Datax3.0使用说明
原文链接:https://github.com/alibaba/DataX/blob/master/introduction.md
一、datax3.0介绍
1、DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。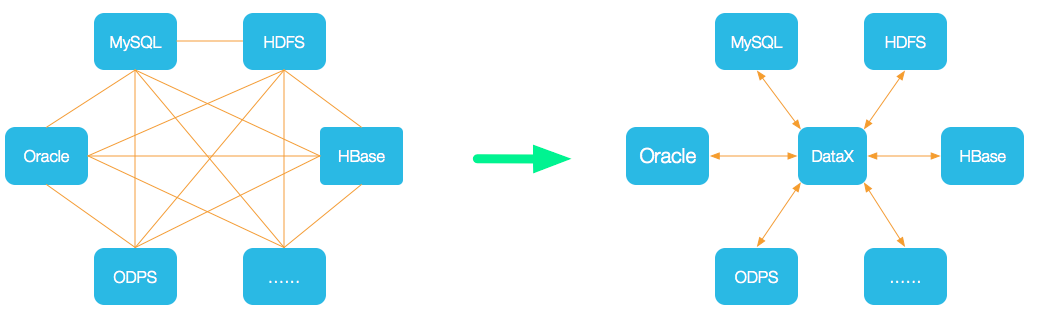
2、DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
1. Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。
2. Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
3. Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。

3、DataX3.0核心架构
1. 核心模块介绍:
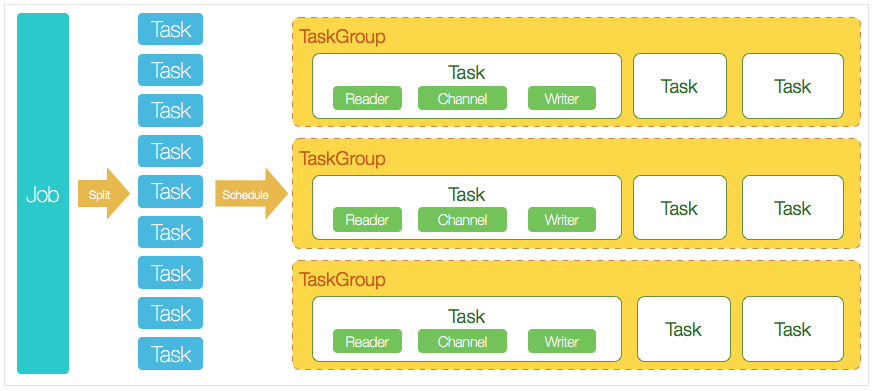
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
2. DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
二、Datax3.0安装部署
1、环境准备
Linux
jdk 1.8
python 2.7.5(datax是由python2开发的)
2、datax下载地址
https://github.com/alibaba/DataX?spm=a2c4e.11153940.blogcont59373.11.7a684c4fvubOe1
查看安装成功:在bin目录下执行 python datax.py ../job/job.json
3、查看配置文件
在bin目录下已经给出了样例配置,但不同的数据源配置文件不一样。通过命令查看配置模板
# python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
示例:[xxx@xxxbin]$ python datax.py -r mysqlreader -w hdfswriter
4、Reader插件和Writer插件
DataX3.0版本提供的Reader插件和Writer插件,每种读插件都有一种和多种切分策略
"reader": {
"name": "mysqlreader", #从mysql数据库获取数据(也支持sqlserverreader,oraclereader)
"name": "txtfilereader", #从本地获取数据
"name": "hdfsreader", #从hdfs文件、hive表获取数据
"name": "streamreader", #从stream流获取数据(常用于测试)
"name": "httpreader", #从http URL获取数据
}
"writer": {
"name":"hdfswriter", #向hdfs,hive表写入数据
"name":"mysqlwriter ", #向mysql写入数据(也支持sqlserverwriter,oraclewriter)
"name":"streamwriter ", #向stream流写入数据。(常用于测试)
}
5、json配置文件模板
1. 整个配置文件是一个job的描述;
2. job下面有两个配置项,content和setting,其中content用来描述该任务的源和目的端的信息,setting用来描述任务本身的信息;
3. content又分为两部分,reader和writer,分别用来描述源端和目的端的信息;
4. setting中的speed项表示同时起几个并发去跑该任务。
1. mysql_to_hive示例
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"querySql": "", #自定义sql,支持多表关联,当用户配置querySql时,直接忽略table、column、where条件的配置。
"fetchSize": "", #默认1024,该配置项定义了插件和数据库服务器端每次批量数据获取条数,该值决定了DataX和服务器端的网络交互次数,能够较大的提升数据抽取性能,注意,该值过大(>2048)可能造成DataX进程OOM
"splitPk": "db_id", #仅支持整形型数据切分;如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,如果该值为空,代表不切分,使用单通道进行抽取
"column": [], #"*"默认所有列,支持列裁剪,列换序
"connection": [
{
"jdbcUrl": ["jdbc:mysql://IP:3306/database?useUnicode=true&characterEncoding=utf8"],
"table": [] #支持多张表同时抽取
}
],
"password": "",
"username": "",
"where": "" #指定的column、table、where条件拼接SQL,可以指定limit 10,也可以增量数据同步,如果该值为空,代表同步全表所有的信息
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [], #必须指定字段名,字段类型,{"name":"","tpye":""}
"compress": "", #hdfs文件压缩类型,默认不填写意味着没有压缩。其中:text类型文件支持压缩类型有gzip、bzip2;orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。
"defaultFS": "", #Hadoop hdfs文件系统namenode节点地址。
"fieldDelimiter": "", #需要用户保证与创建的Hive表的字段分隔符一致
"fileName": "", #HdfsWriter写入时的文件名,需要指定表中所有字段名和字段类型,其中:name指定字段名,type指定字段类型。
"fileType": "", #目前只支持用户配置为”text”或”orc”
"path": "", #存储到Hadoop hdfs文件系统的路径信息,hive表在hdfs上的存储路径
"hadoopConfig": {} #hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"writeMode": "" #append,写入前不做任何处理,文件名不冲突;nonConflict,如果目录下有fileName前缀的文件,直接报错。
}
}
}
],
"setting": {
"speed": { #流量控制
"byte": 1048576, #控制传输速度,单位为byte/s,DataX运行会尽可能达到该速度但是不超过它
"channel": "" #控制同步时的并发数
}
"errorLimit": { #脏数据控制
"record": 0 #对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值,当数量或百分比,DataX Job报错退出
}
}
}
} 2. hive_to_mysql示例
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [], #"*"默认所有列,指定Column信息时,type必须填写,index/value必须选择其一。
"defaultFS": "", #hdfs文件系统namenode节点地址
"encoding": "UTF-8", #默认UTF-8
"nullFormat": "", #文本文件中无法使用标准字符串定义null(空指针),例如:nullFormat:”\N”,那么如果源头数据是”\N”
"compress": "", #orc文件类型下无需填写
"hadoopConfig": {}, #hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"fieldDelimiter": ",", #默认",";读取textfile数据时,需要指定字段分割符,HdfsReader在读取orcfile时,用户无需指定字段分割符
"fileType": "orc", #文件的类型,目前只支持用户配置为”text”、”orc”、”rc”、”seq”、”csv”。
"path": "" #文件路径,支持多文件读取,可以使用"*",也可以指定通配符遍历多文件,单文件只能单线程,多文件可以多线程,线程并发数通过通道数指定
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [], #必须指定,不能留空;如果要依次写入全部列,使用表示, 例如: "column": [""],强烈不建议
"batchSize": "", #默认值1024 一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
"connection": [
{
"jdbcUrl": "jdbc:mysql://IP:3306/database?useUnicode=true&characterEncoding=utf8",
"table": [] #支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。
}
],
"password": "",
"preSql": [], #写入数据到目的表前,会先执行这里的标准语句。例在导入表前先进行删除操作:["delete from 表名"]
"postSql":[], #写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
"session": [], #DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
"username": "",
"writeMode": "" #默认insert ,可选insert/replace/update
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
"errorLimit": { #脏数据控制
"record": 0 #对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值,当数量或百分比,DataX Job报错退出
}
}
}
}
三、Datax3.0使用
# trail_pigeon导入hive
#hive里面建表
CREATE TABLE ods_db_bidata.trail_pigeon (
order_id int ,
order_apply_time string
)
stored as orc tblproperties ("orc.compress"="ZLIB");
#建shell脚本,执行python脚本前先清空目标表
#!/bin/bash
hive_db=ods_db_bidata
hive_table=trail_pigeon
hive -e "truncate table ${hive_db}.${hive_table}"
python /opt/app/datax/bin/datax.py /opt/app/datax/job/mysql2hive/trail_pigeon.json
#写json配置文件
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"splitPk": "order_id",
"connection": [{
"jdbcUrl": ["jdbc:mysql://ip:3306/bidata?useUnicode=true&characterEncoding=utf8"],
"table": ["trail_pigeon"]
}],
"password": "password",
"username": "username",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{"name": "order_id","type": "int"},
{"name": "order_apply_time","type": "string"}
],
"compress": "SNAPPY",
"defaultFS": "hdfs://192.168.0.127:8020",
"fieldDelimiter": "\u0001",
"fileName": "trail_pigeon",
"fileType": "orc",
"path": "/hive/warehouse/ods_db_bidata.db/trail_pigeon",
"writeMode": "nonConflict"
}
}
}],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
Datax3.0使用说明的更多相关文章
- Log4j 2.0 使用说明
原文地址:http://blog.csdn.net/welcome000yy/article/details/7962447 Log4j 2.0 使用说明(1) 之HelloWorld 最近刚接触 ...
- 中小研发团队架构实践之生产环境诊断工具WinDbg 三分钟学会.NET微服务之Polly 使用.Net Core+IView+Vue集成上传图片功能 Fiddler原理~知多少? ABP框架(asp.net core 2.X+Vue)模板项目学习之路(一) C#程序中设置全局代理(Global Proxy) WCF 4.0 使用说明 如何在IIS上发布,并能正常访问
中小研发团队架构实践之生产环境诊断工具WinDbg 生产环境偶尔会出现一些异常问题,WinDbg或GDB是解决此类问题的利器.调试工具WinDbg如同医生的听诊器,是系统生病时做问题诊断的逆向分析工具 ...
- ETL工具--DataX3.0实战
DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换,由淘宝数据平台部门完成. DataX ...
- SerialPort-4.0.+ 使用说明(Java版本)
SerialPort-4.0.+ 项目官网 Kotlin版本使用说明 介绍 SerialPort 是一个开源的对 Android 蓝牙串口通信的轻量封装库,轻松解决了构建自己的串口调试APP的复杂程度 ...
- SerialPort-4.0.+ 使用说明(Kotlin版本)
SerialPort-4.0.+ 项目官网 Java版本使用说明 介绍 SerialPort 是一个开源的对 Android 蓝牙串口通信的轻量封装库,轻松解决了构建自己的串口调试APP的复杂程度,让 ...
- WCF 4.0 使用说明
WCF 4.0开发说明,工具VS2013 ,IIS,使用http协议 打开VS2013,新建项目Visual C#>Web>Asp.NET Web应用程序,添加相关引用: System.S ...
- Gprinter Android SDK V1.0 使用说明
佳博打印机代理商淘宝店https://shop107172033.taobao.com/index.htm?spm=2013.1.w5002-9520741823.2.Sqz8Pf 在此店购买的打印机 ...
- Gprinter Android SDK V2.0 使用说明
佳博特约经销商,此店购买的打印机问题优先解决哟 https://shop107172033.taobao.com/index.htm?spm=2013.1.w5002-9520741823.2.V1p ...
- Log4j 2.0 使用说明(1) 之HelloWorld
以下是Log4j2.0的类图,以便大家对2.0有一个整体的理解. 就如我们学习任何一个技术一样,这里我们首先写一个Hello World: 1,新建工程TestLog4j 2,下载Log4j 2.0有 ...
随机推荐
- GIT速成
安装工具与使用工具: GIT工具 :https://www.git-scm.com/download/ WINGDOWS图形界面工具:https://download.tortoisegit.org/ ...
- python queue和生产者和消费者模型
queue队列 当必须安全地在多个线程之间交换信息时,队列在线程编程中特别有用. class queue.Queue(maxsize=0) #先入先出 class queue.LifoQueue(ma ...
- elipse安装php
在用eclipse作为PHP的开发IDE工具时,如果下载的Eclipse不带有PHP功能,则需要我们自己来给Eclipse升级.不过也可以下载eclipseForPHP 在Eclipse的help菜单 ...
- JSP九大内置对象与Servlet的对应关系
JSP对象 Servlet中怎样获得 request service方法中的request参数 response service方法中的res ...
- VisualSVN Server迁移的方法
VisualSVN Server迁移涉及到两种情况: 第一种情况:VisualSVN Server没有更换电脑或者服务器,只是修改Server name. 第二种情况:当VisualSVN Serve ...
- python_web应用雏型
python_web应用雏型 Web应用程序顾名思义,就是一种可以通过Web访问的应用程序, Web应用的最大特点是用户只需要有网络和浏览器,不需要再安装其他软件就可顺利通过web访问到程序. WEB ...
- 第二次作业——App案例分析
第一部分 调研, 评测 下载软件并使用起来,描述最简单直观的个人第一次上手体验. 我选择的应用是chrome浏览器.之所以选择分析它,是因为我用的时间较长,对功能比较熟悉. chrome浏览器提供了应 ...
- virtualbox 错误解决记录
1,E_INVALIDARG (0x80070057),virtualbox中Cannot register the hard disk错误解决办法 virtualbox中加载已有的虚拟硬盘时出现Ca ...
- 【理解】 Error 10053和 Error 10054
1. 10053 这个错误码的意思是: A established connection was aborted by the software in your host machine, 一个已建 ...
- 基于easyui开发Web版Activiti流程定制器详解(三)——页面结构(上)
上一篇介绍了定制器相关的文件,这篇我们来看看整个定制器的界面部分,了解了页面结构有助于更好的理解定制器的实现,那么现在开始吧! 首先,我们来看看整体的结构: 整体结构比较简单,主要包括三个部分: 1. ...