02Spark的左连接
两个文件,一个是用户的数据,一个是交易的数据。
用户:
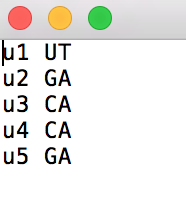
交易:
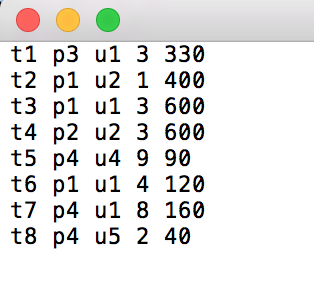
流程如下:
分为以下几个步骤: (1)分别读取user文件和transform文件,并转为两个RDD.
* (2)对上面两个RDD执行maptopair操作。生成userpairRdd和transformpairRdd
* (3)对transformpairRdd和userpairRdd执行union操作,就是把上面的数据放在一起,生成allRdd
* (4)然后把allRdd用groupBykey分组,把同一个UserID的数据都放在一起。生成groupRdd。
* (5)对grouprdd处理,生成productLoctionRdd:(p1,UT),(p2,UT)这种productlistRdd。
* (6)productlistRdd这里面有数据重复,需要去重。
代码结构:

代码:
package com.test.book; import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Set; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; public class LeftJoinCmain { /*
* 分为以下几个步骤: (1)分别读取user文件和transform文件,并转为RDD.
* (2)对上面两个RDD执行maptopair操作。生成userpairRdd和transformpairRdd
* (3)对transformpairRdd和userpairRdd执行union操作,就是把上面的数据放在一起,生成allRdd
* (4)然后把allRdd用groupBykey分组,把同一个UserID的数据都放在一起。生成groupRdd。
* (5)对grouprdd处理,生成productLoctionRdd:(p1,UT),(p2,UT)这种productlistRdd。
* (6)productlistRdd这里面有数据重复,需要去重。
*
*/ public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("LeftJoinCmain").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 导入user的数据
JavaRDD<String> user = sc.textFile("/Users/mac/Desktop/user.txt");
// 导入transform的数据
JavaRDD<String> transform = sc.textFile("/Users/mac/Desktop/transactions.txt"); // 生成一个JavaPairRDD,KEY是uerID,Value是Tuple的形式,("L",地址)
JavaPairRDD<String, Tuple2<String, String>> userpairRdd = user
.mapToPair(new PairFunction<String, String, Tuple2<String, String>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Tuple2<String, String>> call(String line) throws Exception {
String[] args = line.split(" ");
return new Tuple2<String, Tuple2<String, String>>(args[0],
new Tuple2<String, String>("L", args[1]));
} }); // 生成一个transform,
JavaPairRDD<String, Tuple2<String, String>> transformpairRdd = transform
.mapToPair(new PairFunction<String, String, Tuple2<String, String>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Tuple2<String, String>> call(String line) throws Exception {
String[] args = line.split(" "); return new Tuple2<String, Tuple2<String, String>>(args[2],
new Tuple2<String, String>("P", args[1]));
}
}); /**
* allRdd的格式是: { (userID,Tuple("L","UT")), (userID,Tuple("P","p3")) . . . }
*/
JavaPairRDD<String, Tuple2<String, String>> allRdd = userpairRdd.union(transformpairRdd); /**
* 这一步就是把同一个uerID的数据放在一起,结果是: (userID1,List[(Tuple2("L","UT"),//一个用户地址信息
* Tuple2("P","p1"),//其他的都是商品信息 Tuple2("P","p2") ] )
*/
JavaPairRDD<String, Iterable<Tuple2<String, String>>> groupRdd = allRdd.groupByKey(); /**
* 这一步就是从groupRdd中去掉userID,生成productLoctionRdd:(p1,UT),(p2,UT)这种。
*
*/ JavaPairRDD<String, String> productlistRdd = groupRdd.flatMapToPair(
new PairFlatMapFunction<Tuple2<String, Iterable<Tuple2<String, String>>>, String, String>() { @Override
public Iterable<Tuple2<String, String>> call(Tuple2<String, Iterable<Tuple2<String, String>>> t)
throws Exception { String location = "UNKNOWN";
Iterable<Tuple2<String, String>> pairs = t._2;
List<String> products = new ArrayList<String>();
for (Tuple2<String, String> pair : pairs) { if (pair._1.equals("L"))
location = pair._2;
if (pair._1.equals("P")) {
products.add(pair._2);
} } List<Tuple2<String, String>> kvList = new ArrayList<Tuple2<String, String>>(); for (String product : products) {
kvList.add(new Tuple2<String, String>(product, location)); }
return kvList;
}
}); // 把一个商品的所有地址都查出来 JavaPairRDD<String, Iterable<String>> productbylocation = productlistRdd.groupByKey();
List<Tuple2<String, Iterable<String>>> debug3 = productbylocation.collect(); for (Tuple2<String, Iterable<String>> value : debug3) { Iterator<String> iterator = value._2.iterator(); while (iterator.hasNext()) {
System.out.println(value._1 + ":" + iterator.next());
} } /**
* 上述代码经过调试, 结果如下: p2:GA p4:GA p4:UT p4:CA p1:UT p1:UT p1:GA p3:UT
*
*
* 发现有相同的商品和地址。我们需要把这个重复的结果去除。
*/
// 处理如下:我们用mapvalues()函数 JavaPairRDD<String, Tuple2<Set<String>, Integer>> productByuniqueLocation = productbylocation
.mapValues(new Function<Iterable<String>, Tuple2<Set<String>, Integer>>() { @Override
public Tuple2<Set<String>, Integer> call(Iterable<String> v1) throws Exception {
Set<String> uniquelocations = new HashSet<String>(); Iterator<String> iterator = v1.iterator(); while (iterator.hasNext()) { String value = iterator.next();
uniquelocations.add(value); } // 返回一个商品的所有地址,以及地址的个数。
return new Tuple2<Set<String>, Integer>(uniquelocations, uniquelocations.size());
}
}); List<Tuple2<String, Tuple2<Set<String>, Integer>>> finalresult = productByuniqueLocation.collect();
for (Tuple2<String, Tuple2<Set<String>, Integer>> vTuple2 : finalresult) { String aa=vTuple2._1;
Iterator<String> iterator=vTuple2._2._1.iterator();
while(iterator.hasNext())
{
System.out.println("商品的名字:"+aa+"所有的地址"+iterator.next()); } } } }
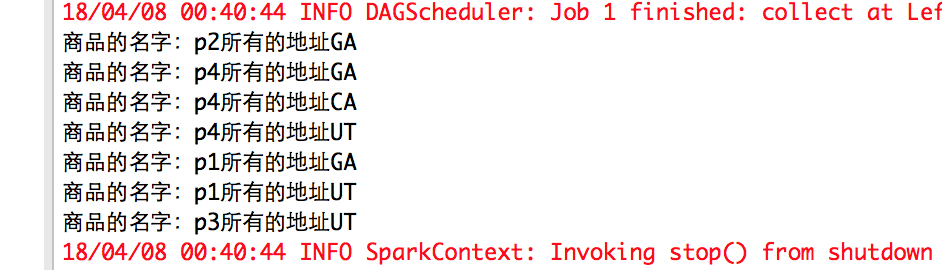
运行结果:

去重后的结果:
02Spark的左连接的更多相关文章
- mysql 内连接、左连接、右连接
记录备忘下,初始数据如下: DROP TABLE IF EXISTS t_demo_product; CREATE TABLE IF NOT EXISTS t_demo_product( proid ...
- 《Entity Framework 6 Recipes》中文翻译系列 (16) -----第三章 查询之左连接和在TPH中通过派生类排序
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 3-10应用左连接 问题 你想使用左外连接来合并两个实体的属性. 解决方案 假设你有 ...
- 数据库中的左连接(left join)和右连接(right join)区别
Left Join / Right Join /inner join相关 关于左连接和右连接总结性的一句话: 左连接where只影向右表,右连接where只影响左表. Left Join select ...
- MySQL的左连接、右连接和全连接的实现
表student:+----+-----------+------+| id | name | age |+----+-----------+------+| 1 | Jim | 18 || 2 | ...
- Oracle 左连接、右连接、全外连接、(+)号作用
分类: Oracle Oracle 外连接 (1)左外连接 (左边的表不加限制) (2)右外连接(右边的表不加限制) (3)全外连接(左右两表都不加限制) 外连接(Outer ...
- Linq连接查询之左连接、右连接、内连接、全连接、交叉连接、Union合并、Concat连接、Intersect相交、Except与非查询
内连接查询 内连接与SqL中inner join一样,即找出两个序列的交集 Model1Container model = new Model1Container(); //内连接 var query ...
- LINQ的左连接、右连接、内连接
.左连接: var LeftJoin = from emp in ListOfEmployees join dept in ListOfDepartment on emp.DeptID equals ...
- 数据库左连接left join、右连接right join、内连接inner join on 及 where条件查询的区别
join on 与 where 条件的执行先后顺序: join on 条件先执行,where条件后执行:join on的条件在连接表时过滤,而where则是在生成中间表后对临时表过滤 left joi ...
- SQL Server中的连接查询【内连接,左连接,右连接,。。。】
在查询多个表时,我们经常会用“连接查询”.连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志. 什么是连接查询呢? 概念:根据两个表或多个表的列之间的关系,从这些表中查询数据 ...
随机推荐
- LeetCode(485. 最大连续1的个数)
问题描述 给定一个二进制数组, 计算其中最大连续1的个数. 示例 1: 输入: [1,1,0,1,1,1] 输出: 3 解释: 开头的两位和最后的三位都是连续1,所以最大连续1的个数是 3. 注意: ...
- Android应用程序性能优化Tips
对于我们设计的应用需要做到以下特征:build an app that's smooth, responsive(反应敏捷), and uses as little battery as possib ...
- 【DWM1000】 code 解密6一TAG 状态机第一步
我们前面分析过,不论ANCHOR 还是TAG,前面变量的初始化基本都是一样的,只是状态机必须明确区分不同的设备类型.我们从开始看TAG.由于初始化TAG的 testAppState一样初始化为TA_I ...
- 数模转换ADC08009应用
#include <reg52.h> //头文件 #define uchar unsigned char //宏定义无符号字符型 #define uint unsigned int //宏 ...
- [CC-BSTRLCP]Count Binary Strings
[CC-BSTRLCP]Count Binary Strings 题目大意: 对于一个长度为\(n\)的\(\texttt0/\texttt1\)串\(S\),如果存在一个切分\(i\),使得\(S_ ...
- [SDOI2017]树点涂色
Description: Bob有一棵\(n\)个点的有根树,其中1号点是根节点.Bob在每个点上涂了颜色,并且每个点上的颜色不同. 定义一条路径的权值是:这条路径上的点(包括起点和终点)共有多少种不 ...
- Java基础-对象的内存分配与初始化(一定要明白的干货)
首先,什么是类的加载?类的加载由类加载器执行.该步骤将查找字节码(classpath指定目录),并从这些字节码中创建一个Class对象.Java虚拟机为每种类型管理一个独一无二的Class对象.也就是 ...
- servlet 表单加上multipart/form-data后request.getParameter获取NULL(已解决)
先上结论(可能不对,因为这是根据实践猜测而来,欢迎指正) 表单改为multipart/form-data传值后,数据就不能通过普通的request.getParameter获取. 文件和文件名通过Fi ...
- 百度杯 ctf 九月场---Text
一看题目发现善于查资料就行了,那估计就是以前的漏洞,需要百度搜一下,果然是海洋cms的漏洞!这个漏洞是前台getshell漏洞,seach漏洞,该漏洞成因在于search.php没有对用户输入内容进行 ...
- Tips_方格拼图效果
用原生的javascript实现方格拼图效果 1.新建文件夹 代码如下: 01.html <!DOCTYPE html> <html lang="en"> ...