mybatis oracle两种方式批量插入数据
mybatis oracle两种方式批量插入数据
注意insert,一定要添加: useGeneratedKeys="false" ,否者会报错。
<insert id="addBatch" parameterType="java.util.List">
BEGIN
<foreach collection="list" item="item" index="index" separator="">
insert into blacklist
(id, userid, deviceid, createdate, updatedate, "LEVEL")
VALUES
(
USER_INFO_SEQ.NEXTVAL,#{item.userId,jdbcType=INTEGER},#{item.deviceId,jdbcType=VARCHAR},
#{item.createDate,jdbcType=DATE},sysdate, #{item.level,jdbcType=INTEGER} );
</foreach>
COMMIT;
END;
</insert>
<insert id="addBatch" parameterType="java.util.List">
INSERT INTO INFO (
PARTNERSERIALNUM,
MEMBERTYPE,
PARTNERMEMBERID,
REGMOBILE,
CONTACTSMOBILE,
"NAME",
)
<foreach collection="list" item="item" index="index" separator="union all" >
select #{item.partnerSerialNum,jdbcType=VARCHAR}, #{item.memberType,jdbcType=VARCHAR}, #{item.partnerMemberId,jdbcType=VARCHAR}, #{item.regMobile,jdbcType=VARCHAR}, #{item.contactsMobile,jdbcType=VARCHAR}, #{item.name,jdbcType=VARCHAR}
} from dual
</foreach>
</insert>
上面转载id为phantomes的文章
下面放一个看了这个改好自己的代码的例子:用户授权。
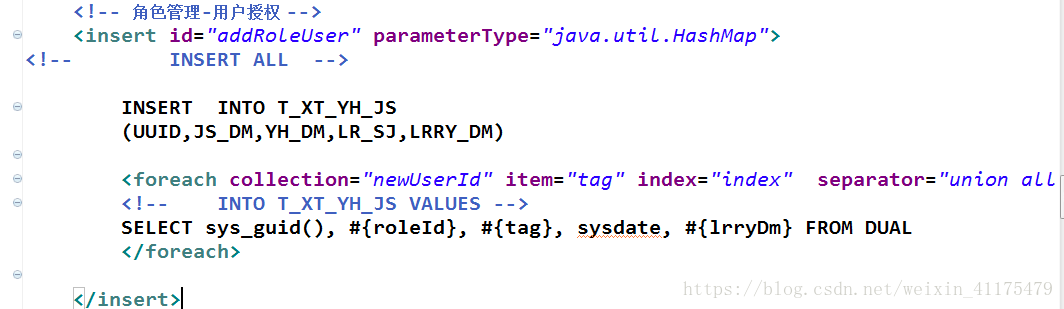
mybatis oracle两种方式批量插入数据的更多相关文章
- mybatis中批量插入的两种方式(高效插入)
MyBatis简介 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以使用 ...
- SpringBoot从入门到精通二(SpringBoot整合myBatis的两种方式)
前言 通过上一章的学习,我们已经对SpringBoot有简单的入门,接下来我们深入学习一下SpringBoot,我们知道任何一个网站的数据大多数都是动态的,也就是说数据是从数据库提取出来的,而非静态数 ...
- elasticsearch REST API方式批量插入数据
elasticsearch REST API方式批量插入数据 1:ES的服务地址 http://127.0.0.1:9600/_bulk 2:请求的数据体,注意数据的最后一行记得加换行 { &quo ...
- springboot整合mybatis的两种方式
https://blog.csdn.net/qq_32719003/article/details/72123917 springboot通过java bean集成通用mapper的两种方式 前言:公 ...
- oracle 使用occi方式 批量插入多条数据
if (vecInfo.empty()) { ; //数据为空,不上传,不上传标志设置为1,只有0表示上传成功 } std::string strUserName = userName; std::s ...
- mysql应用之通过存储过程方式批量插入数据
我们平时的测试过程中有一个环节就是准备测试数据,包括准备基础数据,准备业务数据,使用的场景包括压力测试,后台批量数据传输,前端大数据查询导出,或者分页打印等功能,准备测试数据我们通俗点讲就是造数据,根 ...
- mybatis注解方式批量插入数据
@Insert("<script>" + "INSERT INTO cms_portal_menu(name,service_type,index_code) ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- Java解析Json数据的两种方式
JSON数据解析的有点在于他的体积小,在网络上传输的时候可以更省流量,所以使用越来越广泛,下面介绍使用JsonObject和JsonArray的两种方式解析Json数据. 使用以上两种方式解析json ...
随机推荐
- Charles手机代理设置
Charles工具 手机 方法/步骤 1.打开Charles 点击Proxy,选择proxy settings,输入端口8888 打开电脑,在cmd中输入ipconfig,查看本地 ...
- makefile从0到1
一.什么是makefile 百度百科:Linux 环境下的程序员如果不会使用GNU make来构建和管理自己的工程,应该不能算是一个合格的专业程序员,至少不能称得上是Unix程序员.在 Linux(u ...
- SpringCloud之Ribbon负载均衡及Feign消费者调用服务
目的: 微服务调用Ribbon Ribbon负载均衡 Feign简介及应用 微服务调用Ribbon Ribbon简介 1. 负载均衡框架,支持可插拔式的负载均衡规则 2. 支持多种协议,如HTTP.U ...
- Kafka 初识
1.Kafka 是什么? 用一句话概括一下:Apache Kafka 是一款开源的消息引擎系统. 倘若“消息引擎系统“这个词对你来说有点陌生的话,那么“消息队列“.“消息中间件”的提法想必你一定是有所 ...
- JavaScript中数组的key-value在对象中倒装的妙用
对于数组的去重.寻找指定元素的索引,通常我们都是通过遍历来解决,但是在某些应用场景下,将数组的value-key进行倒装,也即将value当做对象的key,key当做对象value,可以极大降低算法的 ...
- java程序员必须熟悉的一些操作
1.mysql数据库服务启动命令 /etc/init.d/mysqld start --启动命令 mysql数据库安装方法参考 http://www.blogja ...
- 使用交叉验证法(Cross Validation)进行模型评估
scikit-learn中默认使用的交叉验证法是K折叠交叉验证法(K-fold cross validation):它将数据集拆分成k个部分,再用k个数据集对模型进行训练和评分. 1.K折叠交叉验证法 ...
- isolate两三事
1.1. 第一步:创建并握手 如前所述,Isolate 不共享任何内存并通过消息进行交互,因此,我们需要找到一种方法在「调用者」与新的 isolate 之间建立通信. 每个 Isolate 都暴露了一 ...
- OO——JML作业总结
目录 第三单元博客作业 JML语言理论基础 1.注释结构 2.JML表达式 3.方法规格 4.类型规格 应用工具链 JMLUnitNG使用实例 作业架构设计 第一次作业 第二次作业 第三次作业 BUG ...
- 某类继承thread,同时实现runnable
package com.giserve.test; public class ThreadTest { public static void main(String[] args) { new Thr ...