CNN初步-2
Pooling
为了解决convolved之后输出维度太大的问题
在convolved的特征基础上采用的不是相交的区域处理

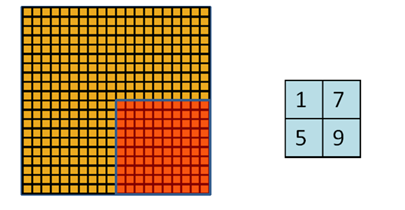
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
这里有一个cnn较好的介绍
Pooling also reduces the output dimensionality but (hopefully) keeps the most salient information.
By performing the max operation you are keeping information about whether or not the feature appeared in the sentence, but you are losing information about where exactly it appeared.
You are losing global information about locality (where in a sentence something happens), but you are keeping local information captured by your filters, like "not amazing" being very different from "amazing not".
局部信息能够学到 "not amaziing" "amzaing not"这样 bag of word 不行的顺序信息(知道他们是不一样的),然后max pooling仍然能够保留这一信息
只是丢失了这个信息的具体位置
There are two aspects of this computation worth paying attention to: Location Invarianceand Compositionality. Let's say you want to classify whether or not there's an elephant in an image. Because you are sliding your filters over the whole
image you don't really care wherethe elephant occurs. In practice, pooling also gives you invariance to translation, rotation and scaling, but more on that later. The second key aspect is (local) compositionality. Each filter composes a local patch of lower-level features into higher-level representation. That's why CNNs are so powerful in Computer Vision. It makes intuitive sense that you build edges from pixels, shapes from edges, and more complex objects from shapes.
来自 <http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/>
关于conv和pooling可选的参数
PADDING

You can see how wide convolution is useful, or even necessary, when you have a large filter relative to the input size. In the above, the narrow convolution yields an output of size
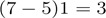
, and a wide convolution an output of size
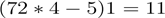
. More generally, the formula for the output size is
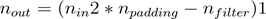
.
来自 <http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/>
narrow对应 tensorflow提供的VALID padding
wide对应tensorflow提供其中特定一种 SAME padding(zero padding)通过补齐0 来保持输出不变
下面有详细解释
STRIDE
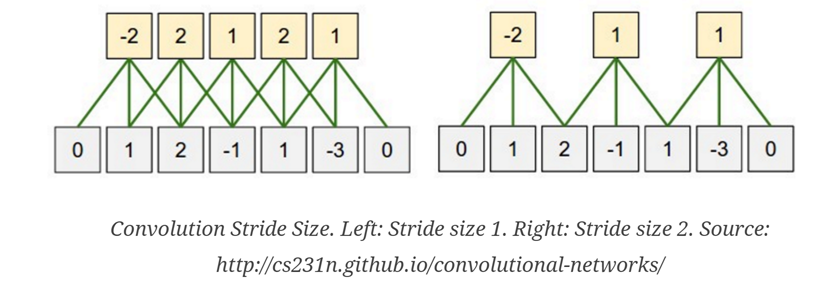
这个比较好理解
每次移动的距离,对应pooling, filter size是多少
一般 stride是多少
|
down vote
|
tensorflow里面提供SAME,VALID两种padding的选择 关于padding, conv和pool用的padding都是同一个padding算法 The TensorFlow Convolution example gives an overview about the difference between SAME and VALID :
And
|
示例
In [2]:
import
tensorflow
as
tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
x = tf.reshape(x, [1, 2, 3, 1]) # give a shape accepted by tf.nn.max_pool
valid_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='VALID')
same_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
print valid_pad.get_shape() == [1, 1, 1, 1] # valid_pad is [5.]
print same_pad.get_shape() == [1, 1, 2, 1] # same_pad is [5., 6.]
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
True
True
[[[[ 5.]]]]
[[[[ 5.]
[ 6.]]]]
In [7]:
x = tf.constant([[1., 2., 3., 4.],
[4., 5., 6., 7.],
[8., 9., 10., 11.],
[12.,13.,14.,15.]])
x = tf.reshape(x, [1, 4, 4, 1]) # give a shape accepted by tf.nn.max_pool
valid_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='VALID')
same_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
print valid_pad.get_shape() # valid_pad is [5.]
print same_pad.get_shape() # same_pad is [5., 6.]
#ess = tf.InteractiveSession()
#ess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
(1, 2, 2, 1)
(1, 2, 2, 1)
[[[[ 5.]
[ 7.]]
[[ 13.]
[ 15.]]]]
[[[[ 5.]
[ 7.]]
[[ 13.]
[ 15.]]]]
In [8]:
x = tf.constant([[1., 2., 3., 4.],
[4., 5., 6., 7.],
[8., 9., 10., 11.],
[12.,13.,14.,15.]])
x = tf.reshape(x, [1, 4, 4, 1]) # give a shape accepted by tf.nn.max_pool
W = tf.constant([[1., 0.],
[0., 1.]])
W = tf.reshape(W, [2, 2, 1, 1])
valid_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding='VALID')
same_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1],padding='SAME')
print valid_pad.get_shape()
print same_pad.get_shape()
#ess = tf.InteractiveSession()
#ess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
(1, 3, 3, 1)
(1, 4, 4, 1)
[[[[ 6.]
[ 8.]
[ 10.]]
[[ 13.]
[ 15.]
[ 17.]]
[[ 21.]
[ 23.]
[ 25.]]]]
[[[[ 6.]
[ 8.]
[ 10.]
[ 4.]]
[[ 13.]
[ 15.]
[ 17.]
[ 7.]]
[[ 21.]
[ 23.]
[ 25.]
[ 11.]]
[[ 12.]
[ 13.]
[ 14.]
[ 15.]]]]
In [9]:
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
x = tf.reshape(x, [1, 2, 3, 1]) # give a shape accepted by tf.nn.max_pool
W = tf.constant([[1., 0.],
[0., 1.]])
W = tf.reshape(W, [2, 2, 1, 1])
valid_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding='VALID')
same_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1],padding='SAME')
print valid_pad.get_shape()
print same_pad.get_shape()
#ess = tf.InteractiveSession()
#ess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
(1, 1, 2, 1)
(1, 2, 3, 1)
[[[[ 6.]
[ 8.]]]]
[[[[ 6.]
[ 8.]
[ 3.]]
[[ 4.]
[ 5.]
[ 6.]]]]
In [ ]:
CNN初步-2的更多相关文章
- CNN初步-1
Convolution: 个特征,则这时候把输入层的所有点都与隐含层节点连接,则需要学习10^6个参数,这样的话在使用BP算法时速度就明显慢了很多. 所以后面就发展到了局部连接网络,也就是说每个隐 ...
- 初步认识CNN
1.机器学习 (1)监督学习:有数据和标签 (2)非监督学习:只有数据,没有标签 (3)半监督学习:监督学习+非监督学习 (4)强化学习:从经验中总结提升 (5)遗传算法:适者生存,不适者淘汰 2.神 ...
- 卷积神经网络(CNN)学习算法之----基于LeNet网络的中文验证码识别
由于公司需要进行了中文验证码的图片识别开发,最近一段时间刚忙完上线,好不容易闲下来就继上篇<基于Windows10 x64+visual Studio2013+Python2.7.12环境下的C ...
- (六)6.18 cnn 的反向传导算法
本文主要内容是 CNN 的 BP 算法,看此文章前请保证对CNN有初步认识,可参考Neurons Networks convolutional neural network(cnn). 网络表示 CN ...
- [置顶] VB6基本数据库应用(三):连接数据库与SQL语句的Select语句初步
同系列的第三篇,上一篇在:http://blog.csdn.net/jiluoxingren/article/details/9455721 连接数据库与SQL语句的Select语句初步 ”前文再续, ...
- Tensorflow的CNN教程解析
之前的博客我们已经对RNN模型有了个粗略的了解.作为一个时序性模型,RNN的强大不需要我在这里重复了.今天,让我们来看看除了RNN外另一个特殊的,同时也是广为人知的强大的神经网络模型,即CNN模型.今 ...
- 用于NLP的CNN架构搬运:from keras0.x to keras2.x
本文亮点: 将用于自然语言处理的CNN架构,从keras0.3.3搬运到了keras2.x,强行练习了Sequential+Model的混合使用,具体来说,是Model里嵌套了Sequential. ...
- 深入学习卷积神经网络(CNN)的原理知识
网上关于卷积神经网络的相关知识以及数不胜数,所以本文在学习了前人的博客和知乎,在别人博客的基础上整理的知识点,便于自己理解,以后复习也可以常看看,但是如果侵犯到哪位大神的权利,请联系小编,谢谢.好了下 ...
- CS229 6.18 CNN 的反向传导算法
本文主要内容是 CNN 的 BP 算法,看此文章前请保证对CNN有初步认识. 网络表示 CNN相对于传统的全连接DNN来说增加了卷积层与池化层,典型的卷积神经网络中(比如LeNet-5 ),开始几层都 ...
随机推荐
- TThread.CreateAnonymousThread() 匿名线程对象的应用
unit Unit1; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, System ...
- CsvHelper支持List<T>
/// <summary> /// Csv帮助类 /// </summary> public class CsvHelper { /// <summary> / ...
- 借助JavaScript中的时间函数改变Html中Table边框的颜色
借助JavaScript中的时间函数改变Html中Table边框的颜色 <html> <head> <meta http-equiv="Content-Type ...
- 12月15日下午Smarty模板函数
1.{$var=...} 这是{assign}函数的简写版,你可以直接赋值给模版,也可以为数组元素赋值. <{$a = 10}><!--赋值语句--> <{$a}> ...
- E:“图片视频”的列表页(taxonomy-cat_media.php)
获取本页的分类ID <?php get_header(); //获取本页的分类ID $cat_title = single_cat_title('', false); //本页分类的名称 $ca ...
- Javascript操作DOM常用API总结
基本概念 在讲解操作DOM的api之前,首先我们来复习一下一些基本概念,这些概念是掌握api的关键,必须理解它们. Node类型 DOM1级定义了一个Node接口,该接口由DOM中所有节点类型实现.这 ...
- netlink优势
netlink相对其他应用进程和内核之间通信的方式(ioctrl或者系统文件等方式),全双工,可由内核发起,应用进程可用epoll监听,而其他方式只能由应用进程发起. 顺便记下隧道,隧道可以通过在ip ...
- linux -目录结构
摘自:http://www.comptechdoc.org/os/linux/usersguide/linux_ugfilestruct.html 这个目录结构介绍是我目前看到介绍最全的,有时间在翻译 ...
- Open Xml 读取Excel中的图片
在我的一个项目中,需要分析客户提供的Excel, 读出其中的图片信息(显示在Excel的第几行,第几列,以及图片本身). 网络上有许多使用Open Xml插入图片到Word,Excel的文章, 但 ...
- Orchard 模块开发学习笔记 (1)
创建模块 首先,打开Bin目录下的Orchard.exe 等到出现orchard>后, 看看命令列表中是否存在 codegen module 如果不存在,则需要先执行:feature enabl ...