Spark-Streaming总结
文章出处:http://www.cnblogs.com/haozhengfei/p/e353daff460b01a5be13688fe1f8c952.html
Spark_总结五
1.Storm 和 SparkStreaming区别
| Storm | 纯实时的流式处理,来一条数据就立即进行处理 |
| SparkStreaming | 微批处理,每次处理的都是一批非常小的数据 |
| Storm支持动态调整并行度(动态的资源分配),SparkStreaming(粗粒度, 比较消耗资源) | |
SparkStreaming 优点 || 缺点
2.SparkStreaming
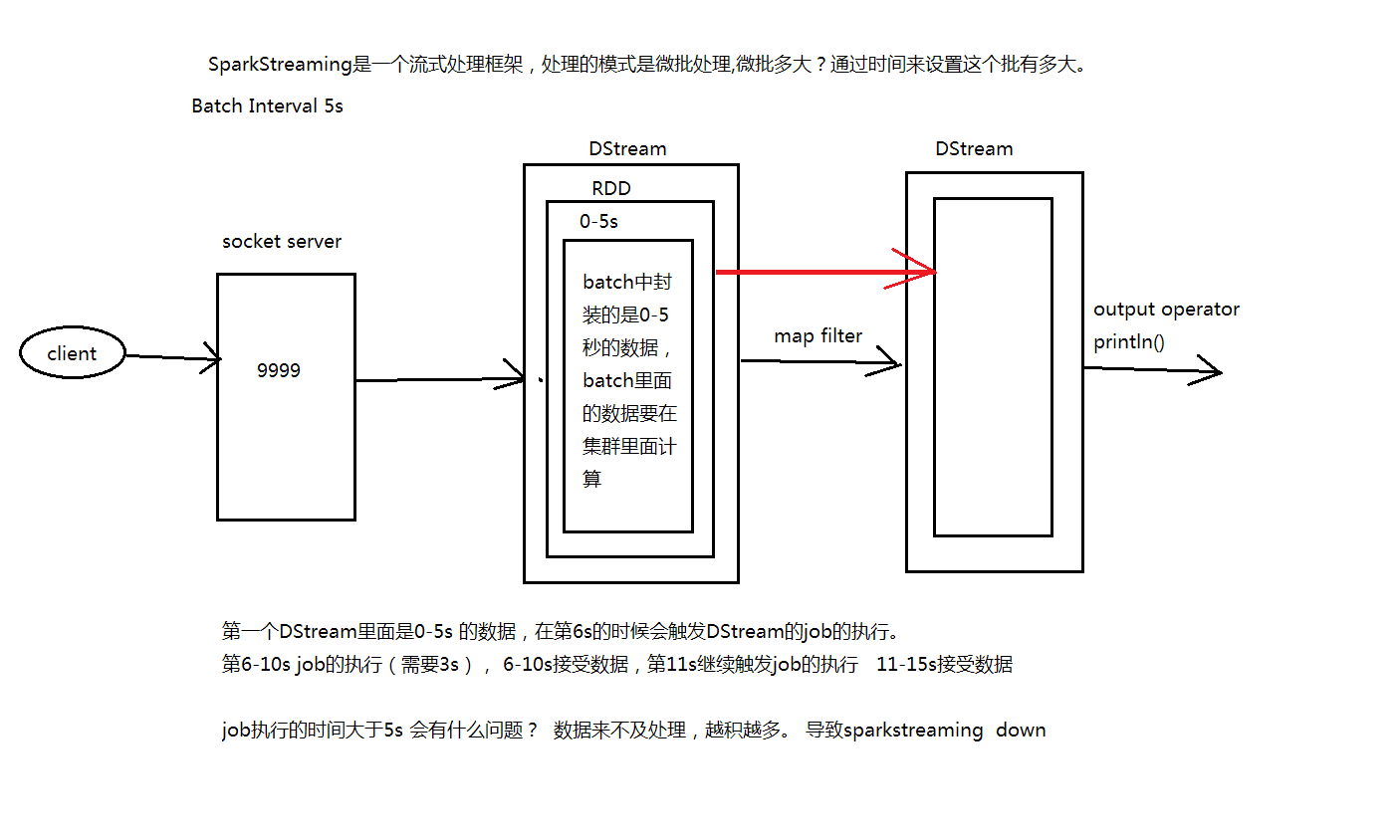
2.1什么是SparkStreaming?
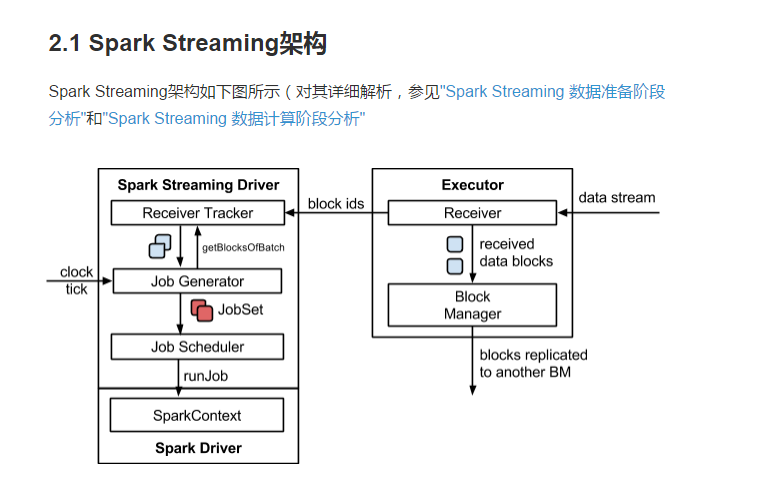
SparkStreaming 架构图
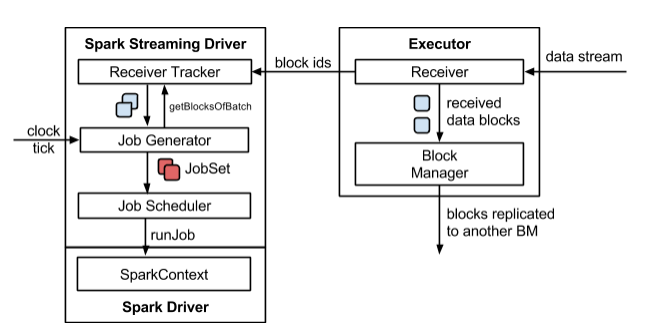
2.2图解SparkStreaming || SparkStreaming执行流程
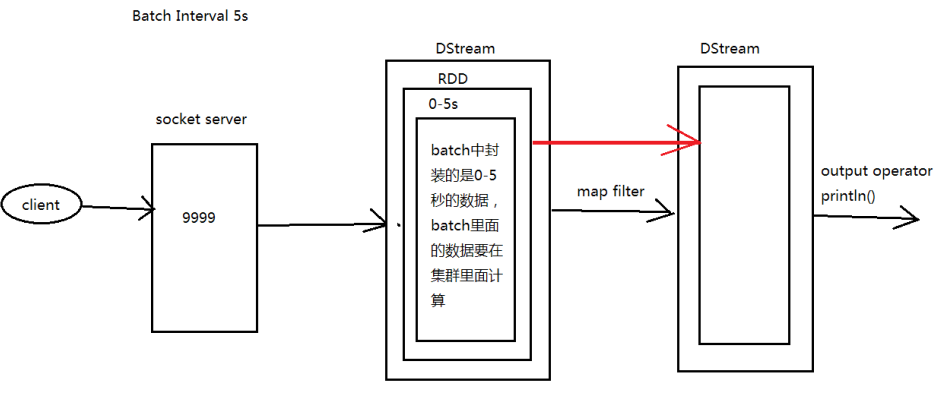
执行流程
2.3SparkStreaming代码TransformOperator
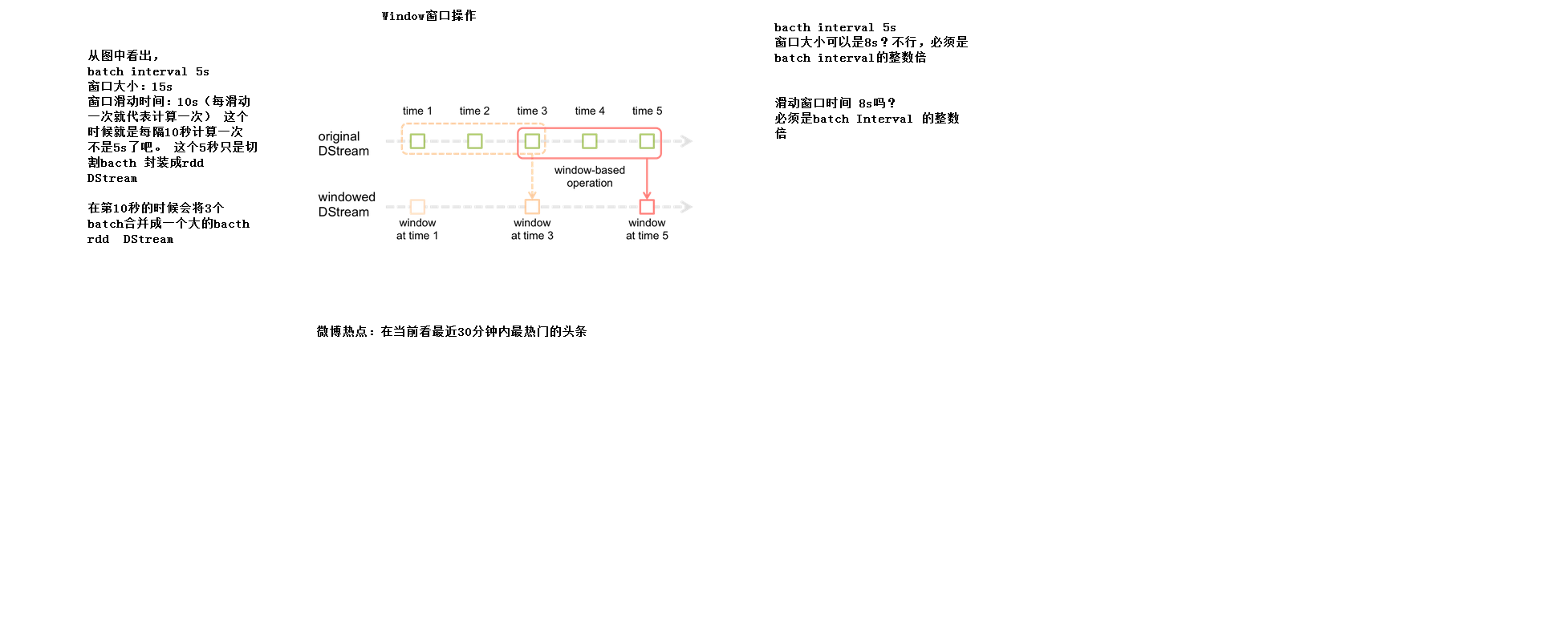
2.4Window窗口操作

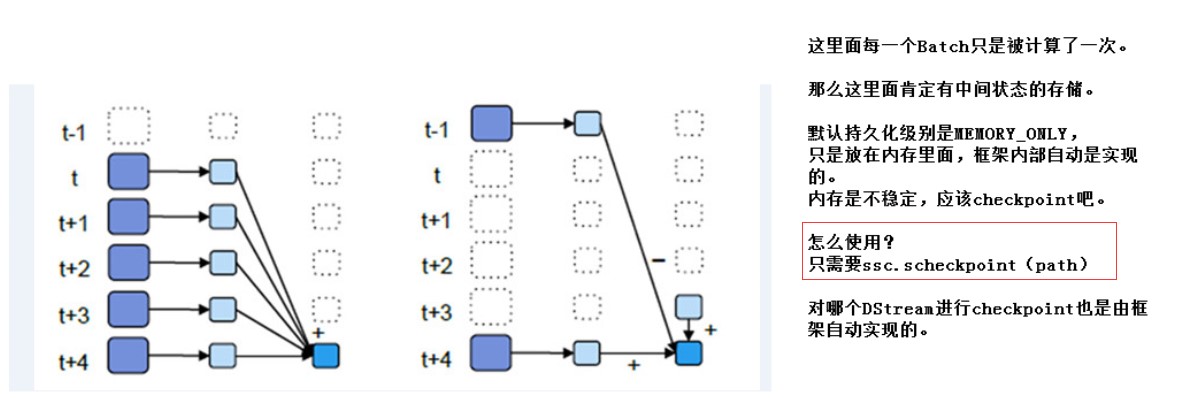
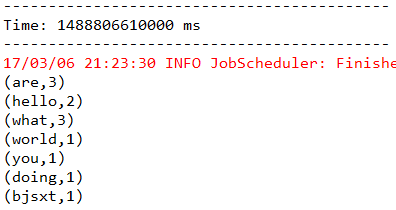
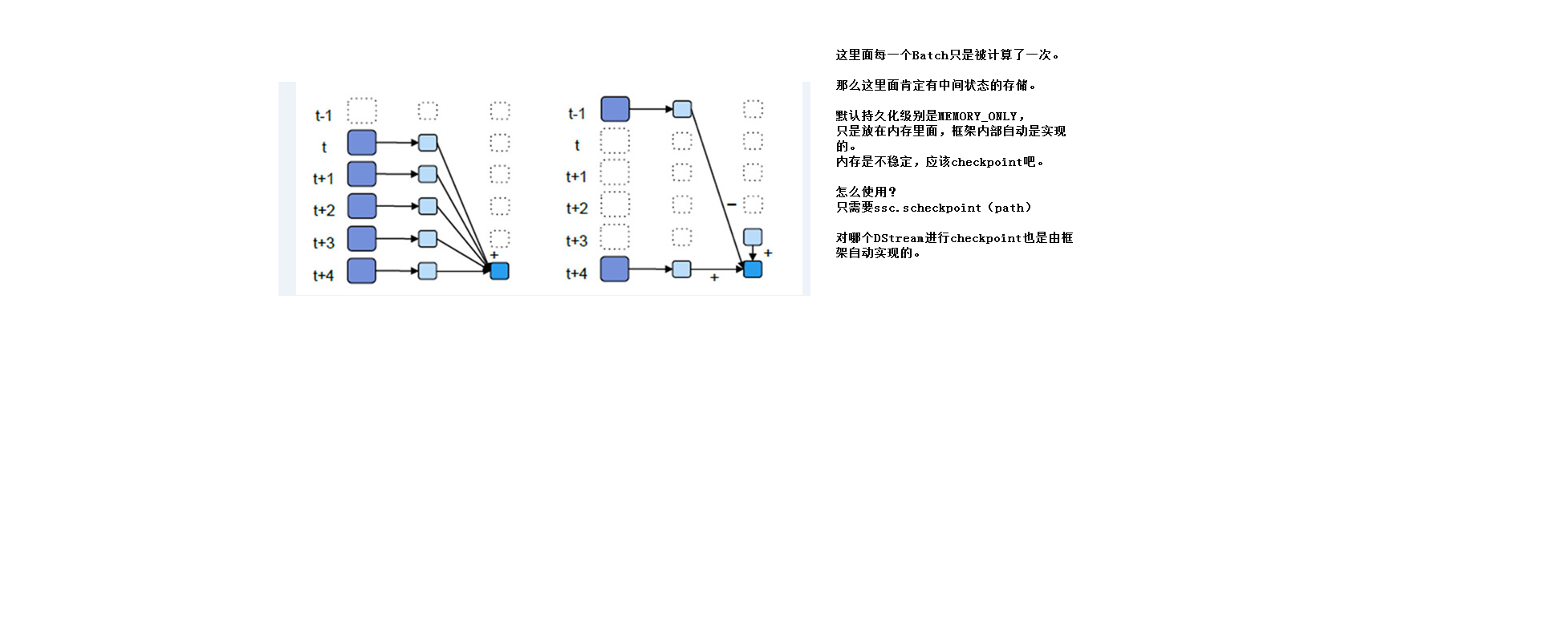
2.5UpdateStateByKey


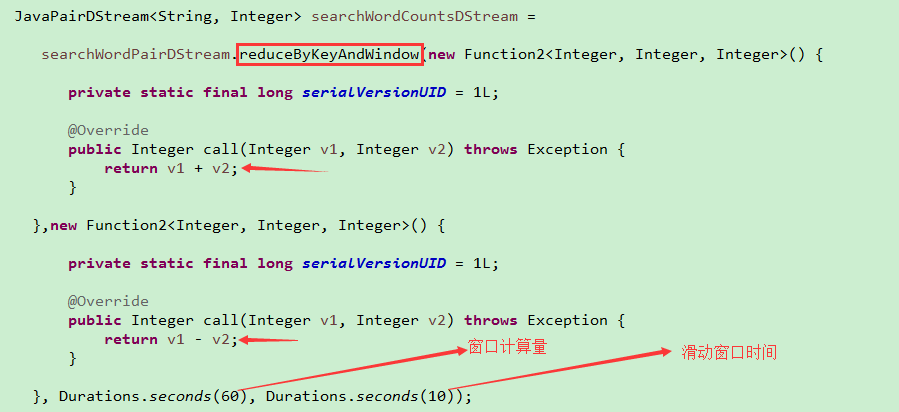
2.6reduceByKeyAndWindow
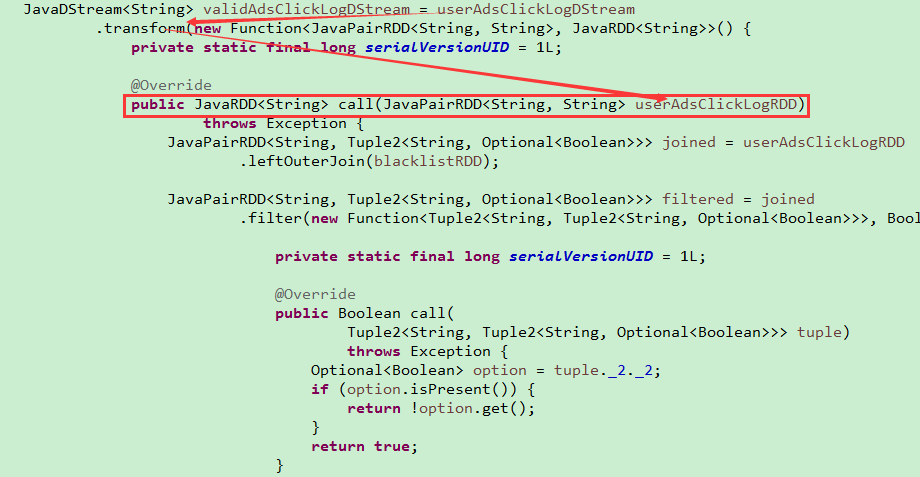
2.6SparkStreaming--Driver HA
2.6.1Driver也有可能挂掉,如何实现它的高可用?
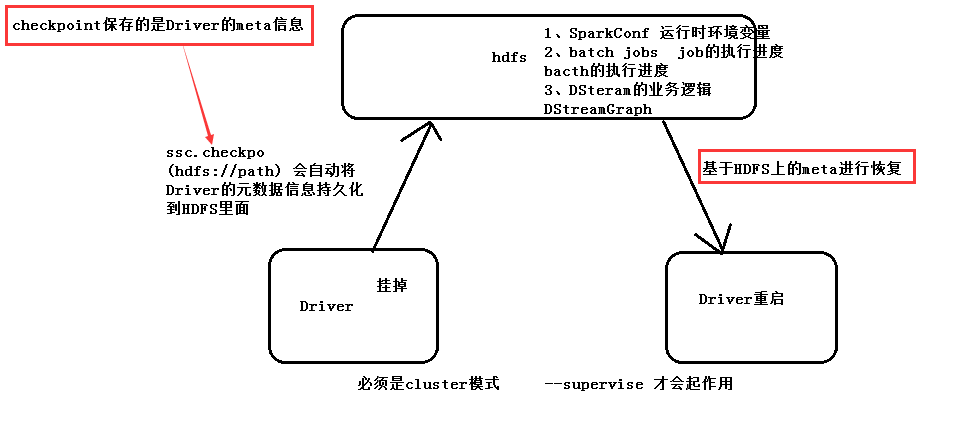
2.6.2Driver HA的代码套路
2.6.3监控HDFS上指定目录下文件数量的变化
2.6.4SparkStreaming 监控 HDFS 上文件数量的变化,并将变化写入到MySql中
3.Kafka
3.1Kafka定义
3.2消息队列常见的场景
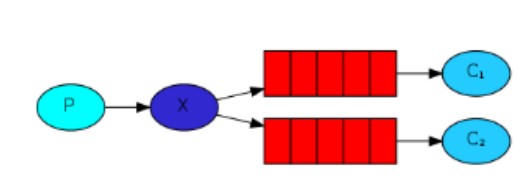

3.3Kafka的架构
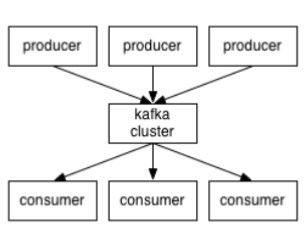

3.4Kafka的消息存储和生产消费模型

3.5kafka 组内queue消费模型 || 组间publish-subscribe消费模型
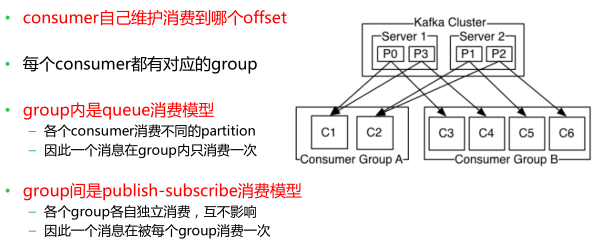
3.6kafka有哪些特点

3.7为什么Kafka的吞吐量高?
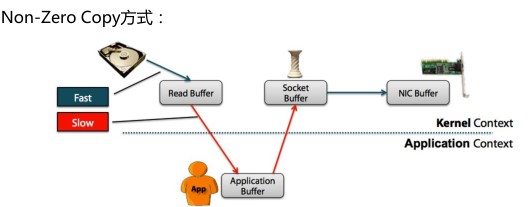
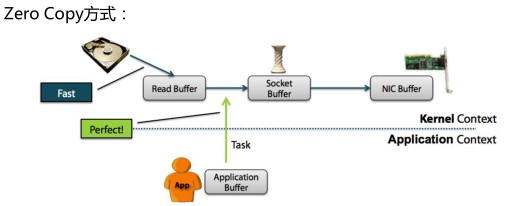
3.8搭建Kafka集群--leader的均衡机制



auto.leader.rebalance.enable=true
3.9Kafka_code注意事项
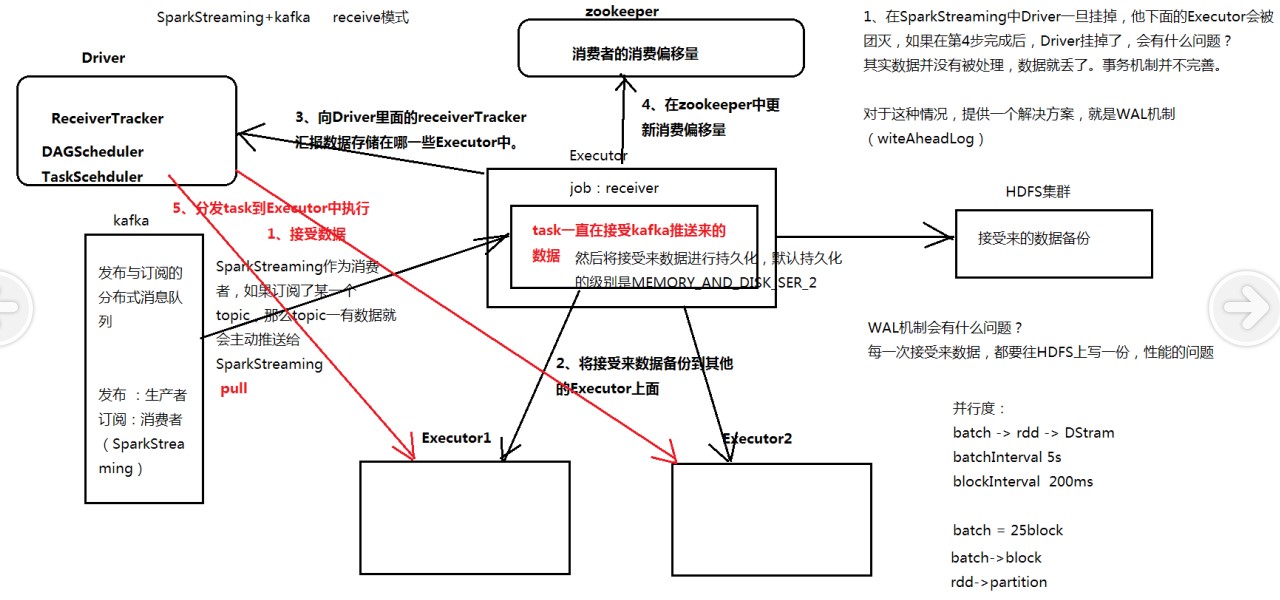
4.SparkStreaming + Kafka 两种模式--Receive模式 || Direct模式
Receive模式--SparkStreaming + Kafka 整体架构
Direct模式
附件列表
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Spark-Streaming总结的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- Spark Streaming中空RDD处理及流处理程序优雅的停止
本期内容 : Spark Streaming中的空RDD处理 Spark Streaming程序的停止 由于Spark Streaming的每个BatchDuration都会不断的产生RDD,空RDD ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
随机推荐
- Python【操作EXCEL文件】
#Python中,对EXCEL文件的读写操作需要安装.导入几个第三方模块#xlrd模块:只能读取EXCEL文件,不能进行写操作#xlwt模块:只能进行写操作,但是不能是覆盖写操作(也就是修改Excel ...
- Ansible1: 简介与基本安装
目录 Ansible特性 Ansible的基本组件 Ansible工作机制 Ansible的安装 Ansible是一个综合的强大的管理工具,他可以对多台主机安装操作系统,并为这些主机安装不同的应用程序 ...
- SpringBoot(十一):Spring boot 中 mongodb 的使用
原文出处: 纯洁的微笑 mongodb是最早热门非关系数据库的之一,使用也比较普遍,一般会用做离线数据分析来使用,放到内网的居多.由于很多公司使用了云服务,服务器默认都开放了外网地址,导致前一阵子大批 ...
- python 调用aiohttp
1. aiohttp安装 pip3 install aiohttp 1.1. 基本请求用法 async with aiohttp.get('https://github.com') as r: a ...
- MySQL报错】ERROR 1558 (HY000): Column count of mysql.user is wrong. Expected 43, found 39.
之前在centos6.4系统安装的是自带的mysql 5.1版本,后来升级到了5.6版本,执行以下命令报错 在网上查找原因说说因为升级不当导致,执行以下命令即可正常执行命令 mysql_upgrade ...
- CF&&CC百套计划3 Codeforces Round #204 (Div. 1) D. Jeff and Removing Periods
http://codeforces.com/problemset/problem/351/D 题意: n个数的一个序列,m个操作 给出操作区间[l,r], 首先可以删除下标为等差数列且数值相等的一些数 ...
- Spring Data JPA原生SQL查询
package com.test.cms.dao.repository;import org.springframework.stereotype.Repository;import javax.pe ...
- Docker 初相见
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后发布到任何流行的 Li ...
- 2016-2017-2 《Java程序设计》第七周学习总结
20155313 2016-2017-2 <Java程序设计>第七周学习总结 第十二章 Lambda 12.1认识Lambda语法 12.1.1Lambda语法概览 在java中引入了La ...
- 【转】c#.net各种应用程序中获取文件路径的方法
控制台应用程序:Environment.CurrentDirectory.Directory.GetCurrentDirectory() windows服务:Environment.CurrentDi ...