access十万级数据分页
最近的一个项目采用winform+access,但后来发现客户那边的数据量比较大,有数十万条数据。用sql语句进行分页,每次翻页加载都需要8秒钟左右,实在难以忍受。
后来百度了一下,发现一篇文章我的Access百万数据分页,按照其中提供的思路,修改了一下,每次翻页需要2.5秒左右,勉强可以接受了。
1、添加ADODB引用,我这里用的是ADODB 2.8
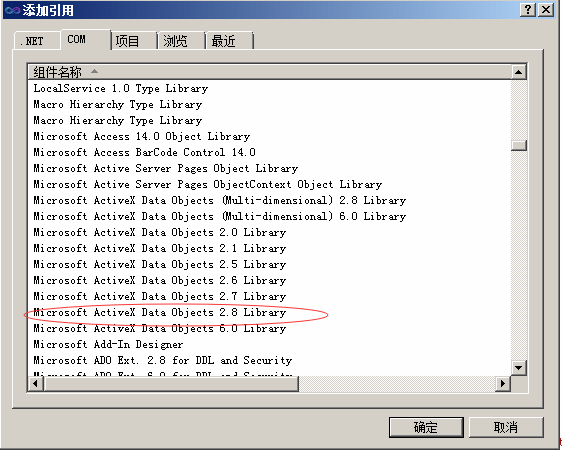
2、分页记录获取函数如下,此函数仅返回主键Id,然后再用select * from tb where id in (主键id)绑定分页数据
private string[] GetPageRecordId(string sql, int pageIndex, int pageSize)
{
string[] retStr = new string[2];
ADODB.Recordset rs = new ADODB.Recordset(); rs.Open(sql, AccessDbClass.ConnString, ADODB.CursorTypeEnum.adOpenKeyset, ADODB.LockTypeEnum.adLockReadOnly, 1); int count = rs.RecordCount; if (count > 0)
{
rs.AbsolutePosition = (ADODB.PositionEnum)((pageIndex - 1) * pageSize + 1);
retStr[0] = rs.GetString(ADODB.StringFormatEnum.adClipString, pageSize, ",", ",", "").TrimEnd(',');
retStr[1] = rs.RecordCount.ToString();
}
else
{
retStr[0] = "0";
retStr[1] = "0";
} rs.Close();
return retStr;
}
access十万级数据分页的更多相关文章
- Access大数据高效分页语句
Access大数据高效分页语句 oracle的分页查询可以利用rowid伪列. db2的分页查询可以利用row_number() over()聚合函数. mysql有limit. access仿佛先天 ...
- limit 百万级数据分页优化方法
mysql教程 这个数据库教程绝对是适合dba级的高手去玩的,一般做一点1万 篇新闻的小型系统怎么写都可以,用xx框架可以实现快速开发.可是数据量到了10万,百万至千万,他的性能还能那么高吗? 一点小 ...
- mysql百万级数据分页查询缓慢优化-实战
作为后端攻城狮,在接到分页list需求的时候,内心是这样的 画面是这样的 代码大概是这样的 select count(id) from … 查出总数 select * from …. li ...
- MySQL百万级数据分页查询及优化
方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N 适应场景: 适用于数据量较少的情况(元组百/千级) 原因/缺 ...
- MySQL全面瓦解21(番外):一次深夜优化亿级数据分页的奇妙经历
背景 1月22号晚上10点半,下班后愉快的坐在在回家的地铁上,心里想着周末的生活怎么安排. 突然电话响了起来,一看是我们的一个开发同学,顿时紧张了起来,本周的版本已经发布过了,这时候打电话一般来说是线 ...
- C# 几十万级数据导出Excel,及Excel各种操作
先上导出代码 /// <summary> /// 导出速度最快 /// </summary> /// <param name="list">&l ...
- sql 百万级或千万级数据分页处理
笔记来源 https://blog.csdn.net/zhenyuanjie/article/details/7778102
- mysql百万级分页优化
普通分页 数据分页在网页中十分多见,分页一般都是limit start,offset,然后根据页码page计算start , 这种分页在几十万的时候分页效率就会比较低了,MySQL需要从头开始一直往后 ...
- Mysql分页查询性能分析
[PS:原文手打,转载说明出处,博客园] 前言 看过一堆的百度,最终还是自己做了一次实验,本文基于Mysql5.7.17版本,Mysql引擎为InnoDB,编码为utf8,排序规则为utf8_gene ...
随机推荐
- 『TensorFlow』分类问题与两种交叉熵
关于categorical cross entropy 和 binary cross entropy的比较,差异一般体现在不同的分类(二分类.多分类等)任务目标,可以参考文章keras中两种交叉熵损失 ...
- HTML5 FormData方法介绍
详细见链接 转载说明:转自CSDN上“诗渊”的博客
- Python *Mix_w
Python的历史起源: 1989年圣诞节期间,由吉多.范罗苏姆创始. Python的优点"优美""明确""简单" python是一门解释型 ...
- MVC跨域API
API using System;using System.Collections.Generic;using System.Linq;using System.Net;using System.Ne ...
- Linux目录结构下部
第1章 linux目录结构 (linux必知必会的文件或目录) 1.1 在linux下面如何安装软件 yum install tree 1.2 linux无法上网了怎么办? [root@oldboye ...
- Beta 冲刺 (6/7)
Beta 冲刺 (6/7) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务 文字/口头描述 组织会议 开发wxpy部分功能 展示G ...
- 开发方式-----C语言
上期我们已经把C语言的开发平台搭建好了,还有不清楚地可以查看我上一篇的笔记,这次我们就要进行编辑C语言,那么它到底是怎么实现开发的呢?这一期我就来演示一次开发方式,至于说明为什么会这样或者这个是什么意 ...
- 2017-9-3模拟赛T1 卡片(card)
题目 [题目描述] lrb 喜欢玩卡牌.他手上现在有n张牌,每张牌的颜色为红绿蓝中的一种.现在他有两种操作.一是可以将两张任意位置的不同色的牌换成一张第三种颜色的牌:二是可以将任意位置的两张相同颜色的 ...
- Linux目录路径知识
改IP为静态IP
- Java学习笔记43(Spring的jdbc模板)
在之前的学习中,我们执行sql语句,需要频繁的开流,关流比较麻烦,为了更加的简化代码,我们使用Spring 的jdbc模板jdbcTemplate来简化我们的代码量:需要导入的包有: 我们在之前的dr ...