Java集合(一)HashMap
HashMap
特点: HashMap的key和value都允许为空,无序的,且非线程安全的
数据结构: HashMap底层是一个数组,数组的每一项又都是链表,即数据和链表的结合体。当新建一个HashMap对象时,就会初始化一个数组
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
...
}
HashMap的存储单元Entry里面存放键值,且它持有指向下一个元素的引用,从而构成了链表
HashMap的存储
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
put()方法的步骤:
- 当key为空时,空的key会默认放在第零位的数组上
- 拿到key的hash值,再调用hash()方法重新计算出一个hash值。根据JDK源码,调用hash()方法的目的是为了打乱原有的hash值,防止糟糕的hash算法
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
3. 根据hash值对Entry数组取模获得到存放数据的位置。取模操作的正确性依赖于数组的长度必须是2的N次幂。所有,在HashMap的构造函数中,如果指定HashMap初始大小为initialCapacity,如果initialCapacity不是2的N次幂,HashMap会算出大于initialCapacity的最小2的N次幂,作为Entry数组的初始大小
static int indexFor(int h, int length) {
return h & (length-1);
}
4. 判断是否存在相同的key,存在则将新的value存入,旧的返回,细节是先比较hash值,相同则再比较key,从而提高效率
5. modCount++是用于fail-fast机制,每次修改HashMap的数据结构都会自增一次
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
6. 调用addEntry()方法。先设置一个变量e指向当前数组下标对象,再将键值放入新建的Entry对象里并将该对象赋给数组下标对象,且对象指向的下一个元素为旧的对象e。简单来说就是新建一个对象,将键值存入里面,并且将这个对象放在数组索引位置的第一个(即链头),它的下一个元素指向以前的第一个。
之后判断是否需要扩容,threshold为是否扩容的最大元素数目,当前HashMap的大小大于或等于该值时,就会进行扩容
threshold = (int)(capacity * loadFactor);
HashMap的读取
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
简单来说就是通过key获取hash值,通过hash值获取数组下标,找到数组位置,将hash和key去比较是否相同
HashMap的删除
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
- 通过key获取hash值,通过hash值获取数组下标,得到数组位置
- 遍历链表,找到匹配的。当删除的是链头,将数组下标指向下一个,如果删除的不是链头,则将前一个对象的next指向被删除的后一个
Fail-Fast机制
HashMap是线程不安全的,所以当使用迭代器的过程中,有其他线程修改了map,则会抛出ConcurrentModificationException,这就是fail-fast策略
modCount为修改次数,当HashMap内容修改都将增加这个值,在迭代器迭初始化过程中会将这个值赋给expectedModCount,在迭代的过程中判断这两个值是否相等,不相等则表示被其他线程修改了Map
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
注意: modCount使用volatile修饰,保证线程之间修改的可见性
HashMap(jdk1.8)
jdk1.8版本的HashMap底层是由数组,链表和红黑树实现的。底层的内部类由Entry变成了Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
......
}
hash()方法也变了,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低位都参与到Hash的计算中,同时不会有太大的开销。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
put()方法
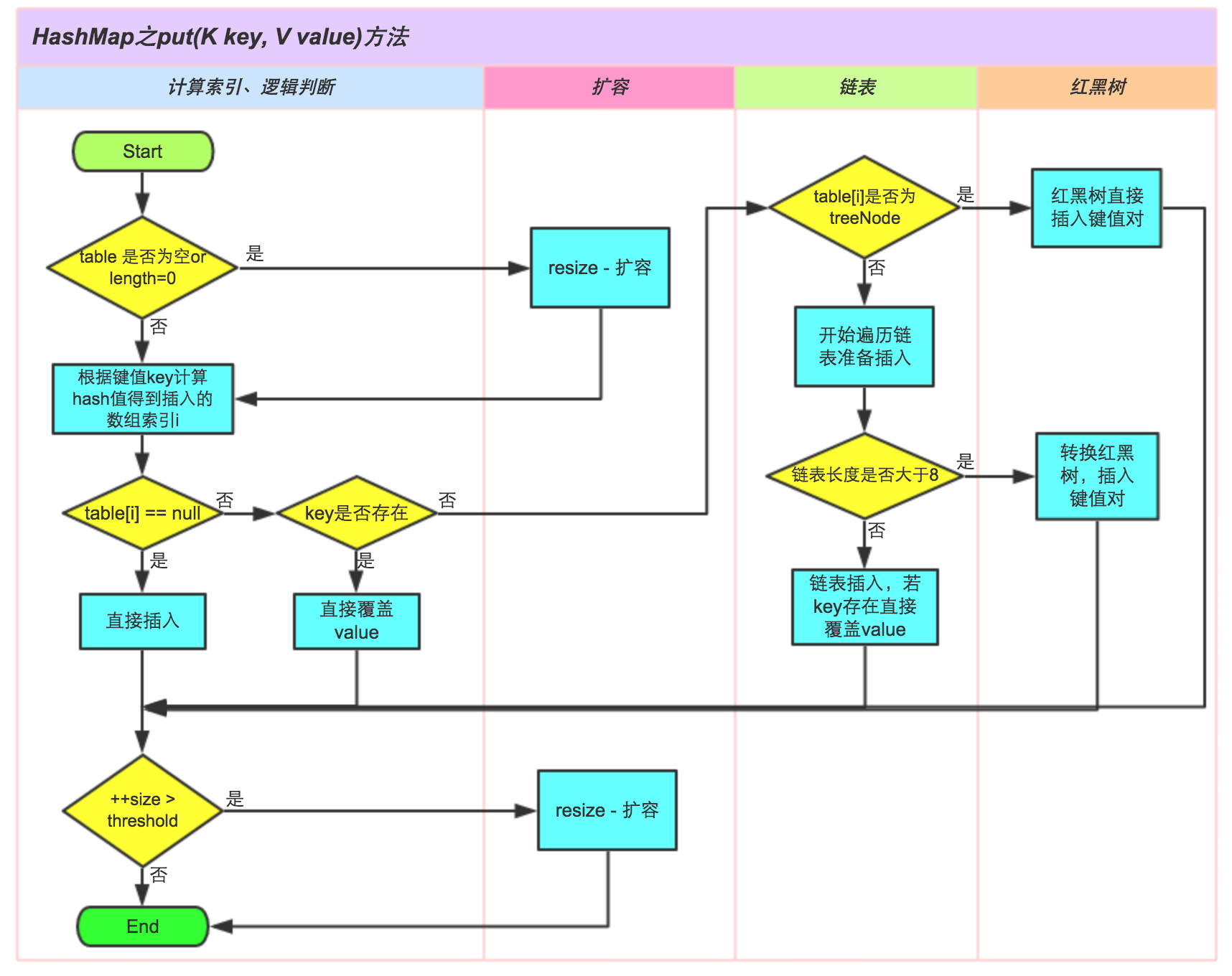
上传个网上的图片,put()方法的流程
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0)//步骤①
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//步骤②
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash && //步骤③
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) //步骤④
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//步骤⑤
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//步骤⑥
resize();
afterNodeInsertion(evict);
return null;
}
步骤:
- 当tab数组为空或长度为0时,执行resize()方法扩容,进入下一步
- 通过key计算hash值,得到数组索引,判断当该索引下的对象为空时,直接新建节点添加对象,跳到步骤⑥,否则进入步骤③
- 判断该数组索引下的首个元素key是否一样,相同则直接覆盖value,否则进入步骤④
- 判断该table[i]是否为treeNode,即是否为红黑树,如果是,直接插入键值对,不是则进入步骤⑤
- 遍历table[i],判断该链表长度是否大于等于8(bigCount从0开始),如果是则把链表转换为红黑树,在红黑树中进行插入操作,如果不是,则进行链表的插入操作
- 判断实际容量是否大于threshold,是则扩容
扩容机制
jdk1.7中,进行扩容时,把旧数据放入到新数组中,链表的插入时,使用的是单链表的头插入方式,同一位置上的新元素总会被放到链头。在jdk1.8中,旧数组中一条链上的元素有可能被放到新数组的不同位置上
在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
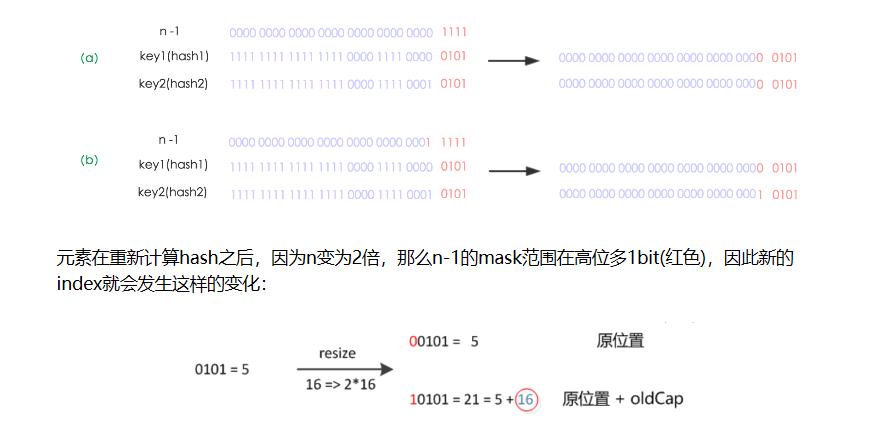
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是JDK1.8不会倒置。
JDK1.7和JDK1.8的HashMap性能比较
HashMap中,如果key经过Hash算法得出的数组索引位置全部不相同,即Hash算法非常好,则getKey()方法的时间复杂度为O(1)。如果Hash算法极差,所有元素都在一个链表下或红黑树下,则时间复杂度为O(N)和O(lgN)。jdk1.8的总体性能优于jdk1.7。
Java集合(一)HashMap的更多相关文章
- 【转】Java集合:HashMap源码剖析
Java集合:HashMap源码剖析 一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调 ...
- Java 集合学习--HashMap
一.HashMap 定义 HashMap 是一个基于散列表(哈希表)实现的键值对集合,每个元素都是key-value对,jdk1.8后,底层数据结构涉及到了数组.链表以及红黑树.目的进一步的优化Has ...
- 死磕 java集合之HashMap源码分析
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 简介 HashMap采用key/value存储结构,每个key对应唯一的value,查询和修改 ...
- Java集合之HashMap
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现(Hashtable跟HashMap很像,唯一的区别是Hashtalbe中的方法是线程安全的,也就是同步的).此实现提供所 ...
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
- Java集合:HashMap源码剖析
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- java 集合之HashMap
原文出处http://zhangshixi.iteye.com/blog/672697 1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操 ...
- java集合使用——HashMap
在map中插入.删除和定位元素时,HashMap是最好的选择.如果要按照自然顺序或自定义顺序遍历(获取所有元素),那么treemap更好一些. 第一:构造和添加元素 HashMap map = new ...
- Java集合之HashMap源码实现分析
1.简介 通过上面的一篇随笔我们知道了HashSet的底层是采用Map实现的,那么Map是什么?它的底层又是如何实现的呢?这下我们来分析下源码,看看具体的结构与实现.Map 集合类用于存储元素对(称作 ...
- Java集合:HashMap底层实现和原理(源码解析)
Note:文章的内容基于JDK1.7进行分析.1.8做的改动文章末尾进行讲解. 一.先来熟悉一下我们常用的HashMap: 1.概述 HashMap基于Map接口实现,元素以键值对的方式存储,并且允许 ...
随机推荐
- C# MVC 返回html内容
var ss = Server.MapPath(""); //C:\Users\Administrator\Desktop\Csharp测试程序\TestMVC\TestMVC s ...
- Can't find variable: SockJS vue项目
用的vue-cli(webpack-simple模板),在开发环境运行(npm run dev),一直都没有问题,突然在ios的safari中调试,出现报错:Can't find variable: ...
- STM32F103 rtthread工程构建
目录 STM32F103 工程构建 1.基本情况 2.硬件连接 3.rtthread配置 4.点灯 5. 码云上git操作 STM32F103 工程构建 1.基本情况 RAM 20K ROM 64K ...
- 爬虫系列(八) 用requests实现天气查询
这篇文章我们将使用 requests 调用天气查询接口,实现一个天气查询的小模块,下面先贴上最终的效果图 1.接口分析 虽然现在网络上有很多免费的天气查询接口,但是有很多网站都是需要注册登陆的,过程比 ...
- 与公司2位经理的交流,Web开发知识库建设
1.代码库3种类型 WebCommon:网站开发技术选型和最佳实践 FansCommons :各种可以复用的代码 CentronCore,CentronWeb 3种类型:通用,web,环境(通用+We ...
- [bzoj4084][Sdoi2015]双旋转字符串_hash
双旋转字符串 bzoj-4084 Sdoi-2015 题目大意:给定两个字符串集合 S 和 T .其中 S 中的所有字符串长度都恰好为 N ,而 T 中所有字符串长度都恰好为 M .且 N+M 恰好为 ...
- HDU 4906 Our happy ending (状压DP)
HDU 4906 Our happy ending pid=4906" style="">题目链接 题意:给定n个数字,每一个数字能够是0-l,要选当中一些数字.然 ...
- [Cypress] Test React’s Controlled Input with Cypress Selector Playground
React based applications often use controlled inputs, meaning the input event leads to the applicati ...
- js使用总结
1.周期性运行函数 setTimeout() 方法用于在指定的毫秒数后调用函数或计算表达式. 举例: <input type="button" value="開始计 ...
- HDU 2586 How far away ?(LCA模板 近期公共祖先啊)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2586 Problem Description There are n houses in the vi ...