Spark动态资源分配-Dynamic Resource Allocation
Spark动态资源分配-Dynamic Resource Allocation
关键字:spark、资源分配、dynamic resource allocation
Spark中,所谓资源单位一般指的是executors,和Yarn中的Containers一样,在Spark On Yarn模式下,通常使用–num-executors来指定Application使用的executors数量,而–executor-memory和–executor-cores分别用来指定每个executor所使用的内存和虚拟CPU核数。相信很多朋友至今在提交Spark应用程序时候都使用该方式来指定资源。
假设有这样的场景,如果使用Hive,多个用户同时使用hive-cli做数据开发和分析,只有当用户提交执行了Hive SQL时候,才会向YARN申请资源,执行任务,如果不提交执行,无非就是停留在Hive-cli命令行,也就是个JVM而已,并不会浪费YARN的资源。现在想用Spark-SQL代替Hive来做数据开发和分析,也是多用户同时使用,如果按照之前的方式,以yarn-client模式运行spark-sql命令行(http://lxw1234.com/archives/2015/08/448.htm),在启动时候指定–num-executors 10,那么每个用户启动时候都使用了10个YARN的资源(Container),这10个资源就会一直被占用着,只有当用户退出spark-sql命令行时才会释放。
spark-sql On Yarn,能不能像Hive一样,执行SQL的时候才去申请资源,不执行的时候就释放掉资源呢,其实从Spark1.2之后,对于On Yarn模式,已经支持动态资源分配(Dynamic Resource Allocation),这样,就可以根据Application的负载(Task情况),动态的增加和减少executors,这种策略非常适合在YARN上使用spark-sql做数据开发和分析,以及将spark-sql作为长服务来使用的场景。
本文以Spark1.5.0和hadoop-2.3.0-cdh5.0.0,介绍在spark-sql On Yarn模式下,如何使用动态资源分配策略。
YARN的配置
首先需要对YARN的NodeManager进行配置,使其支持Spark的Shuffle Service。
- 修改每台NodeManager上的yarn-site.xml:
##修改
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
##增加
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
- 将$SPARK_HOME/lib/spark-1.5.0-yarn-shuffle.jar拷贝到每台NodeManager的${HADOOP_HOME}/share/hadoop/yarn/lib/下。
- 重启所有NodeManager。
Spark的配置
配置$SPARK_HOME/conf/spark-defaults.conf,增加以下参数:
- spark.shuffle.service.enabled true //启用External shuffle Service服务
- spark.shuffle.service.port 7337 //Shuffle Service服务端口,必须和yarn-site中的一致
- spark.dynamicAllocation.enabled true //开启动态资源分配
- spark.dynamicAllocation.minExecutors 1 //每个Application最小分配的executor数
- spark.dynamicAllocation.maxExecutors 30 //每个Application最大并发分配的executor数
- spark.dynamicAllocation.schedulerBacklogTimeout 1s
- spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
- 动态资源分配策略:
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
- 资源回收策略
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
使用spark-sql On Yarn执行SQL,动态分配资源
- ./spark-sql --master yarn-client \
- --executor-memory 1G \
- -e "SELECT COUNT(1) FROM ut.t_ut_site_log where pt >= '2015-12-09' and pt <= '2015-12-10'"

该查询需要123个Task。
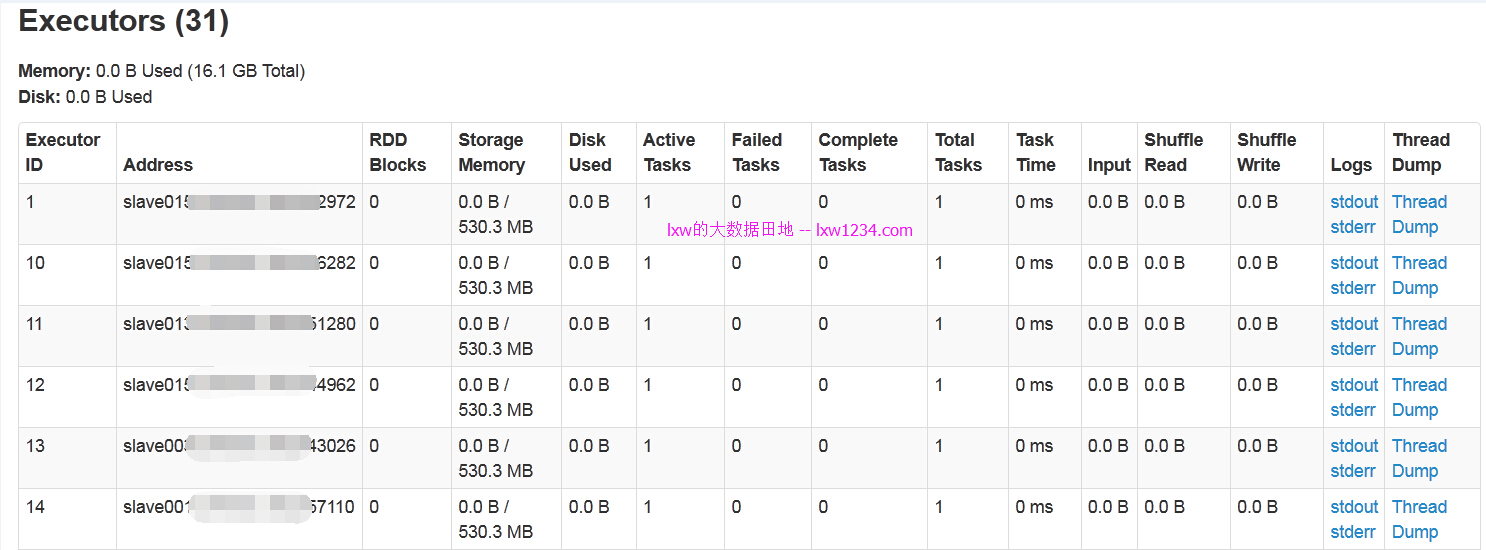
从AppMaster的WEB界面可以看到,总共有31个Executors,其中一个是Driver,既有30个Executors并发执行,而30,正是在spark.dynamicAllocation.maxExecutors参数中配置的最大并发数。如果一个查询只有10个Task,那么只会向Yarn申请10个executors的资源。
需要注意:
如果使用
./spark-sql –master yarn-client –executor-memory 1G
进入spark-sql命令行,在命令行中执行任何SQL查询,都不会执行,原因是spark-sql在提交到Yarn时候,已经被当成一个Application,而这种,除了Driver,是不会被分配到任何executors资源的,所有,你提交的查询因为没有executor而不能被执行。
而这个问题,我使用Spark的ThriftServer(HiveServer2)得以解决。
使用Thrift JDBC方式执行SQL,动态分配资源
首选以yarn-client模式,启动Spark的ThriftServer服务,也就是HiveServer2.
- 配置ThriftServer监听的端口号和地址
- vi $SPARK_HOME/conf/spark-env.sh
- export HIVE_SERVER2_THRIFT_PORT=10000
- export HIVE_SERVER2_THRIFT_BIND_HOST=0.0.0.0
- 以yarn-client模式启动ThriftServer
- cd $SPARK_HOME/sbin/
- ./start-thriftserver.sh \
- --master yarn-client \
- --conf spark.driver.memory=3G \
- --conf spark.shuffle.service.enabled=true \
- --conf spark.dynamicAllocation.enabled=true \
- --conf spark.dynamicAllocation.minExecutors=1 \
- --conf spark.dynamicAllocation.maxExecutors=30 \
- --conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
启动后,ThriftServer会在Yarn上作为一个长服务来运行:

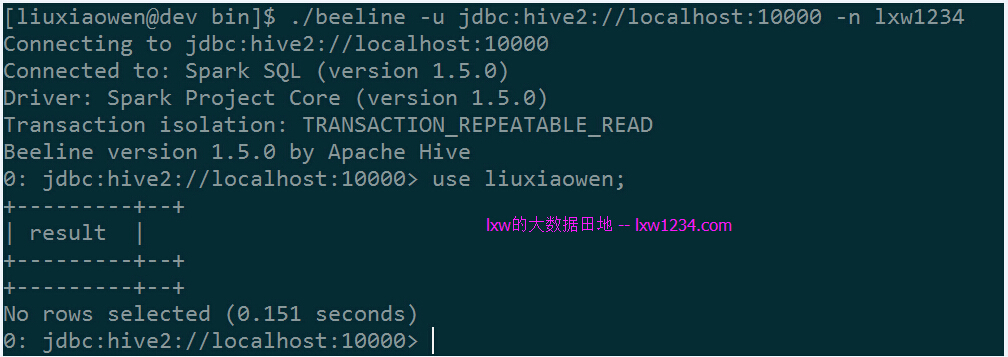
- 使用beeline通过JDBC连接spark-sql
- cd $SPARK_HOME/bin
- ./beeline -u jdbc:hive2://localhost:10000 -n lxw1234
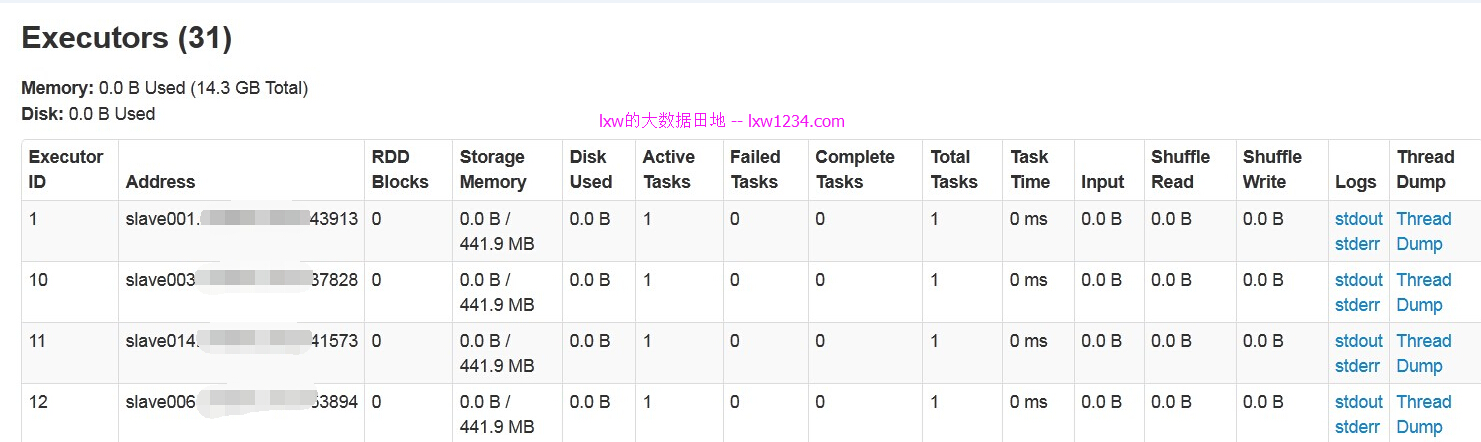
执行查询:
select count(1) from ut.t_ut_site_log where pt = ‘2015-12-10′;
该任务有64个Task:

而监控页面上的并发数仍然是30:
执行完后,executors数只剩下1个,应该是缓存数据,其余的全部被回收:
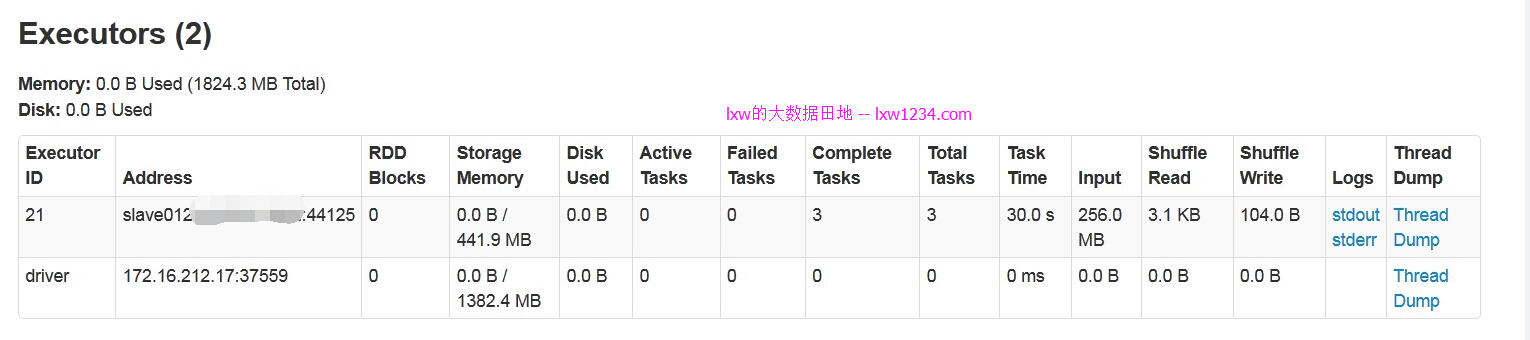
这样,多个用户可以通过beeline,JDBC连接到Thrift Server,执行SQL查询,而资源也是动态分配的。
需要注意的是,在启动ThriftServer时候指定的spark.dynamicAllocation.maxExecutors=30,是整个ThriftServer同时并发的最大资源数,如果多个用户同时连接,则会被多个用户共享竞争,总共30个。
这样,也算是解决了多用户同时使用spark-sql,并且动态分配资源的需求了。
Spark动态资源分配官方文档:http://spark.apache.org/docs/1.5.0/job-scheduling.html#dynamic-resource-allocation
Spark动态资源分配-Dynamic Resource Allocation的更多相关文章
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
- Dynamic Resource – 动态资源
Dynamic Resource – 动态资源 与Static Resource不同的是,Dynamic Resource可以在程序运行时重新评估/计算资源来生成对应的对象/值,它支持向前引用,只 ...
- 动态内存分配(Dynamic memory allocation)
下面的代码片段的输出是什么?为什么? 解析:这是一道动态内存分配(Dynamic memory allocation)题. 尽管不像非嵌入式计算那么常见,嵌入式系统还是有从堆(heap)中动态分 ...
- PatentTips - Systems, methods, and devices for dynamic resource monitoring and allocation in a cluster system
BACKGROUND 1. Field The embodiments of the disclosure generally relate to computer clusters, and m ...
- WPF 用代码调用dynamic resource动态更改背景 - CSDN博客
原文:WPF 用代码调用dynamic resource动态更改背景 - CSDN博客 一般dynamic resoource通常在XAML里调用,如下范例: <Button Click=&qu ...
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
随机推荐
- 关于SQL中的 where 1 = 1 的用法
在项目中的常见的一个操作:在有关SQL的代码中加入where 1 = 1,关于它的用法,可以总结如下: 首先,where 1 = 1的用法往往是为了方便后续的给SQL增加where限制条件.如果实现加 ...
- MySql操作命令创建学生管理系统
1.创建学生管理系统数据库xscj create detabase 数据库名: 2.打开数据库 use 数据库名: //创建数据库之后,该数据库不会自动成为当前数据库需要用use来指定 3.创建表名 ...
- MyBatis的一级缓存、二级缓存演示以及讲解,序列化异常的处理
MyBatis的缓存机制 缓存就是内存中的一个空间,通常用来提高查询效率 MyBatis支持两种缓存技术:一级缓存和二级缓存,其中一级缓存默认开启,二级缓存默认关闭 一级缓存 (1)一级缓存默认开启 ...
- zabbix--自动注册
Active agent自动注册 agent 自动注册就是实现一台新的服务器配置好 agent 端,自动在服务器端注册,无需在服务器上进行手动配置便可以直接启动对新的host的监控. 参考官档:htt ...
- Codeforces Round #601 (Div. 2) E2. Send Boxes to Alice (Hard Version)
Codeforces Round #601 (Div. 2) E2. Send Boxes to Alice (Hard Version) N个盒子,每个盒子有a[i]块巧克力,每次操作可以将盒子中的 ...
- P1081 开车旅行[倍增](毒瘤题)
其实就是个大模拟. 首先,根据题意,小A和小B从任意一个城市开始走,无论\(X\)如何,其路径是一定唯一的. 显然对于两问都可以想出一个\(O(n^2)\)的暴力,即直接一步一步地向右走. 首先,我们 ...
- springBoot 利用Idea打包部署
springBoot 打包部署 1 项目如图: 2 依赖打包插件 3 打包操作 4 运行项目:
- 基于Docker方式实现Elasticsearch集群
采用docker容器,搭建两个es集群,可根据步骤自行扩展n+集群 1.创建es挂载目录 cd /usr/localmkdir -p es/config 2.创建es存放数据目录 cd esmkdir ...
- 开源项目(5-2) yolo打包成库
Windows系统下YOLO动态链接库的封装和调用 Windows10+VS2015+OpenCV3.4.1+CUDA8.0+cuDNN8.0 参考教程 https://blog.csdn.net/s ...
- 常见WinDbg问题及解决方案
当你调试一个程序时,你最不想处理的是调试器不能正常工作.当你试图集中精力跟踪一个bug时,总是会因为次要的问题而被忽略,尤其是当调试器的问题导致你失去一个重新编程或者浪费了大量的时间等待调试器完成它, ...