【dataX】阿里开源ETL工具——dataX简单上手
一、概述
1.是什么?
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
开源地址:https://github.com/alibaba/DataX
二、简介
1.设计架构
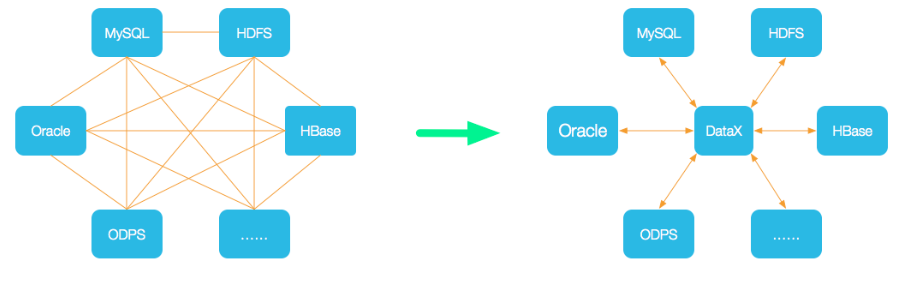
数据交换通过DataX进行中转,任何数据源只要和DataX连接上即可以和已实现的任意数据源同步
2.框架结构

核心组件:
Reader:数据采集模块,负责从源采集数据
Writer:数据写入模块,负责写入目标库
Framework:数据传输通道,负责处理数据缓冲等
以上只需要重写Reader与Writer插件,即可实现新数据源支持
支持主流数据源,详见:https://github.com/alibaba/DataX/blob/master/introduction.md
从一个JOB来理解datax的核心模块组件:
datax完成单个数据同步的作业,称为Job,job会负责数据清理、任务切分等工作;
任务启动后,Job会根据不同源的切分策略,切分成多个Task并发执行,Task就是执行作业的最小单元
切分完成后,根据Scheduler模块,将Task组合成TaskGroup,每个group负责一定的并发和分配Task
三、入门
1.安装
参考官方文档
提取为安装随笔:https://www.cnblogs.com/jiangbei/p/10901201.html
2.使用
核心就是编写配置文件(当前版本使用JSON)
在datax服务器上运行:
python bin/datax.py -r mysqlreader -w hdfswriter
即可获取配置模板
【配置文件】:
先看一个示例:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "",
"password": "",
"connection": [{
"querySql": [
"SELECT Id,CopId,BrandId,PayType,TradeNo,OutTradeNo,TotalFee,PayTotalFee,PayCashFee,PayCouponFee,RefundFee,ShopId,VipOldCode,VipId,UserCode,PayStatus,IsReverse,CreateDate,UNIX_TIMESTAMP(LastModifiedDate) as LastModifiedDate FROM mall_out_sales_order_pay where brandid=63 order by createDate asc;"
],
"jdbcUrl": [
"jdbc:mysql://192.168.12.41:3306/ezp-pay"
]
}]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "",
"password": "",
"dateFormat": "YYYY-MM-dd hh:mm:ss",
"column": [
"Id",
"CopId",
"BrandId",
"PayType",
"TradeNo",
"OutTradeNo",
"TotalFee",
"PayTotalFee",
"PayCashFee",
"PayCouponFee",
"RefundFee",
"ShopId",
"VipOldCode",
"VipId",
"UserCode",
"PayStatus",
"IsReverse",
"CreateDate",
"LastModifiedDate"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from pay_order where brandid=63"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/ezp-pay",
"table": [
"pay_order"
]
}]
}
}
}]
}
}
JSON配置文件
整个配置文件是一个Job配置文件,以Job为起手根元素,Job下面两个子元素配置项:setting和content,
其中,setting描述任务本身的信息,content描述源(reader)和目的端(writer)的信息:

其中,content下又分为reader和writer两块,分别对应源端和目的端:

各reader与writer插件的文档直接点击对应的文件夹进入doc即可!
3.示例
编写一个Mysql到本地打印的Job:
根据Mysqlreader插件编写配置文件:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"age",
"name"
],
"connection": [
{
"table": [
"girl"
],
"jdbcUrl": [
"jdbc:mysql://192.168.19.129:3306/mysql"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
根据自检脚本(文件颜色浅绿色),可以知道需要是可执行文件,添加权限:
chmod +x mysqltest.json
使用运行命令,运行即可:(进入bin目录运行命令如下)
python datax.py ../job/mysqltest.json
有时是希望灵活一点的自定义的配置,则可参考如下json配置:
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"connection": [
{
"querySql": [
"select db_id,on_line_flag from db_info where db_id < 10;"
],
"jdbcUrl": [
"jdbc:mysql://bad_ip:3306/database",
"jdbc:mysql://127.0.0.1:bad_port/database",
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
}
}
]
}
}
四、拓展
1.调度
任务很少,情景简单的情况下,使用Linux自带的corntab即可,当然,正常的时候推荐使用调度平台
这里推荐airflow(其他相关的azkaban、oozie等调度不展开)
【dataX】阿里开源ETL工具——dataX简单上手的更多相关文章
- 【转】阿里出品的ETL工具dataX初体验
原文链接:https://www.imooc.com/article/15640 来源:慕课网 我的毕设选择了大数据方向的题目.大数据的第一步就是要拿到足够的数据源.现实情况中我们需要的数据源分布在不 ...
- 开源ETL工具kettle系列之常见问题
开源ETL工具kettle系列之常见问题 摘要:本文主要介绍使用kettle设计一些ETL任务时一些常见问题,这些问题大部分都不在官方FAQ上,你可以在kettle的论坛上找到一些问题的答案 1. J ...
- ETL工具Datax、sqoop、kettle 的区别
一.Sqoop主要特点: 1.可以将关系型数据库中的数据导入到hdfs,hive,hbase等hadoop组件中,也可以将hadoop组件中的数据导入到关系型数据库中: 2.sqoop在导入导出数据时 ...
- 开源ETL工具之Kettle介绍
What 起源 Kettle是一个Java编写的ETL工具,主作者是Matt Casters,2003年就开始了这个项目,最新稳定版为7.1. 2005年12月,Kettle从2.1版本开始进入了开源 ...
- 开源ETL工具kettle--数据迁移
背景 因为项目的需求,须要将数据从Oracle迁移到MSSQL,不是简单的数据复制,而是表结构和字段名都不一样.甚至须要处理编码规范不一致的情况,例如以下图所看到的 watermark/2/text/ ...
- 初识阿里开源诊断工具Arthas
上个月,阿里开源了一个名为Arthas的监控工具.恰逢近期自己在写多线程处理业务,由此想到了一个问题. 如果在本机开发调试,IDE可以看到当前的活动线程,例如IntelliJ IDEA,线程是运行还是 ...
- 阿里ETL工具datax学习(一)
阿里云开源离线同步工具DataX3.0介绍 一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.Ma ...
- 开源作业调度工具实现开源的Datax、Sqoop、Kettle等ETL工具的作业批量自动化调度
1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳 ...
- ETL工具框架开源软件
http://www.oschina.net/project/tag/453/etl 开源ETL工具 Kettle Talend KETL CloverETL Apatar Scriptella ET ...
随机推荐
- docker-使用Dockerfile制作镜像
最近项目中有使用docker,组内做了关于docker的培训,然后自己跟着研究了一下,大概了解如何使用.我是基于tomcat镜像制作(不需要安装jdk,配置环境变量),基于centos镜像制作需要安装 ...
- 《Inside C#》笔记(十三) 多线程 上
通过将一个任务划分成多个任务分别在独立的线程执行可以更有效地利用处理器资源并节省时间.但如果不合理地使用多线程,反而会带来种种问题并拖慢运行速度. 一 线程基础 a)线程与多任务 一个线程就是一个处理 ...
- Android Studio:Support Library依赖包的版本号
当我们用RecyclerView时,如果想用某一个特定的版本,怎样才能知道版本号呢?如果自己的笔记本中用过这个库,那么会保存在本地硬盘中. Android自身依赖包的版本号本地存放路径: 没有用过该 ...
- matlab练习程序(FAST特征点检测)
算法思想:如果一个像素与它邻域的像素差别较大(过亮或过暗) , 那它更可能是角点. 算法步骤: 1.上图所示,一个以像素p为中心,半径为3的圆上,有16个像素点(p1.p2.....p16). 2.定 ...
- go 实现简单的加权分配
最近一段时间接手了一个golang编写的模块,从python转到golang这种静态语言还是有些不适应的,接手模块后的第一个需求是实现一个加权分配的方法. 简单来说数据库中存有3个链接,3个链接的权重 ...
- Error: spawn Unknown system errno 203
在用node写代码的时候发现这个错误,google之无解,现在解决,发于此. 事件起因为一个全局模块通过子进程(chind_process)调用另一个全局模块的命令,这个错误就是在命令行通过全局命令调 ...
- 反射型XSS+文件上传+CSRF—DVWA
在学习的过程中,想到将几种漏洞进行组合练习,记录下学习过程.大佬请绕过!谢谢!! 测试环境:DVWA,安装方法参考上一篇:https://www.cnblogs.com/aq-ry/p/9220584 ...
- 开启远程Windows系统3389端口
1.Win7.Win2003.XP系统REG ADD HKLM\SYSTEM\CurrentControlSet\Control\Terminal" "Server /v fDen ...
- iOS解析XML实现省市区选择
1.具体内容就不再赘述了.直接看关键代码. viewController.h // // ViewController.h // ParseXmlToRealizeChooseCityDemo // ...
- Alpha版本 - 展示博客
Alpha版本 - 展示博客 S.W.S.D 成员简介 演示动态图 注册 登录 新建记录 分享记录 修改主页时间查看记录 文章模块 流星模块 修改用户信息(以头像为例) 用户使用概况 预期的典型用户 ...