Spark SQL 性能优化再进一步:CBO 基于代价的优化
摘要: 本文将介绍 CBO,它充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan。
Spark CBO 背景
上文Spark SQL 内部原理中介绍的 Optimizer 属于 RBO,实现简单有效。它属于 LogicalPlan 的优化,所有优化均基于 LogicalPlan 本身的特点,未考虑数据本身的特点,也未考虑算子本身的代价。
本文将介绍 CBO,它充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan。
Spark CBO 原理
CBO 原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。其核心在于评估一个给定的物理执行计划的代价。
物理执行计划是一个树状结构,其代价等于每个执行节点的代价总合,如下图所示。
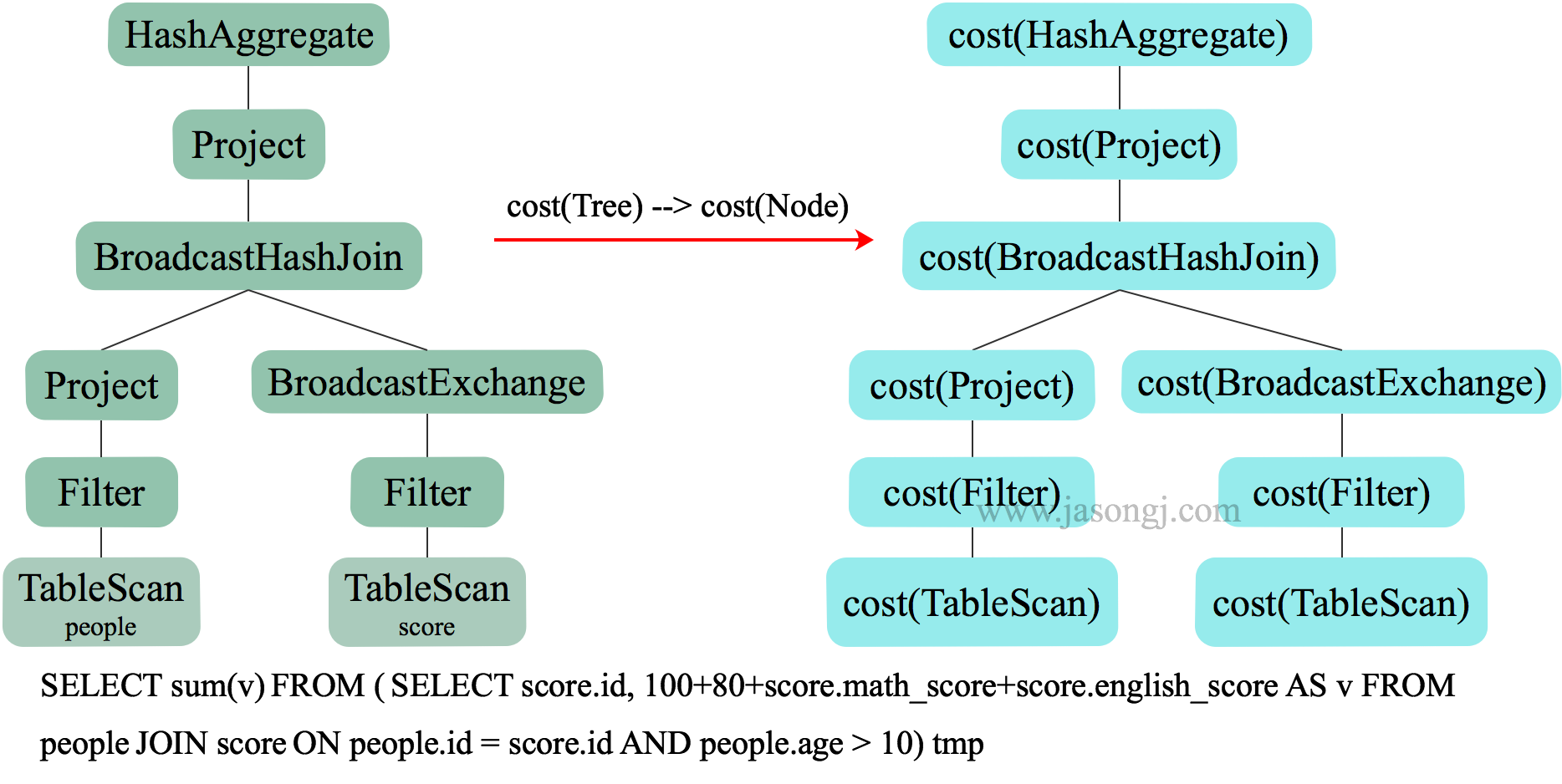
而每个执行节点的代价,分为两个部分
- 该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:1) 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;2)中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
所以,最终主要需要解决两个问题
- 如何获取原始数据集的统计信息
- 如何根据输入数据集估算特定算子的输出数据集
Statistics 收集
通过如下 SQL 语句,可计算出整个表的记录总数以及总大小
1 |
ANALYZE TABLE table_name COMPUTE STATISTICS; |
从如下示例中,Statistics 一行可见, customer 表数据总大小为 37026233 字节,即 35.3MB,总记录数为 28万,与事实相符。
1234567891011121314151617181920212223242526272829303132333435363738394041 |
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS;Time taken: 12.888 seconds spark-sql> desc extended customer;c_customer_sk bigint NULLc_customer_id string NULLc_current_cdemo_sk bigint NULLc_current_hdemo_sk bigint NULLc_current_addr_sk bigint NULLc_first_shipto_date_sk bigint NULLc_first_sales_date_sk bigint NULLc_salutation string NULLc_first_name string NULLc_last_name string NULLc_preferred_cust_flag string NULLc_birth_day int NULLc_birth_month int NULLc_birth_year int NULLc_birth_country string NULLc_login string NULLc_email_address string NULLc_last_review_date string NULL # Detailed Table InformationDatabase jason_tpc_dsTable customerOwner jasonCreated Time Sat Sep 15 14:00:40 CST 2018Last Access Thu Jan 01 08:00:00 CST 1970Created By Spark 2.3.2Type EXTERNALProvider hiveTable Properties [transient_lastDdlTime=1536997324]Statistics 37026233 bytes, 280000 rowsLocation hdfs://dw/tpc_ds/customerSerde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeInputFormat org.apache.hadoop.mapred.TextInputFormatOutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatStorage Properties [field.delim=|, serialization.format=|]Partition Provider CatalogTime taken: 1.691 seconds, Fetched 36 row(s) |
通过如下 SQL 语句,可计算出指定列的统计信息
1 |
ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS [column1] [,column2] [,column3] [,column4] ... [,columnn]; |
从如下示例可见,customer 表的 c_customer_sk 列最小值为 1, 最大值为 280000,null 值个数为 0,不同值个数为 274368,平均列长度为 8,最大列长度为 8。
12345678910111213 |
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS FOR COLUMNS c_customer_sk, c_customer_id, c_current_cdemo_sk;Time taken: 9.139 secondsspark-sql> desc extended customer c_customer_sk;col_name c_customer_skdata_type bigintcomment NULLmin 1max 280000num_nulls 0distinct_count 274368avg_col_len 8max_col_len 8histogram NULL |
除上述示例中的统计信息外,Spark CBO 还直接等高直方图。在上例中,histogram 为 NULL。其原因是,spark.sql.statistics.histogram.enabled 默认值为 false,也即 ANALYZE 时默认不计算及存储 histogram。
下例中,通过 SET spark.sql.statistics.histogram.enabled=true; 启用 histogram 后,完整的统计信息如下。
1234567891011121314151617181920212223 |
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS FOR COLUMNS c_customer_sk,c_customer_id,c_current_cdemo_sk,c_current_hdemo_sk,c_current_addr_sk,c_first_shipto_date_sk,c_first_sales_date_sk,c_salutation,c_first_name,c_last_name,c_preferred_cust_flag,c_birth_day,c_birth_month,c_birth_year,c_birth_country,c_login,c_email_address,c_last_review_date;Time taken: 125.624 seconds spark-sql> desc extended customer c_customer_sk;col_name c_customer_skdata_type bigintcomment NULLmin 1max 280000num_nulls 0distinct_count 274368avg_col_len 8max_col_len 8histogram height: 1102.3622047244094, num_of_bins: 254bin_0 lower_bound: 1.0, upper_bound: 1090.0, distinct_count: 1089bin_1 lower_bound: 1090.0, upper_bound: 2206.0, distinct_count: 1161bin_2 lower_bound: 2206.0, upper_bound: 3286.0, distinct_count: 1124 ... bin_251 lower_bound: 276665.0, upper_bound: 277768.0, distinct_count: 1041bin_252 lower_bound: 277768.0, upper_bound: 278870.0, distinct_count: 1098bin_253 lower_bound: 278870.0, upper_bound: 280000.0, distinct_count: 1106 |
从上图可见,生成的 histogram 为 equal-height histogram,且高度为 1102.36,bin 数为 254。其中 bin 个数可由 spark.sql.statistics.histogram.numBins 配置。对于每个 bin,匀记录其最小值,最大值,以及 distinct count。
值得注意的是,这里的 distinct count 并不是精确值,而是通过 HyperLogLog 计算出来的近似值。使用 HyperLogLog 的原因有二
- 使用 HyperLogLog 计算 distinct count 速度快速
- HyperLogLog 计算出的 distinct count 可以合并。例如可以直接将两个 bin 的 HyperLogLog 值合并算出这两个 bin 总共的 distinct count,而无须从重新计算,且合并结果的误差可控
算子对数据集影响估计
对于中间算子,可以根据输入数据集的统计信息以及算子的特性,可以估算出输出数据集的统计结果。
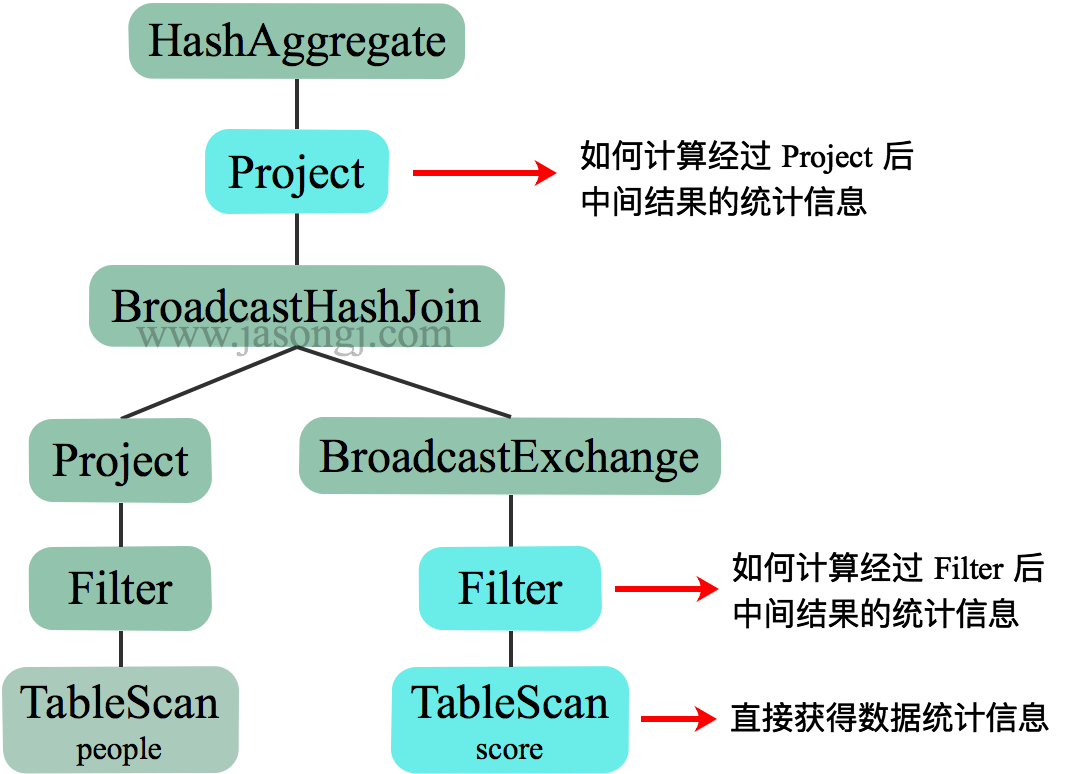
本节以 Filter 为例说明算子对数据集的影响。
对于常见的 Column A < value B Filter,可通过如下方式估算输出中间结果的统计信息
- 若 B < A.min,则无数据被选中,输出结果为空
- 若 B > A.max,则全部数据被选中,输出结果与 A 相同,且统计信息不变
- 若 A.min < B < A.max,则被选中的数据占比为 (B.value - A.min) / (A.max - A.min),A.min 不变,A.max 更新为 B.value,A.ndv = A.ndv * (B.value - A.min) / (A.max - A.min)
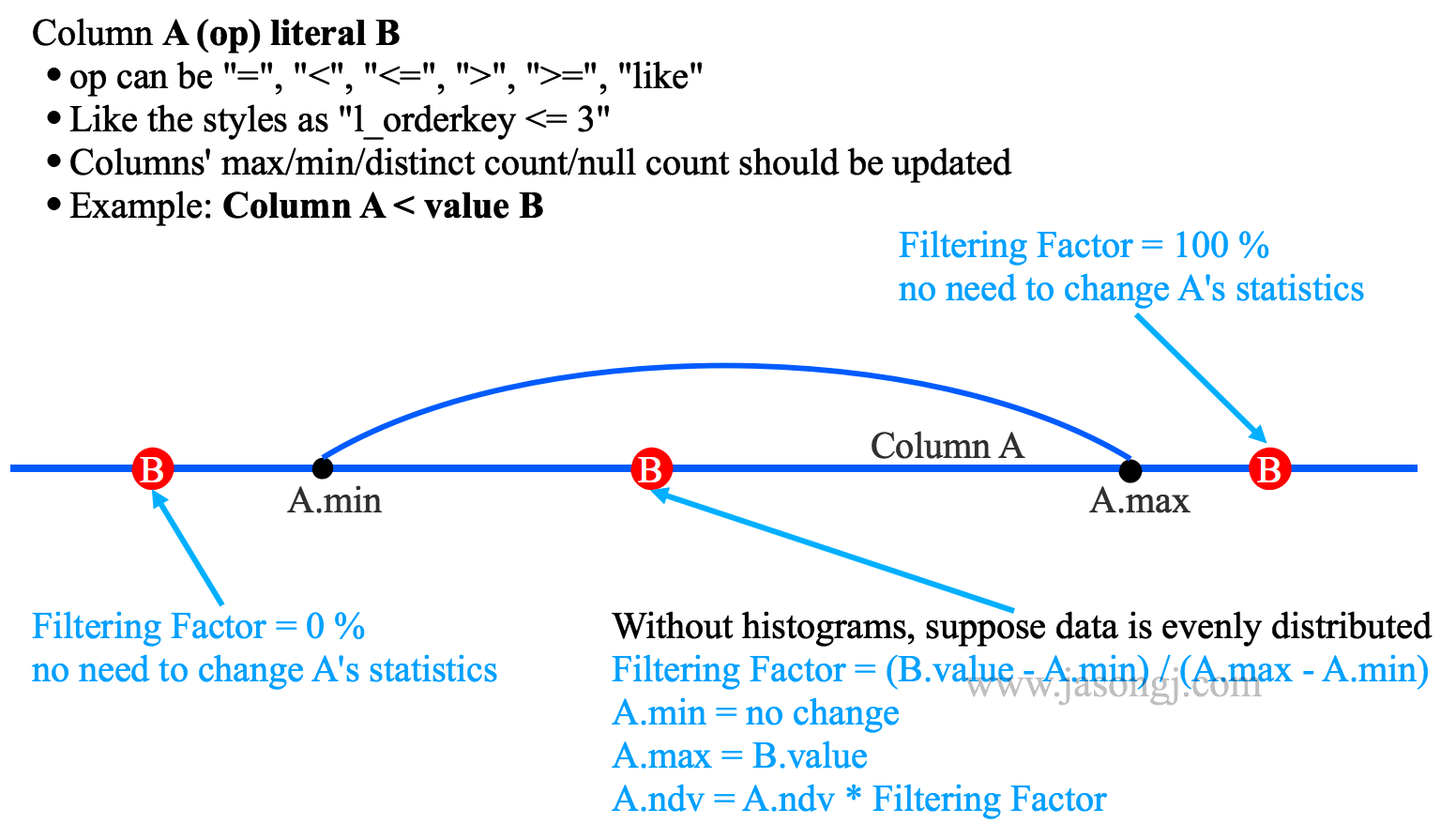
上述估算的前提是,字段 A 数据均匀分布。但很多时候,数据分布并不均匀,且当数据倾斜严重是,上述估算误差较大。此时,可充分利用 histogram 进行更精确的估算
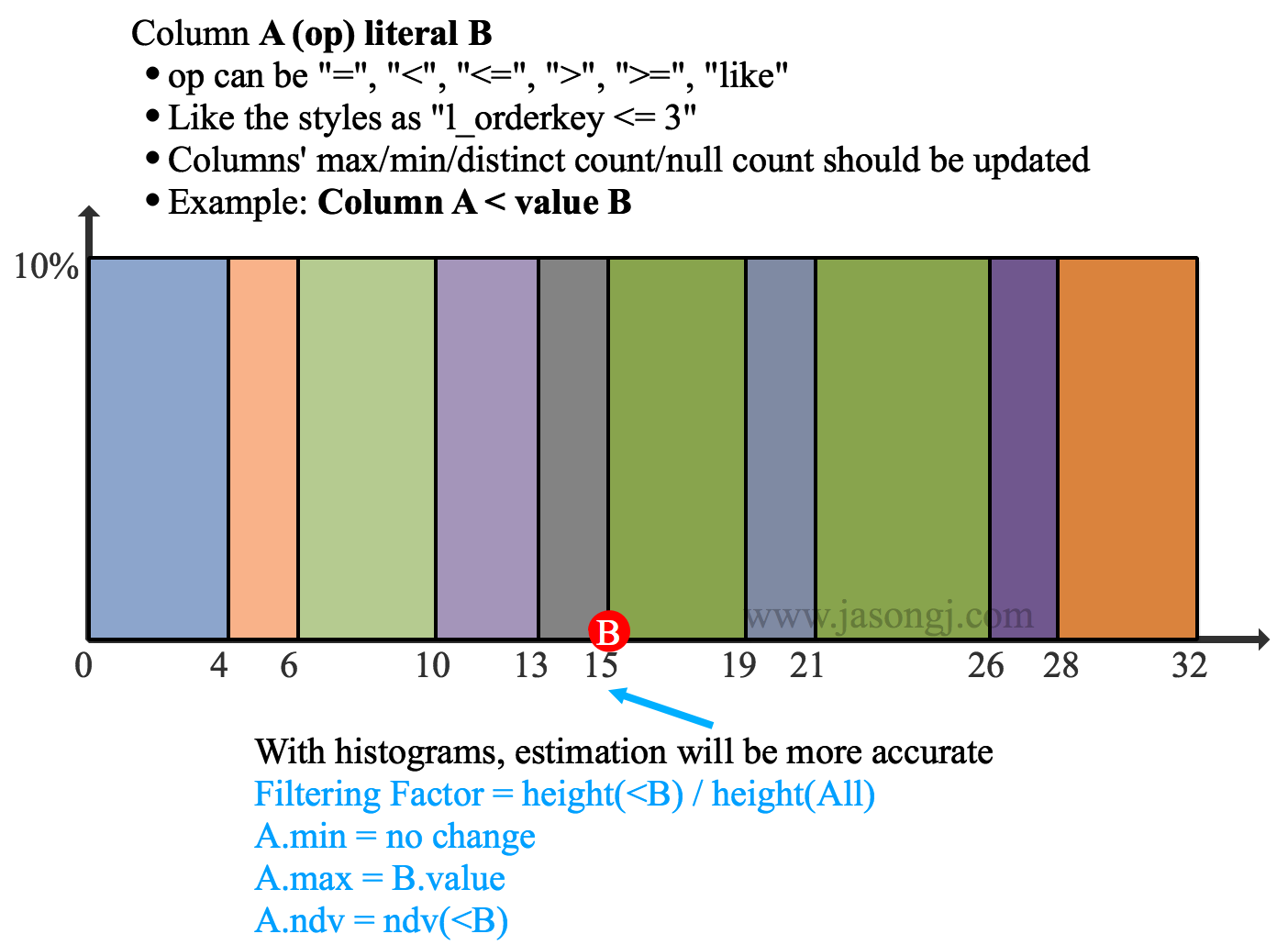
启用 Historgram 后,Filter Column A < value B的估算方法为
- 若 B < A.min,则无数据被选中,输出结果为空
- 若 B > A.max,则全部数据被选中,输出结果与 A 相同,且统计信息不变
- 若 A.min < B < A.max,则被选中的数据占比为 height(<B) / height(All),A.min 不变,A.max = B.value,A.ndv = ndv(<B)
在上图中,B.value = 15,A.min = 0,A.max = 32,bin 个数为 10。Filter 后 A.ndv = ndv(<B.value) = ndv(<15)。该值可根据 A < 15 的 5 个 bin 的 ndv 通过 HyperLogLog 合并而得,无须重新计算所有 A < 15 的数据。
算子代价估计
SQL 中常见的操作有 Selection(由 select 语句表示),Filter(由 where 语句表示)以及笛卡尔乘积(由 join 语句表示)。其中代价最高的是 join。
Spark SQL 的 CBO 通过如下方法估算 join 的代价
12 |
Cost = rows * weight + size * (1 - weight)Cost = CostCPU * weight + CostIO * (1 - weight) |
其中 rows 即记录行数代表了 CPU 代价,size 代表了 IO 代价。weight 由 spark.sql.cbo.joinReorder.card.weight 决定,其默认值为 0.7。
Build侧选择
对于两表Hash Join,一般选择小表作为build size,构建哈希表,另一边作为 probe side。未开启 CBO 时,根据表原始数据大小选择 t2 作为build side
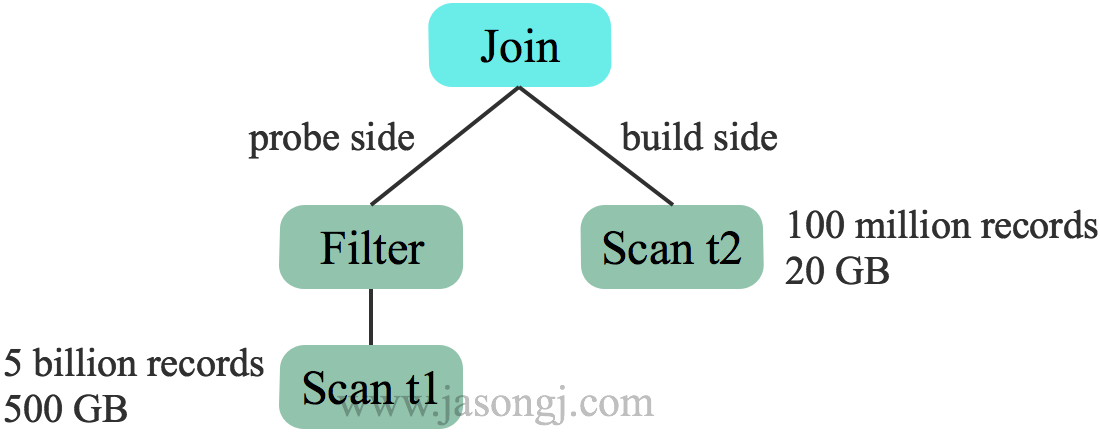
而开启 CBO 后,基于估计的代价选择 t1 作为 build side。更适合本例
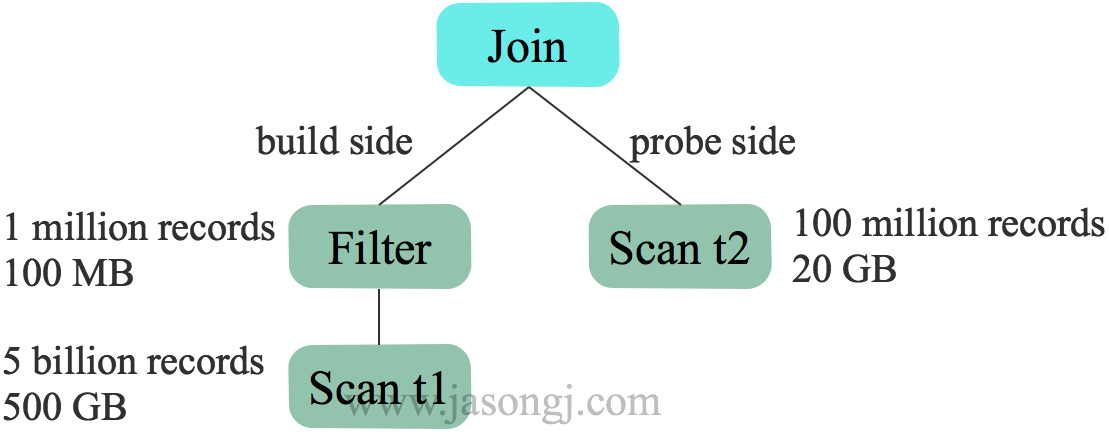
优化 Join 类型
在 Spark SQL 中,Join 可分为 Shuffle based Join 和 BroadcastJoin。Shuffle based Join 需要引入 Shuffle,代价相对较高。BroadcastJoin 无须 Join,但要求至少有一张表足够小,能通过 Spark 的 Broadcast 机制广播到每个 Executor 中。
在不开启 CBO 中,Spark SQL 通过 spark.sql.autoBroadcastJoinThreshold 判断是否启用 BroadcastJoin。其默认值为 10485760 即 10 MB。
并且该判断基于参与 Join 的表的原始大小。
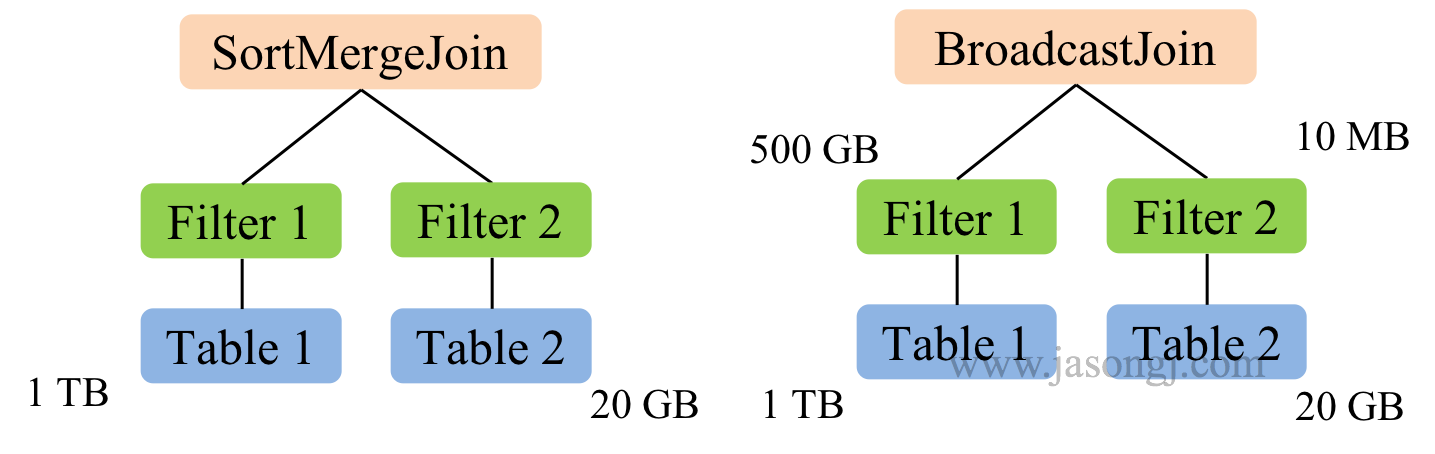
在下图示例中,Table 1 大小为 1 TB,Table 2 大小为 20 GB,因此在对二者进行 join 时,由于二者都远大于自动 BroatcastJoin 的阈值,因此 Spark SQL 在未开启 CBO 时选用 SortMergeJoin 对二者进行 Join。
而开启 CBO 后,由于 Table 1 经过 Filter 1 后结果集大小为 500 GB,Table 2 经过 Filter 2 后结果集大小为 10 MB 低于自动 BroatcastJoin 阈值,因此 Spark SQL 选用 BroadcastJoin。
优化多表 Join 顺序
未开启 CBO 时,Spark SQL 按 SQL 中 join 顺序进行 Join。极端情况下,整个 Join 可能是 left-deep tree。在下图所示 TPC-DS Q25 中,多路 Join 存在如下问题,因此耗时 241 秒。
- left-deep tree,因此所有后续 Join 都依赖于前面的 Join 结果,各 Join 间无法并行进行
- 前面的两次 Join 输入输出数据量均非常大,属于大 Join,执行时间较长
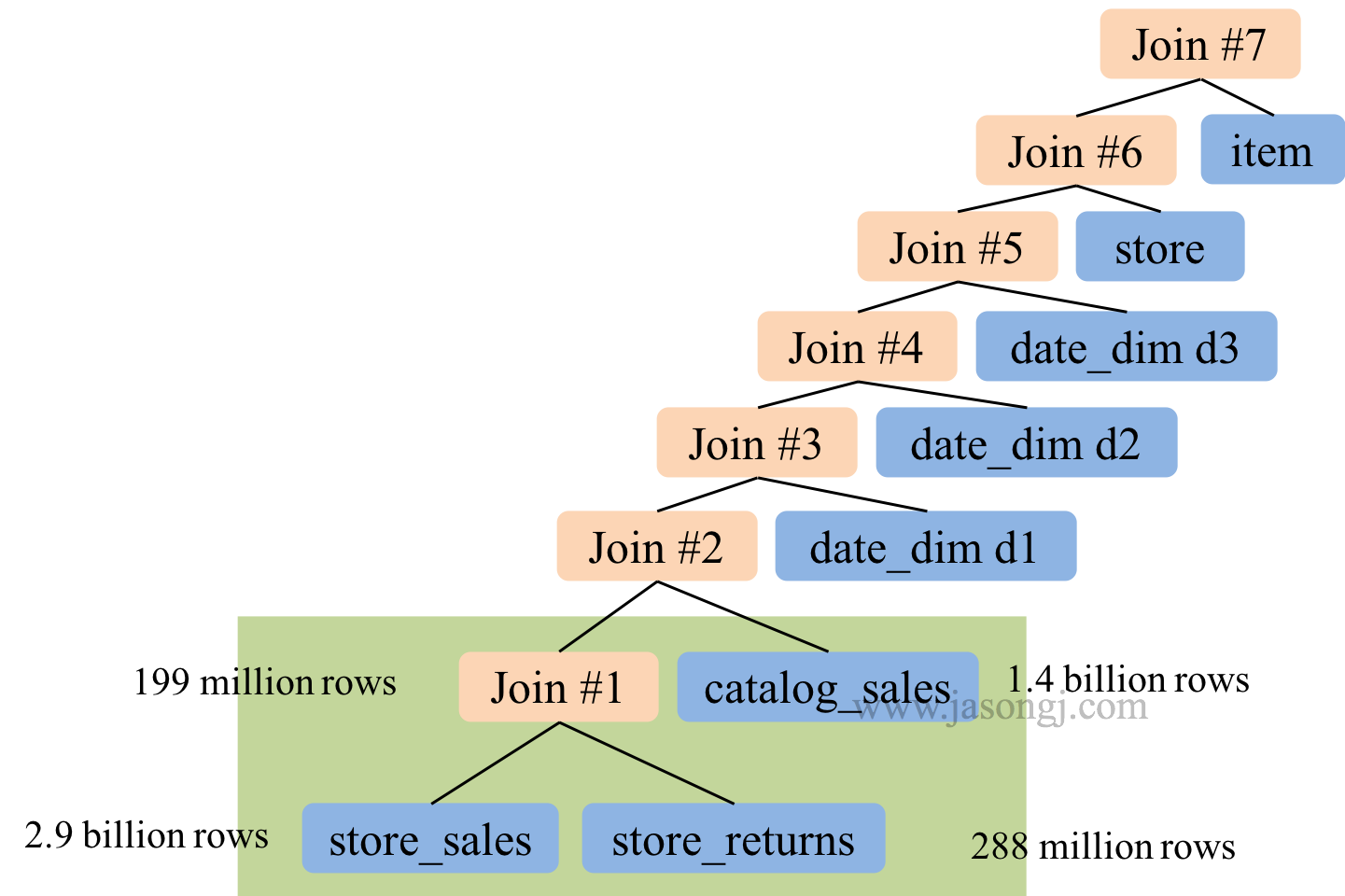
开启 CBO 后, Spark SQL 将执行计划优化如下
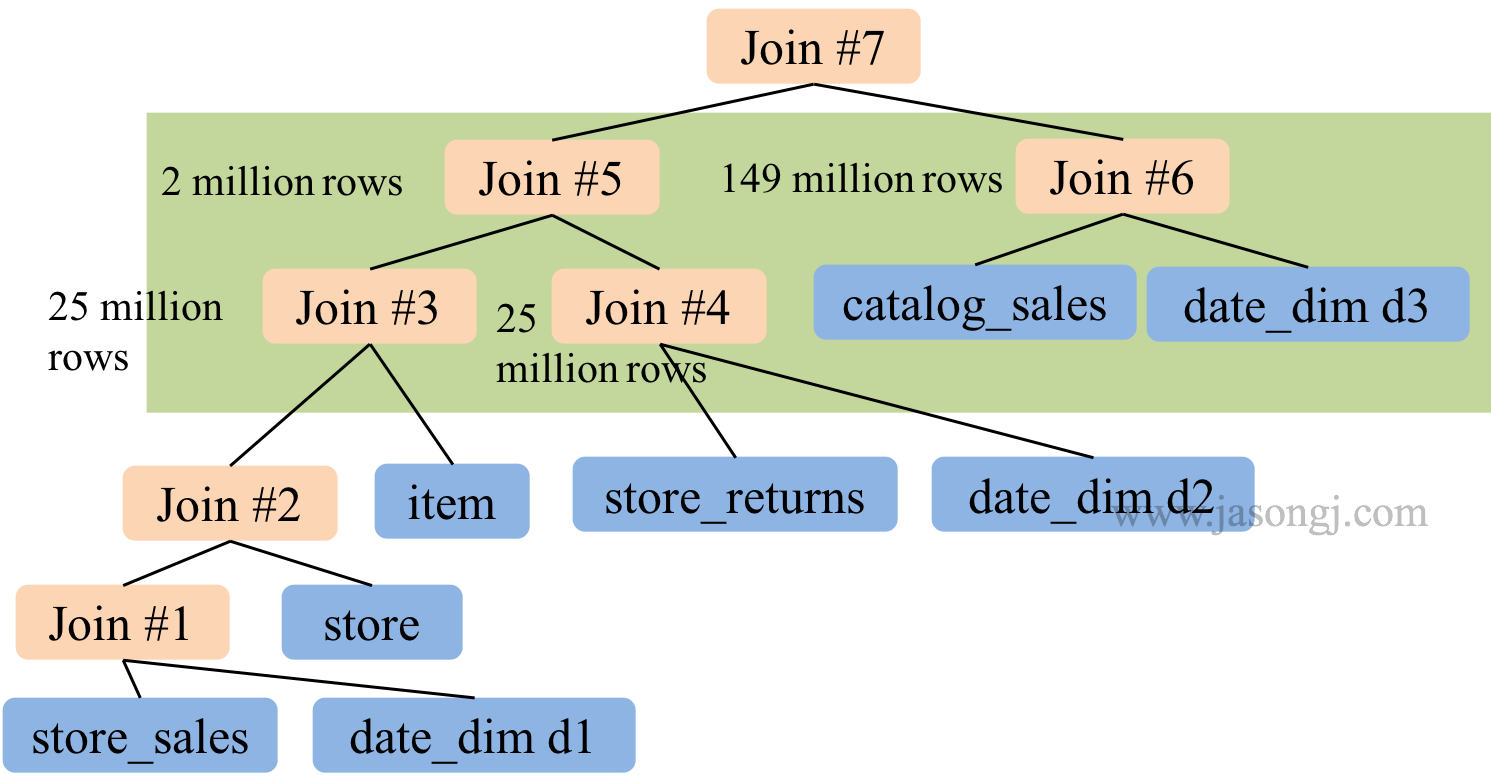
优化后的 Join 有如下优势,因此执行时间降至 71 秒
- Join 树不再是 left-deep tree,因此 Join 3 与 Join 4 可并行进行,Join 5 与 Join 6 可并行进行
- 最大的 Join 5 输出数据只有两百万条结果,Join 6 有 1.49 亿条结果,Join 7相当于小 Join
Spark SQL 性能优化再进一步:CBO 基于代价的优化的更多相关文章
- CBO 基于成本的优化器[基础]
转载:CBO基于成本的优化器 ----------------------------------2013/10/02 CBO基于成本的优化器:让oracle获取所有执行计划的相关信息,通过对这些信息 ...
- Spark SQL 代码简要阅读(基于Spark 1.1.0)
Spark SQL允许相关的查询如SQL,HiveQL或Scala运行在spark上.其核心组件是一个新的RDD:SchemaRDD,SchemaRDDs由行对象组成,并包含一个描述此行对象的每一列的 ...
- 一次 Spark SQL 性能提升10倍的经历(转载)
1. 遇到了啥问题 是酱紫的,简单来说:并发执行 spark job 的时候,并发的提速很不明显. 嗯,且听我慢慢道来,啰嗦点说,类似于我们内部有一个系统给分析师用,他们写一些 sql,在我们的 sp ...
- Adaptive Execution如何让Spark SQL更高效更好用
1 背 景 Spark SQL / Catalyst 和 CBO 的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性.但是 执行计划一旦生成,便不可更改,即使执行过程中发 ...
- 自适应查询执行:在运行时提升Spark SQL执行性能
前言 Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO.但是在这些版本中,Spark SQL执行计划一旦确定就不会改变.由于缺乏或者不 ...
- Oracle SQL性能优化技巧大总结
http://wenku.baidu.com/link?url=liS0_3fAyX2uXF5MAEQxMOj3YIY4UCcQM4gPfPzHfFcHBXuJTE8rANrwu6GXwdzbmvdV ...
- 深入研究Spark SQL的Catalyst优化器(原创翻译)
Spark SQL是Spark最新和技术最为复杂的组件之一.它支持SQL查询和新的DataFrame API.Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言特性( ...
- spark SQL(六)性能调整
spark SQL 性能调整 对于某些工作负载,可以通过在内存中缓存数据或打开一些实验选项来提高性能. 1,在内存中缓存数据 Spark SQL可以通过调用spark.catalog.c ...
- Spark SQL在100TB上的自适应执行实践(转载)
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
随机推荐
- echo不换行的实现
1. echo的参数中, -e表示开启转义, /c表示不换行: echo -e "please input a value:/c" 2. -n不换行: echo -n " ...
- 禁止 pdf 下载、打印的方法
https://blog.csdn.net/For_GG/article/details/78616063 https://blog.csdn.net/xiangcns/article/details ...
- Eclipse Android 模拟器启动过慢
打开AVD Manager窗口,在模拟器配置页面,选择Intel Atom (x86)选项.笔记本的CPU处理器是Intel 酷睿. 可以发现模拟器的启动速度明显变快.
- Java15-java语法基础(十五)——内部类
java16-java语法基础(十五)内部类 一.内部类: 可以在一个类的内部定义另一个类,这种类称为内部类. 二.内部类分为两种类型: 1.静态内部类: 静态内部类是一个具有static修饰词的类, ...
- angular模拟web API
现象:angular Cannot find module 'angular-in-memory-web-api'报错找不动“angular-in-memory-web-api”模块 解决:1.控制台 ...
- paired-end reads的拼接
paired-end reads的拼接 发表于2012 年 8 月 13 日 Velvet中paired-end reads的拼接 文件格式 要将两头测序(paired-end)的reads放到同一个 ...
- 面试简单整理之JVM
194.说一下 jvm 的主要组成部分?及其作用? JVM内存分为“堆”.“栈”和“方法区”三个区域,分别用于存储不同的数据. 堆内存用于存储使用new关键字所创建的对象: 栈内存用于存储程序运行时在 ...
- SFTP搭建@windows using freeSHHd&FileZilla
转自:http://blog.163.com/ls_19851213/blog/static/531321762009815657395/ Windows xp 下 搭建 基于 ssh 的sftp ...
- 电子商务系统+java+web+完整项目+包含源码和数据库Java实用源码
鸿鹄云商大型企业分布式互联网电子商务平台,推出PC+微信+APP+云服务的云商平台系统,其中包括B2B.B2C.C2C.O2O.新零售.直播电商等子平台. 分布式.微服务.云架构电子商务平台 java ...
- python_day12_html
目录: 简单web的服务器代码 html简介 html常用标签 一.简单web的服务器代码 1.简单python服务器代码: import socket def main(): sock = sock ...