开源OCR识别库-Tesseract介绍
最近在github上面看到一个开源的ocr文字识别库,感觉效果还可以,所以在这里介绍一下,这个项目的原地址在:https://github.com/tesseract-ocr/tesseract。
tesseract库支持你训练自己的文字识别模型,当然其本身已经提供了几十种不同语言模型,你也可以直接下载使用,最新的4.0版本使用了LSTM神经网络框架,
在识别中文方面效果还是不错的。tesseract有两种使用方式,一种是安装完成以后,通过命令行向tesseract应用传入要解析的图片,翻译完成后输出一个txt文件;
第二种方式是自己写程序调用api函数。
下面介绍一下tesseract库的使用方法。
如果你用的是ubuntu18.0.4那么安装很简单:
在终端输入指令安装即可:
sudo apt-get install tesseract-ocr
sudo apt-get install libtesseract-dev
如果你跟我一样是使用ubuntu16.0.4,那么需要按照我下面的方法来安装,因为16.0.4采用上面的办法安装的是3.0的版本,3.0解析的效果不是很好。
如果你是在windows平台或其他平台可以参考:https://github.com/tesseract-ocr/tesseract/wiki/Compiling。
(1)安装依赖库
sudo apt-get install g++
sudo apt-get install autoconf automake libtool
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
sudo apt-get install libicu-dev
sudo apt-get install libpango1.0-dev
sudo apt-get install libcairo2-dev
sudo apt-get install git
(2)安装leptonica 1.74
cd ~/Download
git clone https://github.com/DanBloomberg/leptonica
cd leptonica
./configure
make
make install
(3)安装tesseract
cd ~/Download
git clone https://github.com/tesseract-ocr/tesseract
cd tesseract
./autogen.sh
./configre --prefix=/usr/local
make
make install
(4)下载语言包
tesseract提供了三种模型,testdata:普通模型,testdata_fast:快速识别模型,testdata_best:最佳识别模型,
在:https://github.com/tesseract-ocr/tessdata_best目录下下载:eng.traineddata、chi_sim.traineddata、chi_sim_vert.traineddata三个文件,
然后将这三个文件复制到/usr/local/share/testdata目录下,如果你想识别其他语言也是下载语言识别模型然后放到testdata目录下即可。
(5)设置语言模型路径
vim ~/.bashrc
在末尾添加:
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
export TESSDATA_PREFIX=/usr/local/share/tessdata/
然后关闭终端,重新打开终端生效。
(6)测试识别库
在终端输入
tesseract --version看版本是否如下:

输入:
tesseract --list-langs查看语言模型是否正确:
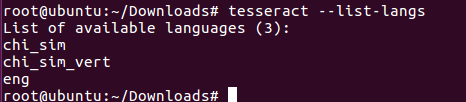
可以看到自动识别了英语和简体中文模型了。
然后随便找张有中文字符的图片进行识别测试:
tesseract 1.jpg out -l chi_sim
参数说明:1.jpg:要解析的文件
out:解析输出的文件名
-l chi_sim:采用的语言模型,这里选择了简体中文。
我识别的原文:

识别到的文字如下:
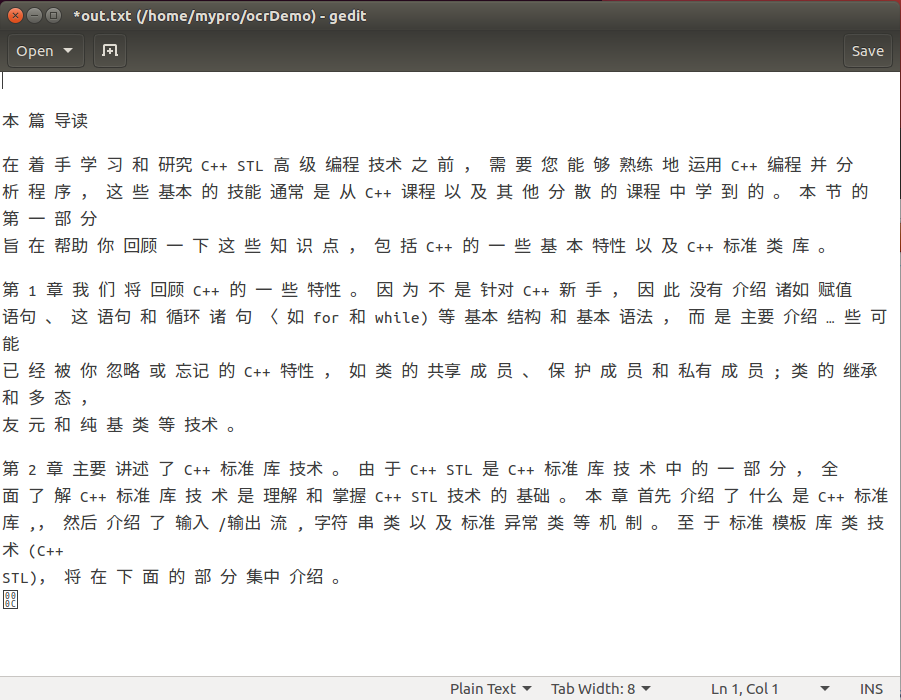
(7)用C++调用api进行识别测试。
代码:
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <iostream>
#include <memory>
using namespace std;
int main()
{
tesseract::TessBaseAPI api;
cout<<"version:"<<api.Version()<<endl;
if(api.Init(NULL,"chi_sim")==0)
cout<<"Init Ok"<<endl;
else
{
cout<<"Init error"<<endl;
return -1;
}
api.SetPageSegMode(tesseract::PageSegMode::PSM_AUTO);
api.SetVariable("save_best_choices","T");
auto pixs = pixRead("./1.jpg");
if(!pixs)
{
cout<<"load image error"<<endl;
return -2;
}
api.SetImage(pixs);
api.Recognize(0);
cout<<std::unique_ptr<char[]>(api.GetUTF8Text()).get()<<endl;
api.Clear();
pixDestroy(&pixs);
return 0; }
makefile:
CXX := g++
CXX_FLAGS := -Wall -Wextra -std=c++11 -ggdb BIN := .
SRC := .
INCLUDE :=
LIB := LIBRARIES :=-llept -ltesseract
EXECUTABLE := ocrDemo all: $(BIN)/$(EXECUTABLE) run: clean all
clear
./$(BIN)/$(EXECUTABLE) $(BIN)/$(EXECUTABLE): $(SRC)/*.cpp
$(CXX) $(CXX_FLAGS) -I$(INCLUDE) -L$(LIB) $^ -o $@ $(LIBRARIES) clean:
-rm $(BIN)/*
测试效果:

开源OCR识别库-Tesseract介绍的更多相关文章
- Python的开源人脸识别库:离线识别率高达99.38%
Python的开源人脸识别库:离线识别率高达99.38% github源码:https://github.com/ageitgey/face_recognition#face-recognitio ...
- Python的开源人脸识别库:离线识别率高达99.38%(附源码)
Python的开源人脸识别库:离线识别率高达99.38%(附源码) 转https://cloud.tencent.com/developer/article/1359073 11.11 智慧上云 ...
- face_recognition开源人脸识别库:离线识别率高达99.38%
基于Python的开源人脸识别库:离线识别率高达99.38%——新开源的用了一下感受一下 原创 2017年07月28日 21:25:28 标签: 人脸识别 / 人脸自动定位 / 人脸识别开源库 / f ...
- 开源文字识别软件tesseract
1.下载4.0软件,下一步下一步到成功: 2.安装之后配置环境变量,Path中添加安装路径(默认:C:\Program Files (x86)\Tesseract-OCR) 3.新增语言库的环境变量, ...
- python ocr中文识别库 tesseract安装及问题处理
这个破东西,折腾了快1个小时,网上的教材太乱了. 我解决的主要是windows的问题 先下载exe.(一看到这个,我就有种预感,不妙) https://digi.bib.uni-mannheim.de ...
- 【转】OCR识别引擎tesseract使用方法——安装leptonica和libtiff
原文来自:http://cache.baiducontent.com/c?m=9f65cb4a8c8507ed4fece7631046893b4c4380146d96864968d4e414c4224 ...
- 开源 人脸识别 openface 实用介绍 实例演示 训练自己的模型
1.OpenFace 是 卡耐基梅陇(CMU)大学的一个图像+机器学习项目,整体程序包含:人脸发现,特征提取,特征神经网络训练,人脸识别这四部分. github https://github.co ...
- 基于Python的开源人脸识别库:离线识别率高达99.38%
项目地址:https://github.com/ageitgey/face_recognition#face-recognition 本文的模型使用了C++工具箱dlib基于深度学习的最新人脸识别方法 ...
- C# WPF开源控件库MaterialDesign介绍
介绍 1.由于前端时间萌发开发一个基础架构得WPF框架得想法, 然后考虑到一些界面层元素统一, 然后就无意间在GitHub上发现一个开源WPF UI, 于是下载下来了感觉不错. 官网地址:http:/ ...
随机推荐
- 第三方百度网盘客户端 PanDownload、速盘、panlight
PanDownload PanDownload是一款能够快速下载百度网盘内资源的强大工具.PanDownload能够无限速高速下载,满速下载百度云盘里的各种资源.而且PanDownload完全免费,免 ...
- swift修饰符
Declaration Modifiers Declaration modifiers are keywords or context-sensitive keywords that modify t ...
- The Secret Life of Types in Swift
At first glance, Swift looked different as a language compared to Objective-C because of the modern ...
- Linux OOM一二三
Linux开发一般会遇到“/proc/sys/vm/overcommit_memory”,即文件/etc/sysctl.conf中的vm.overcommit_memory,Overcommit的意思 ...
- Android Studio软件技术基础 —Android项目描述---1-类的概念-android studio 组件属性-+标志-Android Studio 连接真机不识别其他途径
学习android对我来说,就是兴趣,所以我以自己的兴趣写出的文章,希望各位多多支持!多多点赞,评论讨论加关注. 最近有点忙碌,对于我来说,学习Android开发,是对于我的考验,最近一位大佬发给我一 ...
- Ubuntu使用小结(主要为后面部署K8s集群做基础铺垫)
包管理 dpkg -L libxml2 #查看libxml2安装了些什么文件 dpkg -s /usr/bin/ls #查看ls是那个包提供的 dpkg -c abc.deb #查看abc. ...
- Windows(win2016、win2019、win10)在IIS下添加.NET Framework 3.5 NetFx3 失败 (状态为:0x800f0950)的解决办法
今天一个客户自己的电脑安装了一个windows server 2016 想装一个IIS,程序一个C+写的ERP,NET是必然,NET4.7可以安装了,但就是3.5,如何也装不上,错误(状态为:0x80 ...
- linux 去掉 ^M 的方法
在linux上经常遇到这种问题,从网上下载文件到 linux 上后,就多了很多 ^M这种东西,如何集体删除这种东西呢! 用 vim 打开文件 进行如下设置 将文件格式转化为unix :set ff= ...
- PowerDesigner应用01 逆向工程之配置数据源并导出PDM文件
物理数据模型(Physical Data Model)PDM,提供了系统初始设计所需要的基础元素,以及相关元素之间的关系:数据库的物理设计阶段必须在此基础上进行详细的后台设计,包括数据库的存储过程.操 ...
- CV基础知识点深入理解
BN实现: Batch Normalization学习笔记及其实现: BatchNormalization 层的实现 使用Python实现Batch normalization和卷积层 Batch N ...