器自动化的一个模块 ()在爬虫中为什么使用selenium及其和爬虫之间的关联 - 可以便捷的获取动态加载的数据 - 实现模拟登陆 ()列举常见的sele ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- 移动端数据爬取(fidlde)
一.什么是Fiddler? 1 什么是Fiddler? Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 . 它能够记录客户端和服务器之间的所有 HTTP请求, ...
- Scrapy 框架 CrawlSpider 全站数据爬取
CrawlSpider 全站数据爬取 创建 crawlSpider 爬虫文件 scrapy genspider -t crawl chouti www.xxx.com import scrapy fr ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- requests模块session处理cookie 与基于线程池的数据爬取
引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/ ...
- Python3,x:如何进行手机APP的数据爬取
Python3,x:如何进行手机APP的数据爬取 一.简介 平时我们的爬虫多是针对网页的,但是随着手机端APP应用数量的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
- 基于CrawlSpider全栈数据爬取
CrawlSpider就是爬虫类Spider的一个子类 使用流程 创建一个基于CrawlSpider的一个爬虫文件 :scrapy genspider -t crawl spider_name www ...
随机推荐
- 华为如何实现基于Git的跨地域协同开发
跨地域开发的需求其实由来已久,在IT/互联网发展的早期就已存在,只不过限于当时网络环境的因素,无法在线上有效的完成协同工作,所以没法实际开展.而随着近十年网络的快速发展,跨地域协同开发线变得可能而且越 ...
- Cython 的学习
开发效率极高的 Python 一直因执行效率过低为人所诟病,Cython 由此诞生,特性介于 Python 和 C 语言之间. Cython 学习 1. Cython 是什么? 它是一个用来快速生成 ...
- 10g RAC 采用service达到taf
service由于oracle数据库中的一个关键概念,利用得当,可以轻松地管理数据库,提高数据库的工作效率. 经service.oracle可以实现server side taf,简单化client ...
- Java中,对多线程访问同一变量(并发访问)的认识
在Java中,如果启动多个线程对同一个对象或者变量时候,在没有安全保护前提下有可能会抛出并异常 java.util.ConcurrentModificationException 当方法检测到对象的并 ...
- Android中SQLite数据库操作(1)——使用SQL语句操作SQLite数据库
下面是最原始的方法,用SQL语句操作数据库.后面的"Android中SQLite数据库操作(2)--SQLiteOpenHelper类"将介绍一种常用的android封装操作SQL ...
- DDD实战1
1.创建空白解决方案 2.创建Infrastructure解决方案文件夹 3.在Infrastructure解决方案文件夹下面 添加一个新的项目 这个项目是 .net core的类库项目,取名Util ...
- 零元学Expression Design 4 - Chapter 3 看小光被包围了!!如何活用「Text On Path」设计效果
原文:零元学Expression Design 4 - Chapter 3 看小光被包围了!!如何活用「Text On Path」设计效果 本章将教大家如何活用「Text On Path」,做出文绕图 ...
- 微信小程序之商品属性分类
所提及的购物数量的加减,现在说说商品属性值联动选择. 为了让同学们有个直观的了解,到电商网截了一个图片,就是红圈所示的部分 现在就为大家介绍这个小组件,在小程序中,该如何去写 下图为本项目的图: wx ...
- go语言学习之路(一)
Go 语言简介 Go 是一个开源的编程语言,它能让构造简单.可靠且高效的软件变得容易. Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发, ...
- VisualSVN-6.0.1Patch just for VS2017补丁原创发布
VisualSVN-6.0.1Patch_justforVS2017补丁原创发布 一切尽在发布中.