[SimHash] the Hash-based Similarity Detection Algorithm
The current information explosion has resulted in an increasing number of applications that need to deal with large volumes of data. While many of the data contains useless redundancy data, especially in mass media, web crawler/analytic fields, wasted many precious resources (power, bandwidth, CPU and storage, etc.). This has resulted in an increased interest in algorithms that process the input data in restricted ways.
But traditional hash algorithms have two problems, first it assumes that the data fits in main memory, it is unreasonable when dealing with massive data such as multimedia data, web crawler/analytic repositories and so on. And second, traditional hash can only indentify the identical data. this brings to light the importance of simhash.
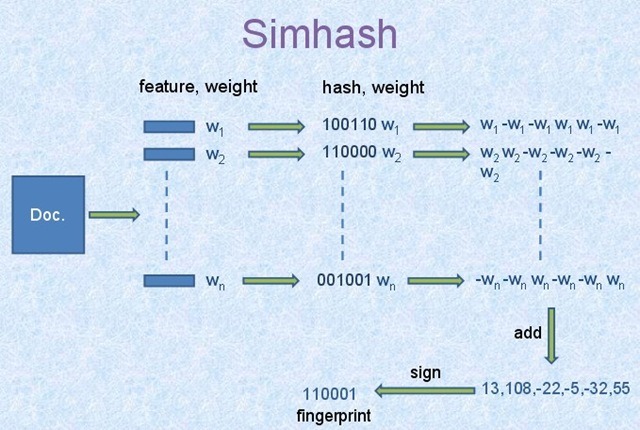
Simhash 5 steps: Tokenize, Hash, Weigh Values, Merge, Dimensionality Reduction
tokenize
tokenize your data, assign weights to each token, weights and tokenize function are depend on your business
hash (md5, SHA1)
calculate token's hash value and convert it to binary (101011 )
weigh values
for each hash value, do hash*w, in this way: (101011 ) -> (w,-w,w,-w,w,w)
merge
add up tokens' values, to merge to 1 hash, for example, merge (4 -4 -4 4 -4 4) and (5 -5 5 -5 5 5) , results to (4+5 -4+-5 -4+5 4+-5 -4+5 4+5),which is (9 -9 1 -1 1)
Dimensionality Reduction
Finally, signs of elements of
Vcorresponds to the bits of the final fingerprint, for example (9 -9 1 -1 1) -> (1 0 1 0 1), we get 10101 as the fingerprint.
How to use SimHash fingerprints?
Hamming distance can be used to find the similarity between two given data, calculate the Hamming distance between 2 fingerprints.
Based on my experience, for 64 bit SimHash values, with elaborate weight values, distance of similar data often differ appreciably in magnitude from those unsimilar data.
how to calculate Hamming distance:
XOR, 只有两个位不同时结果是1 ,否则为0,两个二进制value“异或”后得到1的个数 为海明距离 。
SimHash algorithm, introduced by Charikarand is patented by Google.
simhash 0.1.0 : Python Package Index
[SimHash] the Hash-based Similarity Detection Algorithm的更多相关文章
- A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问
这是我最近看到的一篇论文,思路还是很清晰的,就是改进的LPA算法.改进的地方在两个方面: (1)结合K-shell算法计算量了节点重重要度NI(node importance),标签更新顺序则按照NI ...
- VIPS: a VIsion based Page Segmentation Algorithm
VIPS: a VIsion based Page Segmentation Algorithm VIPS: a VIsion based Page Segmentation Algorithm In ...
- MBMD(MobileNet-based tracking by detection algorithm)作者答疑
If you fail to install and run this tracker, please email me (zhangyunhua@mail.dlut.edu.cn) Introduc ...
- anomaly detection algorithm
anomaly detection algorithm 以上就是异常监测算法流程
- Floyd判圈算法 Floyd Cycle Detection Algorithm
2018-01-13 20:55:56 Floyd判圈算法(Floyd Cycle Detection Algorithm),又称龟兔赛跑算法(Tortoise and Hare Algorithm) ...
- Floyd's Cycle Detection Algorithm
Floyd's Cycle Detection Algorithm http://www.siafoo.net/algorithm/10 改进版: http://www.siafoo.net/algo ...
- 从时序异常检测(Time series anomaly detection algorithm)算法原理讨论到时序异常检测应用的思考
1. 主要观点总结 0x1:什么场景下应用时序算法有效 历史数据可以被用来预测未来数据,对于一些周期性或者趋势性较强的时间序列领域问题,时序分解和时序预测算法可以发挥较好的作用,例如: 四季与天气的关 ...
- 个性探测综述阅读笔记——Recent trends in deep learning based personality detection
目录 abstract 1. introduction 1.1 个性衡量方法 1.2 应用前景 1.3 伦理道德 2. Related works 3. Baseline methods 3.1 文本 ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
随机推荐
- php表单笔记
PHP获取表单值: $_POST //获取POST提交 $_GET // 获取GET提交 <!DOCTYPE html> <html> <head> ...
- 关于HTML Button点击自动刷新页面的问题解决
原因 button,input type=button按钮在IE和w3c,firefox浏览器区别: 1.当在IE浏览器下面时,button标签按钮,input标签type属性为button的按钮是一 ...
- Python基础-画图:matplotlib
Python画图主要用到matplotlib这个库.具体来说是pylab和pyplot这两个子库.这两个库可以满足基本的画图需求. pylab神器:pylab.rcParams.update(para ...
- 【题解】洛谷P1070 道路游戏(线性DP)
次元传送门:洛谷P1070 思路 一开始以为要用什么玄学优化 没想到O3就可以过了 我们只需要设f[i]为到时间i时的最多金币 需要倒着推回去 即当前值可以从某个点来 那么状态转移方程为: f[i]= ...
- Php5.6.31连接sqlserver 2008R2数据库问题sqlsrv(php5.3及以上版本)与mssql(php5.3以前版本)②
Php5.6.31连接sqlserver 2008R2数据库 1.环境配置 Win7(win8.1) 64 +Apache2.4 + PHP5.6.31 + SQL Server 2008 R2数据 ...
- Docker Cache mechanism
Docker build 的 cache 机制: Docker Daemon 通过 Dockerfile 构建镜像时,当发现即将新构建出的镜像 与已有的新镜像重复时,可以选择放弃构建新的镜像,而是选用 ...
- MariaDB中文乱码之解决思路
首先出现乱码的原因就是编码不一致问题引起的,那么就从以下2个方面入手: 1.应用层:前提条件数据库服务端存储的中文数据是对的,但是页面上显示乱码,这里只需要检查你的项目的编码格式,设置成一致就行. 2 ...
- go语言实战笔记(二)
码代码之前一定要安装go,哈哈哈哈,反正我只装goland然后写不了代码报错,卡在第一段代码哈哈哈哈哈哈 新建项目goproject 新建src文件夹 新建main文件夹 新建第一个go文件 开始写 ...
- LaTeX宏包TikZ绘图示例——Go语言起源图
本例所绘图形选自<Go语言程序设计>(作者:Alan A. A. Donovan与Brian W. Kernighan)一书的前言部分. 完整代码 \documentclass{art ...
- JavaWeb基础—EL表达式与JSTL标签库
EL表达式: EL 全名为Expression Language.EL主要作用 获取数据(访问对象,访问数据,遍历集合等) 执行运算 获取JavaWeb常用对象 调用Java方法(EL函数库) 给出一 ...