python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了?
浏览器请求数据方式:浏览器向服务器的api(例如这样的字符串:http://api.qingyunke.com/api.php?key=free&appid=0&msg=关键词)发送请求,服务器返回json,然后解析该json,就得到请求数据了
同理:用Python向api发送请求,获得json,解析json,得到数据
即关键在于得到api
api获取:
1.用浏览器打开目标网页eg:https://www.zhihu.com/topic/19561718/top-answers
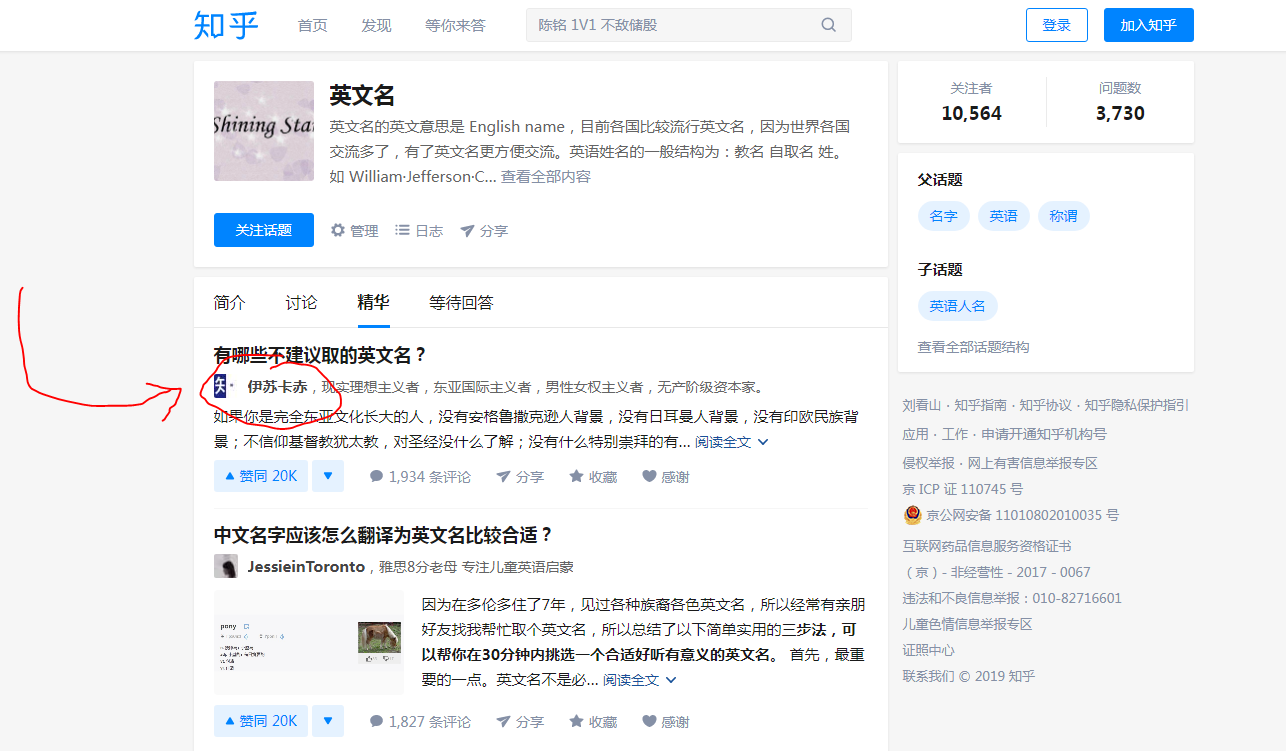
将鼠标放在上图图示位置,将显示该用户的一些信息,这些信息就是动态加载出来的。当鼠标放在该位置时,浏览器向服务器api发出请求,得到json,再解析便得到下图所示数据

在该网页反键选择检查源代码,按图示点开选项:
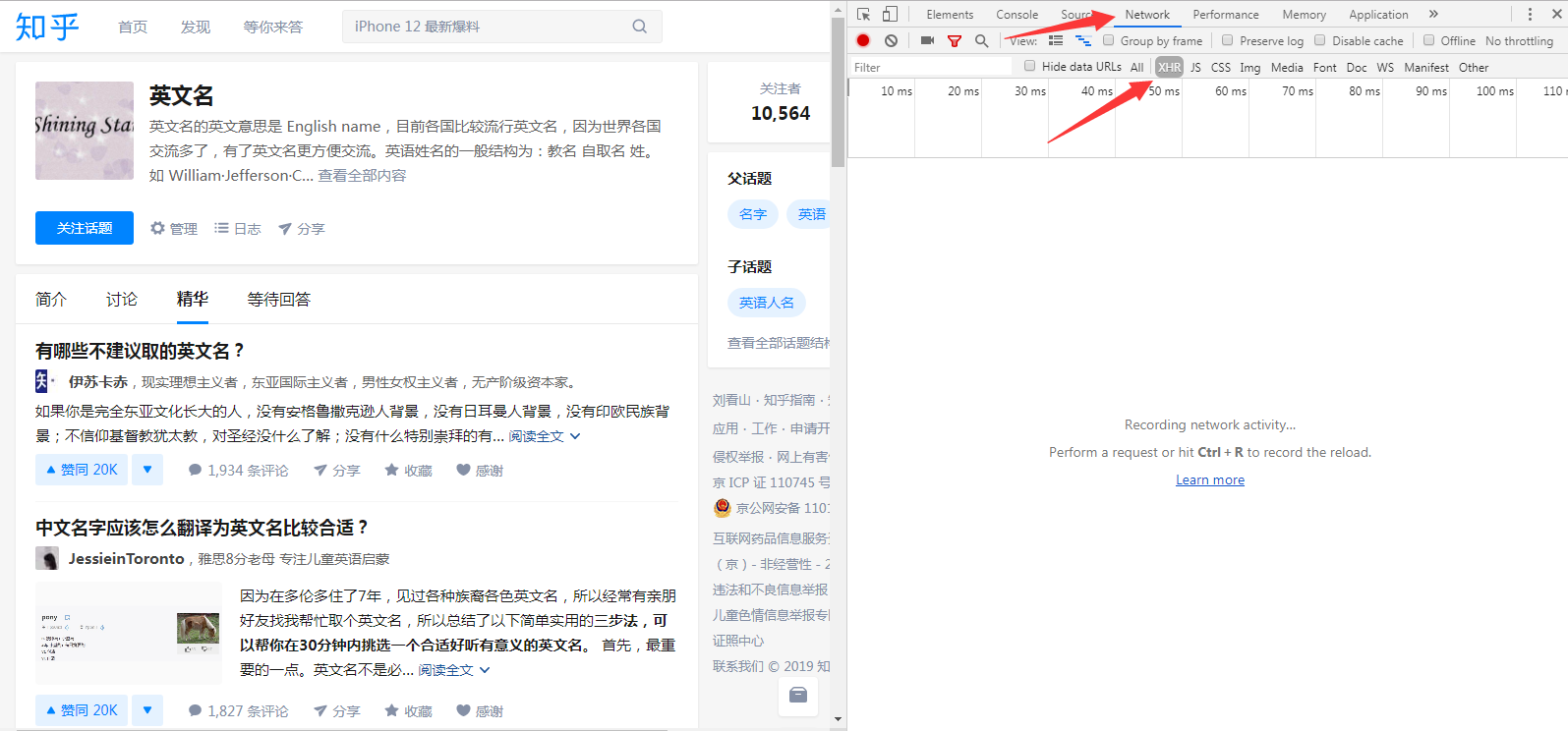
然后将鼠标移动到网页界面用户上(箭头位置),会发现右边多出两个请求信息,如图:
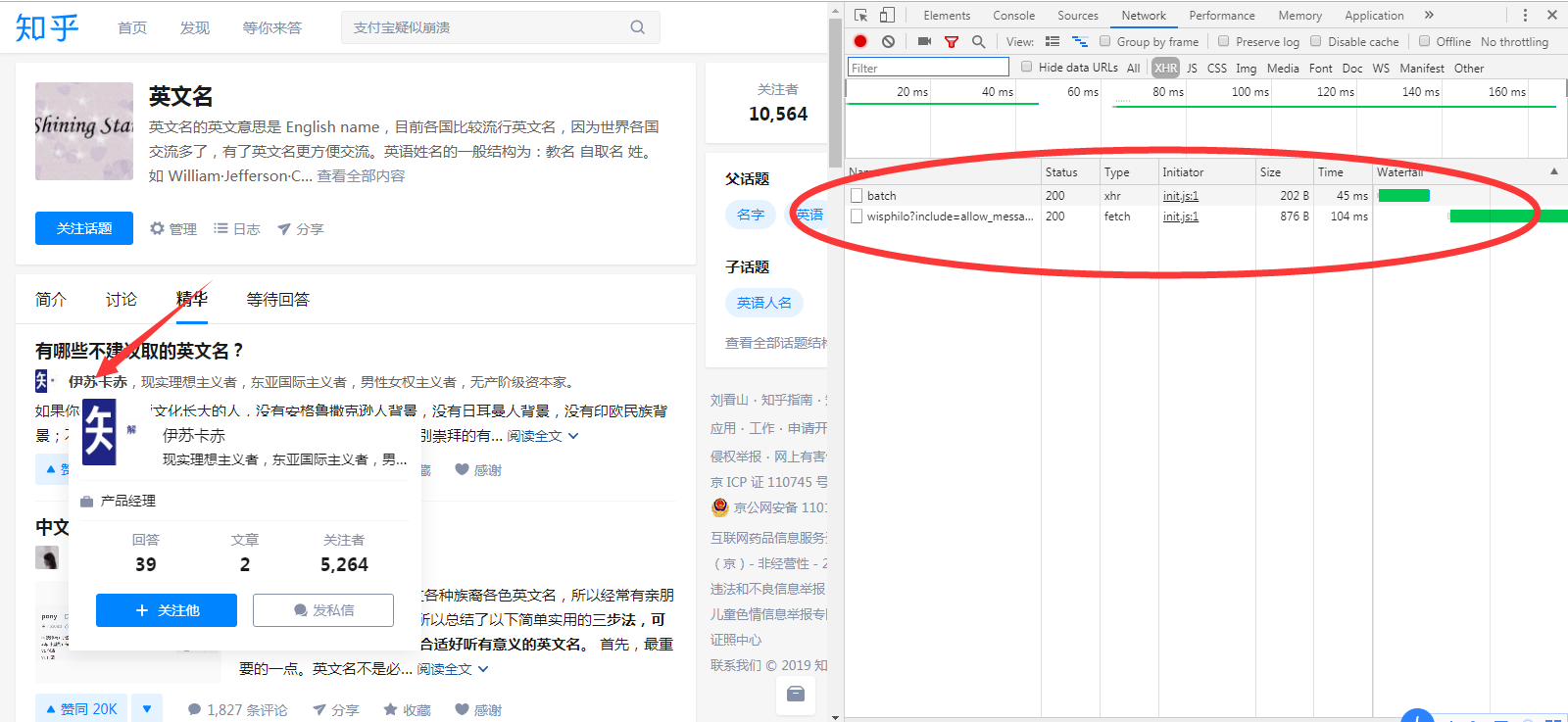
点击下面一个,红色方框内的链接,就是要找的api接口
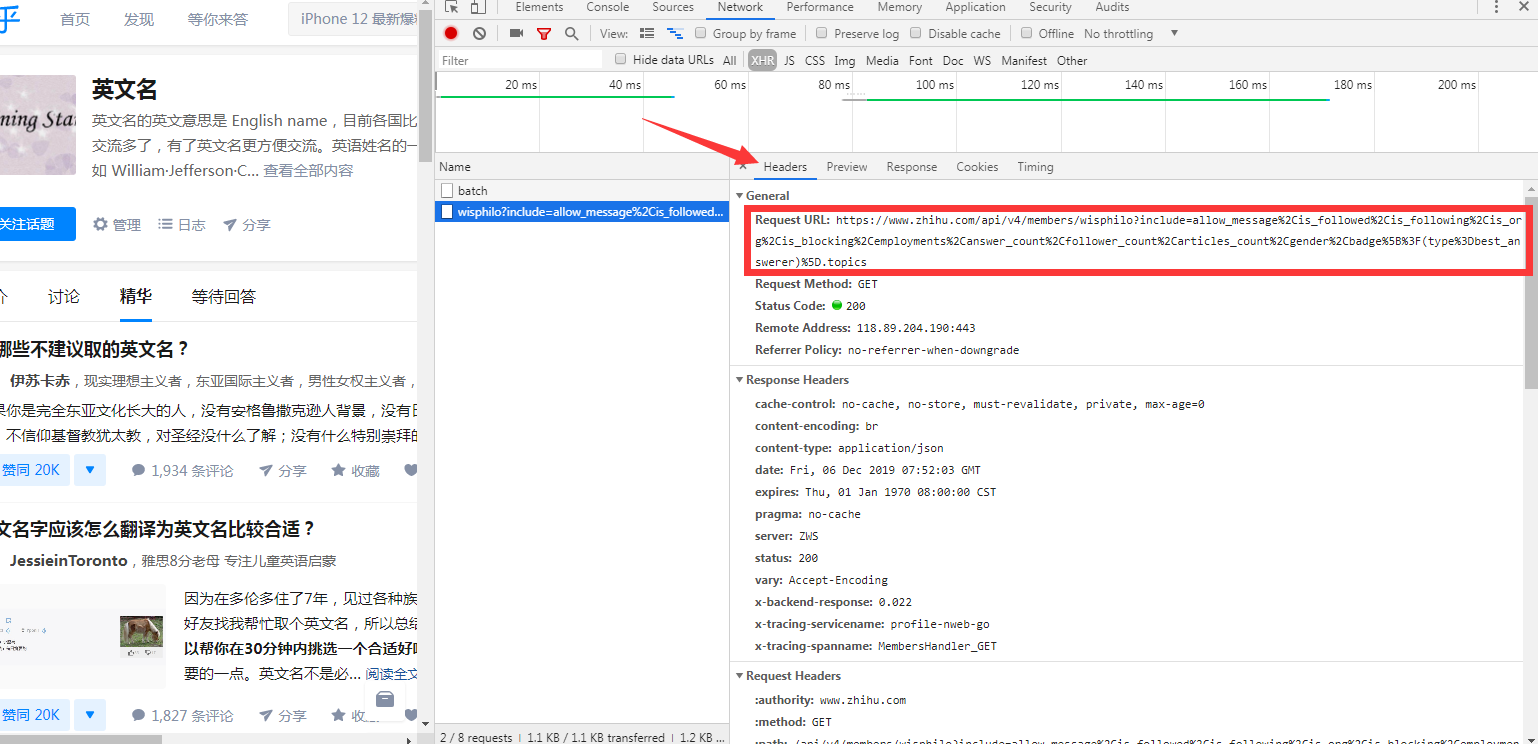
直接用浏览器打开该api即可看到json,如下图
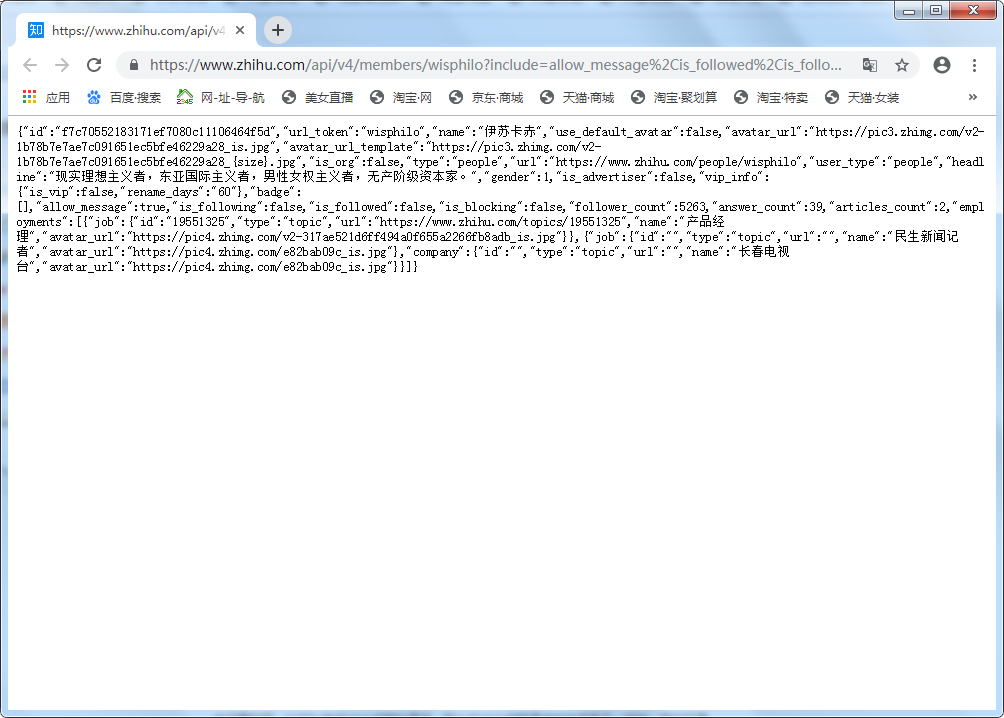
下面用python代码请求该api并解析
import requests
import json
#api
url='https://www.zhihu.com/api/v4/members/wisphilo?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
#header的目的是模拟请求,因为该api设置了反爬取
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
doc=requests.get(url,headers=header)#发起请求
doc.encoding='utf-8'#设置编码为utf-8
data=json.loads(doc.text)#将json字符串转为json
#根据位置查找数据
print('用户名:',data.get('name'))
print('个人描述:',data.get('headline'))
print('职务:'+data.get('employments')[0].get('job').get('name'))
print('回答:',data.get('answer_count'))
print('文章:',data.get('articles_count'))
print('关注者:',data.get('follower_count'))
另外查找数据最好用在线json格式化再查找,不然很难看出自己要的数据在哪eg:

一般网页的api都有规律可寻,用for循环控制变换字符即可实现自动爬取
上述代码运行结果:

和该界面对照
以上
python爬取动态网页数据,详解的更多相关文章
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- 利用selenium并使用gevent爬取动态网页数据
首先要下载相应的库 gevent协程库:pip install gevent selenium模拟浏览器访问库:pip install selenium selenium库相应驱动配置 https: ...
- python爬取动态网页2,从JavaScript文件读取内容
import requests import json head = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力.在R语言中,爬取这类网页可以使用RSele ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
随机推荐
- 5. JDBC/ODBC服务器
Spark SQL也提供JDBC连接支持,这对于让商业智能(BI)工具连接到Spark集群上以及在多用户间共享一个集群的场景都非常有用.JDBC服务器作为一个独立的Spark驱动器程序运行,可以在多用 ...
- html2canvas以及domtoimage的使用踩坑总结
前言 首先做个自我介绍,我是成都某企业的一名刚刚入行约一年的前端,在之前的开发过程中,遇到了问题,也解决了问题,但是在下一次解决相同问题的时候,只对这个问题有一丝丝的印象,还需要从新去查找,于是,我注 ...
- VirtualBox导入OVA文件文档教程
1 2 修改框住的路径,最好不要在C盘 3 取消检查更新 4 5 6 7 8 9 10 11 等待加载完成:加载完成后 OVA文件导入成功 作者:含笑半步颠√ 博客链接:https://www.cnb ...
- 单实例dg软件从10.2.0.4版本安装至10.2.0.5.12
DG环境搭建需求,因此安装与主库相同的软件版本 1.主库软件版本10.2.0.5.12 2dg环境提供的是全新的10.2.0.4.0 3.安装步骤,安装10.2.0.5 静默安装 psu安装10.2. ...
- java之struts2之ServletAPI
在之前的学习中struts2已经可以处理大部分问题了.但是如果要将用户登录数据存入session中,可以有两种方式开存入ServletAPI. 一种解耦合方式,一种耦合方式. 1. 解耦合方式 解耦合 ...
- 每周分享五个 PyCharm 使用技巧(六)
大家好,今天我又来给大家更新 PyCharm 的使用技巧. 从今年3月24号开始一直到今天,将近四个月的时间.包括本篇,一共更新了6篇文章,每篇 5 个小技巧,总计 30 个. 这30个使用技巧,全部 ...
- 用js写的简单的下拉菜单
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- python+selenium爬取关键字搜索google图片
# -*- coding: utf-8 -*- import json import os import time from multiprocessing import Pool import mu ...
- MySQL Lock--gap before rec insert intention waiting
在事务插入数据过程中,为防止其他事务向索引上该位置插入数据,会在插入之前先申请插入意向范围锁,而如果申请插入意向范围锁被阻塞,则事务处于gap before rec insert intention ...
- WinServer-开关机日志
开关机日志正常1074, 6006, 13, 12, 6005,41,60081074 记录某用户在某计划下重启6006 日志服务关闭13 OS关闭时间按12 OS启动时间6005 日志服务开启 异常 ...