协程与concurent.furtrue实现线程池与进程池
1concurent.furtrue实现线程池与进程池
2协程
1concurent.furtrue实现线程池与进程池
实现进程池
#进程池
from concurrent.futures import ProcessPoolExecutor
import os,time,random
def task(n):
print('%s is running' %os.getpid())
time.sleep(2)
return n**2 if __name__ == '__main__':
p=ProcessPoolExecutor()#实例化
l=[]
start=time.time()
for i in range(10):
obj=p.submit(task,i)
l.append(obj)
p.shutdown()
print('='*30)
# print([obj for obj in l])
print([obj.result() for obj in l])
print(time.time()-start)
线程池
from concurrent.futures import ThreadPoolExecutor
import threading
import os,time,random
def task(n):
print('%s:%s is running' %(threading.currentThread().getName(),os.getpid()))
time.sleep(2)#相当于I/O操作
return n**2 if __name__ == '__main__':
p=ThreadPoolExecutor()
l=[]
start=time.time()
for i in range(10):
obj=p.submit(task,i)#返回的obj是一个对象,需要用rusult()取出
l.append(obj)
p.shutdown()#相当于close和join方法一起用的
print('='*30)
print([obj.result() for obj in l])
print(time.time()-start)
不管是线程还是进程都可以使用:# p.submit(task,i).result()即同步执行例如:
# p.submit(task,i).result()即同步执行
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os,time,random
def task(n):
print('%s is running' %os.getpid())
time.sleep(2)
return n**2 if __name__ == '__main__':
p=ProcessPoolExecutor()
start=time.time()
for i in range(10):
res=p.submit(task,i).result()#这种方法耗时比较多,不推荐使用
print(res)
print('='*30)
print(time.time()-start)
map方法
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os,time,random
def task(n):
print('%s is running' %os.getpid())
time.sleep(2)
return n**2 if __name__ == '__main__':
p=ProcessPoolExecutor()
obj=p.map(task,range(10))
p.shutdown()
print('='*30)
print(list(obj))#map方法需要用list
回调函数
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import requests
import os
import time
from threading import currentThread
def get_page(url):
print('%s:<%s> is getting [%s]' %(currentThread().getName(),os.getpid(),url))
response=requests.get(url)
time.sleep(2)
return {'url':url,'text':response.text}
def parse_page(res):
res=res.result()#返回的是一个一个对象需要得到值,
print('%s:<%s> parse [%s]' %(currentThread().getName(),os.getpid(),res['url']))
with open('db.txt','a') as f:
parse_res='url:%s size:%s\n' %(res['url'],len(res['text']))
f.write(parse_res)
if __name__ == '__main__':
# p=ProcessPoolExecutor()
p=ThreadPoolExecutor()
urls = [
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
] for url in urls:
# multiprocessing.pool_obj.apply_async(get_page,args=(url,),callback=parse_page)
p.submit(get_page, url).add_done_callback(parse_page)
p.shutdown()
print('主',os.getpid())
2.协程
引子:
本节主题是实现单线程下的并发,即只在一个主线程,并且很明显的是,可利用的cpu只有一个情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长。我们希望程序一直在运行状态或者就绪状态而不是在阻塞状态。
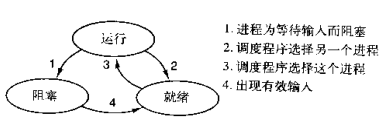
是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
#2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
#2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
Greenlet
如果我们在单个线程内有20个任务,要想实现在多个任务之间切换,使用yield生成器的方式过于麻烦(需要先得到初始化一次的生成器,然后再调用send。。。非常麻烦),而使用greenlet模块可以非常简单地实现这20个任务直接的切换
from greenlet import greenlet
import time
def eat(name):
print('%s eat 1' %name)
time.sleep(10)
g2.switch('egon')
print('%s eat 2' %name)
g2.switch()
def play(name):
print('%s play 1' %name)
g1.switch()
print('%s play 2' %name) g1=greenlet(eat)
g2=greenlet(play) g1.switch('egon')#可以在第一次switch时传入参数,以后都不需要
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度
#顺序执行
import time
def f1():
res=1
for i in range(100000000):
res+=i def f2():
res=1
for i in range(100000000):
res*=i start=time.time()
f1()
f2()
stop=time.time()
print('run time is %s' %(stop-start)) #10.985628366470337 #切换
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch() def f2():
res=1
for i in range(100000000):
res*=i
g1.switch() start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print('run time is %s' %(stop-start)) # 52.763017892837524
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块。
from gevent import monkey;monkey.patch_all()#补丁
import gevent
import time
def eat(name):
print('%s eat 1' %name)
time.sleep(2)
print('%s eat 2' %name)
return 'eat' def play(name):
print('%s play 1' %name)
time.sleep(3)
print('%s play 2' %name)
return 'play' start=time.time()
g1=gevent.spawn(eat,'egon')#传入参数
g2=gevent.spawn(play,'egon')#传入参数
# g1.join()
# g2.join()
gevent.joinall([g1,g2])
print('主',(time.time()-start))
print(g1.value)
print(g2.value)
#爬虫应用
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time def get_page(url):
print('GET: %s' %url)
response=requests.get(url)
if response.status_code == 200:
print('%d bytes received from %s' %(len(response.text),url)) start_time=time.time() # get_page('https://www.python.org/')
# get_page('https://www.yahoo.com/')
# get_page('https://github.com/') g1=gevent.spawn(get_page, 'https://www.python.org/')#传入参数
g2=gevent.spawn(get_page, 'https://www.yahoo.com/')
g3=gevent.spawn(get_page, 'https://github.com/') gevent.joinall([g1,g2,g3])
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
用协程实现服务端与客户端
服务端
from gevent import monkey;monkey.patch_all()
import gevent
from socket import *
def talk(conn,addr):
while True:
data=conn.recv(1024)
print('%s:%s %s' %(addr[0],addr[1],data))
conn.send(data.upper())
conn.close() def server(ip,port):
s = socket(AF_INET, SOCK_STREAM)
s.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
s.bind((ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
gevent.spawn(talk,conn,addr)
s.close() if __name__ == '__main__':
server('127.0.0.1', 8088)
客户端
from multiprocessing import Process
from socket import *
def client(server_ip,server_port):
client=socket(AF_INET,SOCK_STREAM)
client.connect((server_ip,server_port))
while True:
client.send('hello'.encode('utf-8'))
msg=client.recv(1024)
print(msg.decode('utf-8')) if __name__ == '__main__':
for i in range(500):
p=Process(target=client,args=('127.0.0.1',8088))
p.start()
协程与concurent.furtrue实现线程池与进程池的更多相关文章
- Python 线程池,进程池,协程,和其他
本节内容 线程池 进程池 协程 try异常处理 IO多路复用 线程的继承调用 1.线程池 线程池帮助你来管理线程,不再需要每个任务都创建一个线程进行处理任务. 任务需要执行时,会从线程池申请线程,有则 ...
- 线程池、进程池(concurrent.futures模块)和协程
一.线程池 1.concurrent.futures模块 介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 Pro ...
- python爬虫之线程池和进程池
一.需求 最近准备爬取某电商网站的数据,先不考虑代理.分布式,先说效率问题(当然你要是请求的太快就会被封掉,亲测,400个请求过去,服务器直接拒绝连接,心碎),步入正题.一般情况下小白的我们第一个想到 ...
- 多进程 multiprocessing 多线程Threading 线程池和进程池concurrent.futures
multiprocessing.procsess 定义一个函数 def func():pass 在if __name__=="__main__":中实例化 p = process( ...
- python之线程池和进程池
线程池和进程池 一.池的概念 池是用来保证计算机硬件安全的情况下最大限度的利用计算机 它降低了程序的运行效率但是保证了计算机硬件的安全从而让你写的程序能够正常运行 ''' 无论是开设进程也好还是开设线 ...
- 使用concurrent.futures模块中的线程池与进程池
使用concurrent.futures模块中的线程池与进程池 线程池与进程池 以线程池举例,系统使用多线程方式运行时,会产生大量的线程创建与销毁,创建与销毁必定会带来一定的消耗,甚至导致系统资源的崩 ...
- concurrent.futures模块简单介绍(线程池,进程池)
一.基类Executor Executor类是ThreadPoolExecutor 和ProcessPoolExecutor 的基类.它为我们提供了如下方法: submit(fn, *args, ** ...
- Python线程池与进程池
Python线程池与进程池 前言 前面我们已经将线程并发编程与进程并行编程全部摸了个透,其实我第一次学习他们的时候感觉非常困难甚至是吃力.因为概念实在是太多了,各种锁,数据共享同步,各种方法等等让人十 ...
- day 7-7 线程池与进程池
一. 进程池与线程池 在刚开始学多进程或多线程时,我们迫不及待地基于多进程或多线程实现并发的套接字通信,然而这种实现方式的致命缺陷是:服务的开启的进程数或线程数都会随着并发的客户端数目地增多而增多,这 ...
随机推荐
- 使用centos 7安装conpot
使用CentOS的版本7.3和Conpot 0.5.1(也可能适用于其他CentOS的版本) 1.通过ssh登录系统,并需要具有足够的系统特权(e.g root) 2.系统升级 yum -y upda ...
- 用Redis作Mysql数据库缓存
使用redis作mysql数据库缓存时,需要考虑两个问题: 1.确定用何种数据结构存储来自Mysql的数据; 2.在确定数据结构之后,用什么标识作为该数据结构的键. 直观上看,Mysql中的数据都是按 ...
- shiro教程2(自定义Realm)
通过shiro教程1我们发现仅仅将数据源信息定义在ini文件中与我们实际开发环境有很大不兼容,所以我们希望能够自定义Realm. 自定义Realm的实现 创建自定义Realmjava类 创建一个jav ...
- [NOI 2015]品酒大会
Description 题库链接 \(n\) 杯鸡尾酒排成一行,其中第 \(i\) 杯酒 (\(1 \leq i \leq n\)) 被贴上了一个标签 \(s_i\),每个标签都是 \(26\) 个小 ...
- Modbus通信协议 【 初识 Modbus】
Modbus协议 Modbus 协议是应用于电子控制器上的一种通用语言.通过此协议,控制器相互之间.控制器经由网络(例如以太网)和其它设备之间可以通信.它已经成为一通用工业标准.有了它,不同厂 ...
- LINQ 小项目【组合查询、分页】
使用 linq 在网页上对用户信息增删改,组合查询,分页显示 using System; using System.Collections.Generic; using System.Linq; us ...
- 转STM32官方固件库简介
ST(意法半导体)为了方便用户开发程序,提供了一套丰富的 STM32 固件库.固件库就是函数的集合,固件库函数的作用是向下负责与寄存器直接打交道,向上提供用户函数调用的接口(API) .固件库将这些寄 ...
- csharp: sum columns or rows in a dataTable
DataTable dt = setData(); // Sum rows. //foreach (DataRow row in dt.Rows) //{ // int rowTotal = 0; / ...
- SAP MM 并非奇怪现象之MB5B报表查不到某一笔出库记录?
物料号:1301002696 工厂代码:2160 MB5B,如下查询条件, 查询结果中,期初与期末库存数量都是0,期间的出库入库数量都是0.事实上该物料期初应该是有库存的.并且我用MB51相同时间段查 ...
- java enum使用方法
直接上手吧,注释都写清楚了 编写枚举类 /** * 可以使用接口或类包裹枚举元素,使其可以统一调用入口 */ public interface TestEnumIntfc { /** * 创建枚举对象 ...