FlumeNG介绍及安装部署
本节内容:
- Flume简介
- Flume NG核心组件
- Flume部署种类
- Flume单机安装
一、Flume简介
Flume是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。
Flume在0.9.x和1.x之间有较大的架构调整,1.x版本之后的改称为Flume NG。0.9.x的称为Flume OG。
Flume OG体系架构如下,Flume OG已经不再进行版本更新:
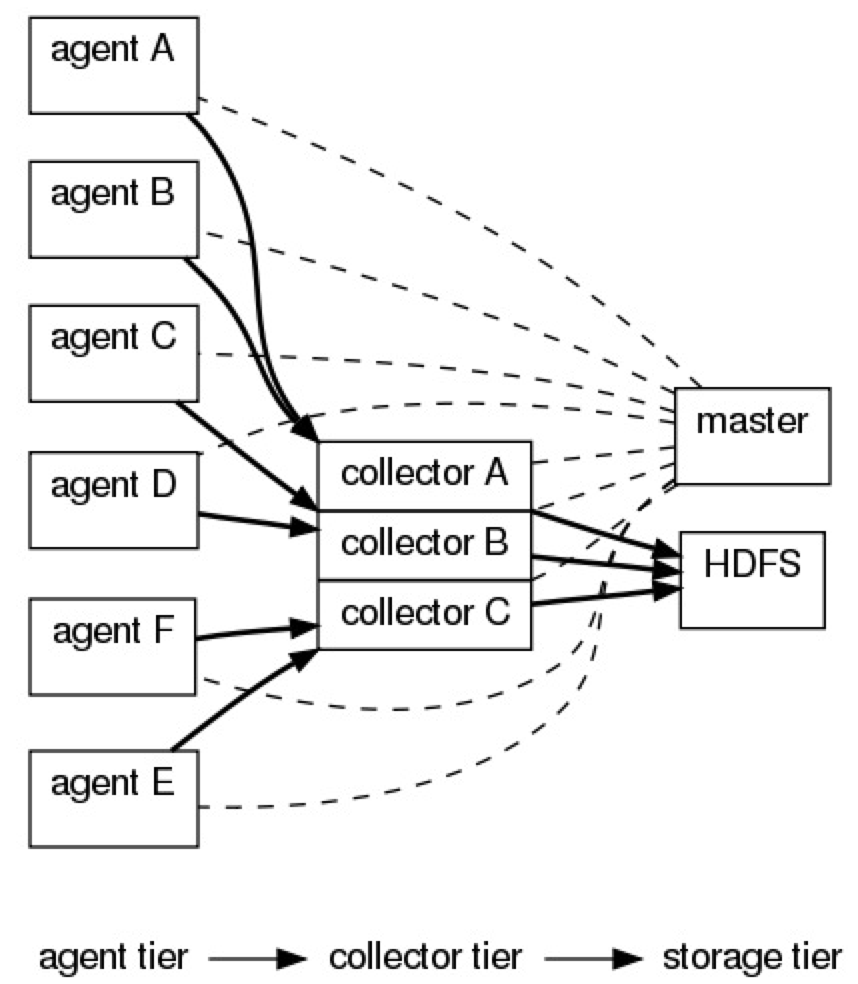
Flume NG体系架构如下:
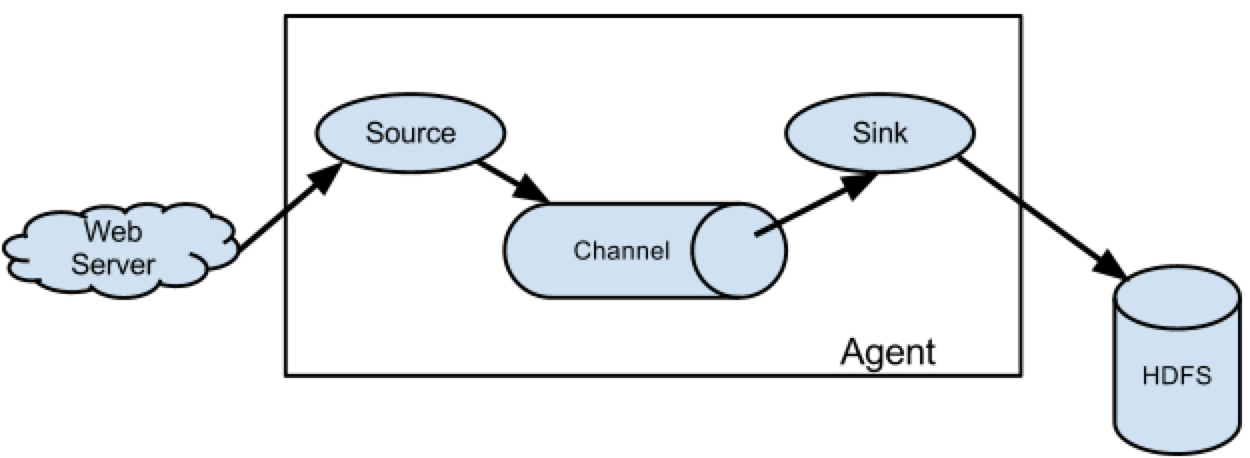
最新的Flume NG是1.7.0,运行最新版本的Flume NG时,机器必须安装JDK7.0或以上的版本,并且,Flume目前在只有在Linux系统的启动脚本,没有Windows环境的启动脚本。
二、Flume NG核心组件
Flume NG主要由3个重要的组件构成:
- Source
- Sink
- Channel
1. Source
完成对日志数据的收集,分成transtion和event打入到channel中。
Flume提供了各种source的实现,包括Avro Source(监控端口)、Exce Source(对命令监控)、Spooling Directory Source(监控某个目录)、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等。
对现有程序改动最小的使用方式是使用直接读取程序原来记录的日志文件,基本可以实现无缝接入,不需要对现有程序进行任何改动。直接读取文件Source,有两种方式:
- Exec Source
以运行Linux命令的方式,持续的输出最新的数据,如tail -f 文件名,在这种方式下,取的文件名必须是指定的。
- Spool Source
是监测配置的目录下新增的文件,并将文件中的数据读取出来。使用Spool Source需要注意:
(1) 拷贝到spool目录下的文件不可以再打开编辑。因为放进去的目录可能在一直被读,一般不可以再被打开了。
(2) spool目录下不可包含相应的子目录。
Spool Source如何使用?
在实际使用过程中,可以结合log4j使用,使用log4j的时候,将log4j的文件切割机制设为1分钟1次,将文件拷贝到spool的监控目录。log4j有一个TimeRolling的插件,可以把log4j分割的文件到spool目录。基本实现了实时的监控。Flume在传完文件之后,将会修改文件的后缀,变为.COMPLETED(后缀也可以在配置文件中灵活指定)。
Exec Source和Spool Source比较?
Exec Source可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性。
Spool Source虽然无法实现实时的收集数据,但是可以使用以分钟的方式切割文件,趋近于实时。
总结:如果应用无法实现以分钟切割文件的话,可以两种收集方式结合使用。
2. Sink
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink等。
Flume Sink在设置数据存储时,可以向文件系统中、数据库中、hadoop中储数据,在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
3. Channel
Flume Channel主要提供一个队列的功能,对Source提供中的数据进行简单的缓存。
Flume对于Channel,则提供了Memory Channel、JDBC Channel、File Channel等。
- MemoryChannel
可以实现高速的吞吐,但是无法保证数据的完整性。
- MemoryRecoverChannel
官方文档建议使用FileChannel来替换。
- FileChannel
保证数据的完整性和一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
三、Flume部署种类
1. 单一代理流程
指只有一个agent在客户端采集。
2. 多代理流程
指一个agent通过中转的Avro传到下一个agent。
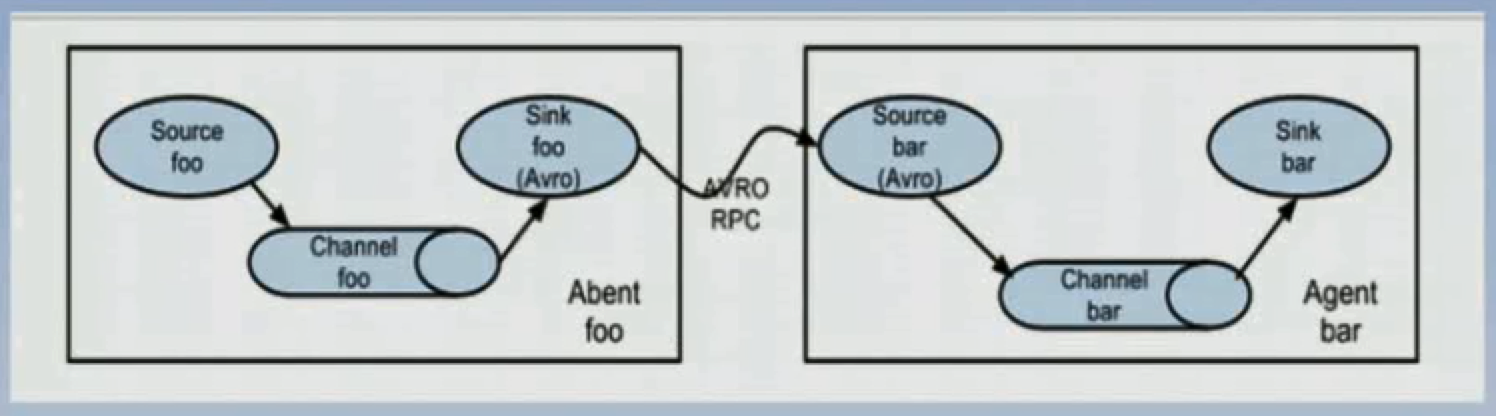
3. 流合并
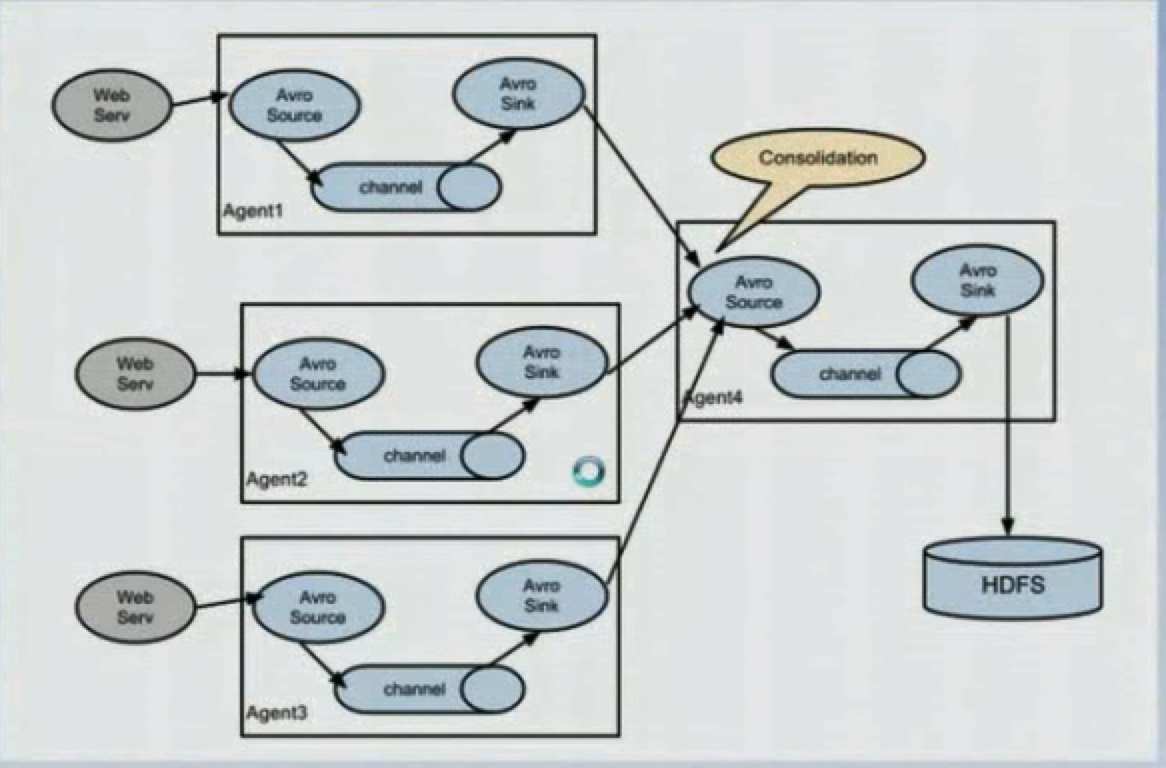
4. 多路复用流

四、Flume单机安装
1. 安装JDK1.7
[root@log1 local]# mkdir /usr/java
[root@log1 local]# tar zxf jdk-7u80-linux-x64.gz -C /usr/java/
[root@log1 local]# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1..0_80
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@log1 local]# source /etc/profile
安装JDK7
2. 安装Flume NG
[root@db local]# tar zxf apache-flume-1.7.-bin.tar.gz
[root@db local]# cd apache-flume-1.7.-bin
3. 一个简单的例子
下面写一个单节点的配置文件。这个配置文件让flume接收事件,并输出到终端。
[root@db apache-flume-1.7.-bin]# vim conf/example.conf
# example.conf: A single-node Flume configuration # Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置示例
这个配置文件定义了一个单agent名字叫a1。a1有一个source在端口44444监听数据,a1的channel是Memory channel,sink是直接输送到终端上。
[root@db apache-flume-1.7.-bin]# bin/flume-ng agent --conf conf --conf-file conf/example.conf --name a1 -Dflume.root.logger=INFO,console
启动Flume NG

4. 测试
打开另外一个终端,telnet端口44444,然后发送一个事件:
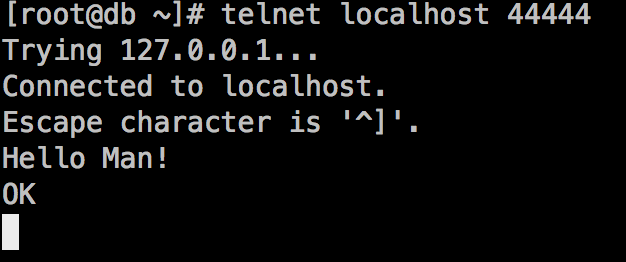
查看原来的终端,可以看到如下的内容:
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:)] Event: { headers:{} body: 6C 6C 6F 4D 6E 0D Hello Man!. }

FlumeNG介绍及安装部署的更多相关文章
- Storm介绍及安装部署
本节内容: Apache Storm是什么 Apache Storm核心概念 Storm原理架构 Storm集群安装部署 启动storm ui.Nimbus和Supervisor 一.Apache S ...
- Apache Solr 初级教程(介绍、安装部署、Java接口、中文分词)
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- Hadoop入门进阶课程13--Chukwa介绍与安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Spark介绍及安装部署
一.Spark介绍 1.1 Apache Spark Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架(没有数据存储).最初在2009年由加州大学伯克利分校的AMPLab开 ...
- Elasticsearch介绍及安装部署
本节内容: Elasticsearch介绍 Elasticsearch集群安装部署 Elasticsearch优化 安装插件:中文分词器ik 一.Elasticsearch介绍 Elasticsear ...
- Zookeeper介绍及安装部署
本节内容: Zookeeper介绍 Zookeeper特点 Zookeeper应用场景 用到了Zookeeper的一些系统 Zookeeper集群安装部署 一.Zookeeper介绍 是一个针对大型分 ...
- 大数据技术之_13_Azkaban学习_Azkaban(阿兹卡班)介绍 + Azkaban 安装部署 + Azkaban 实战
一 概述1.1 为什么需要工作流调度系统1.2 常见工作流调度系统1.3 各种调度工具特性对比1.4 Azkaban 与 Oozie 对比二 Azkaban(阿兹卡班) 介绍三 Azkaban 安装部 ...
随机推荐
- sql service ---- update和delete 误操作数据 ---- 恢复数据
原文出处:http://blog.csdn.net/dba_huangzj/article/details/8491327 问题: 经常看到有人误删数据,或者误操作,特别是update和delete的 ...
- MongoDB - MongoDB CRUD Operations, Bulk Write Operations
Overview MongoDB provides clients the ability to perform write operations in bulk. Bulk write operat ...
- Elasticsearch技术解析与实战(一)基础概念及环境搭建
序言 ES数据架构的主要概念(与关系数据库Mysql对比) 集群(cluster) 集群,一个ES集群由一个或多个节点(Node)组成,每个集群都有一个cluster name作为标识.一下是我们的4 ...
- sql 恢复数据库
RESTORE DATABASE RoadFlowWebForm --数据库名称 FROM DISK = 'E:\WEBFORM2.5.1.bak' --bak文件路径 with replace, M ...
- mysql的force index
MSQL中使用order by 有个坑,会默认走order by 后面的索引.而不走where条件里应该走的索引.大家在使用时要绕过此坑. 如下语句因为order by 走了settle_id这个主键 ...
- Linux学习5-线程
线程 1.1什么是线程? 在一个程序中的多个执行路线就叫做线程(thread).更准确的定义是:线程是一个进程内部的一个控制序列. 要搞清楚fork系统调用和创建新线程之间的区别.当进程执行for ...
- c++刷题(9/100):链表
题目一:https://www.nowcoder.com/practice/d0267f7f55b3412ba93bd35cfa8e8035?tpId=13&tqId=11156&tP ...
- CSS权重的问题
important > 内联 > ID > 类 > 标签 | 伪类 | 属性选择 > 伪对象 > 继承 > 通配符 1.行内样式,指的是html文档中定义的s ...
- ubuntu的PPA
PPA,表示Personal Package Archives,也就是个人软件包集很多软件包由于各种原因吧,不能进入官方的Ubuntu软件仓库.为了方便Ubuntu用户使用,launchpad.net ...
- Gh0st配置加密与解密算法(异或、Base64)
1.前言 分析木马程序常常遇到很多配置信息被加密的情况,虽然现在都不直接分析而是通过Wireshark之类的直接读记录. 2017年Gh0st样本大量新增,通过对木马源码的分析还发现有利用Gh0st加 ...