Python 多线程爬取站酷(zcool.com.cn)图片
极速爬取下载站酷(https://www.zcool.com.cn/)设计师/用户上传的全部照片/插画等图片。
项目地址:https://github.com/lonsty/scraper
特点:
- 极速下载:多线程异步下载,可以根据需要设置线程数
- 异常重试:只要重试次数足够多,就没有下载不下来的图片 (o)/
- 增量下载:设计师/用户有新的上传,再跑一遍程序就行了 O(∩_∩)O嗯!
- 支持代理:可以配置使用代理
环境:
python3.6及以上
1. 快速使用
1) 克隆项目到本地
git clone https://github.com/lonsty/scraper
2) 安装依赖包
cd scraper
pip install -r requirements.txt
3) 快速使用
通过用户名username下载所有图片到路径path下:
python crawler.py -u <username> -d <path>
运行截图
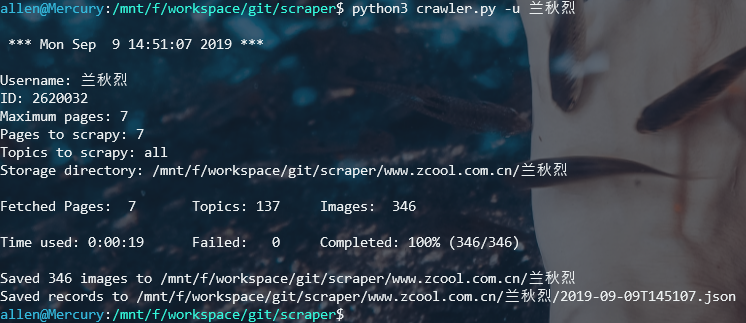
爬取结果
2. 使用帮助
- 查看所有命令
python crawler.py --help
Usage: crawler.py [OPTIONS]
Use multi-threaded to download images from https://www.zcool.com.cn in
bulk by username or ID.
Options:
-i, --id TEXT User id.
-u, --username TEXT User name.
-d, --directory TEXT Directory to save images.
-p, --max-pages INTEGER Maximum pages to parse.
-t, --max-topics INTEGER Maximum topics per page to parse.
-w, --max-workers INTEGER Maximum thread workers. [default: 20]
-R, --retries INTEGER Repeat download for failed images. [default: 3]
-r, --redownload TEXT Redownload images from failed records.
-o, --override Override existing files. [default: False]
--proxies TEXT Use proxies to access websites.
Example:
'{"http": "user:passwd@www.example.com:port",
"https": "user:passwd@www.example.com:port"}'
--help Show this message and exit.
3. 更新历史
Version 0.1.0 (2019.09.09)
主要功能:
- 极速下载:多线程异步下载,可以根据需要设置线程数
- 异常重试:只要重试次数足够多,就没有下载不下来的图片 (o)/
- 增量下载:设计师/用户有新的上传,再跑一遍程序就行了 O(∩_∩)O嗯!
- 支持代理:可以配置使用代理
Python 多线程爬取站酷(zcool.com.cn)图片的更多相关文章
- python多线程爬取斗图啦数据
python多线程爬取斗图啦网的表情数据 使用到的技术点 requests请求库 re 正则表达式 pyquery解析库,python实现的jquery threading 线程 queue 队列 ' ...
- python多线程爬取世纪佳缘女生资料并简单数据分析
一. 目标 作为一只万年单身狗,一直很好奇女生找对象的时候都在想啥呢,这事也不好意思直接问身边的女生,不然别人还以为你要跟她表白啥的,况且工科出身的自己本来接触的女生就少,即使是挨个问遍,样本量也 ...
- Python多线程爬取某网站表情包
# 爬取网络图片import requestsfrom lxml import etreefrom urllib import requestfrom queue import Queue # 导入队 ...
- 用Python爬虫爬取炉石原画卡牌图片
前段时间看了点Python的语法以及制作爬虫常用的类库,于是动手制作了一个爬虫尝试爬取一些炉石原画图片.本文仅记录对特定目标网站的分析过程和爬虫代码的编写过程.代码功能很局限,无通用性,仅作为一个一般 ...
- 【Python爬虫案例学习2】python多线程爬取youtube视频
转载:https://www.cnblogs.com/binglansky/p/8534544.html 开发环境: python2.7 + win10 开始先说一下,访问youtube需要那啥的,请 ...
- python多线程爬取-今日头条的街拍数据(附源码加思路注释)
这里用的是json+re+requests+beautifulsoup+多线程 1 import json import re from multiprocessing.pool import Poo ...
- selenium爬取优酷页面并下载图片
from selenium import webdriver import requests driver = webdriver.Chrome() #打开优酷 driver.get("ht ...
- Python爬虫入门教程: All IT eBooks多线程爬取
All IT eBooks多线程爬取-写在前面 对一个爬虫爱好者来说,或多或少都有这么一点点的收集癖 ~ 发现好的图片,发现好的书籍,发现各种能存放在电脑上的东西,都喜欢把它批量的爬取下来. 然后放着 ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
随机推荐
- 【GMT43智能液晶模块】例程二十:LAN_DNS实验——域名解析
源代码下载链接: 链接:https://pan.baidu.com/s/16EW6AYpHpXljmBdNvMJM7g提取码:6lyk 复制这段内容后打开百度网盘手机App,操作更方便哦 GMT43购 ...
- matlab学习笔记11_3高维数组操作 filp, shiftdim, size, permute, ipermute
一起来学matlab-matlab学习笔记11 11_3 高维数组处理和运算 filp, shiftdim, size, permute, ipermute 觉得有用的话,欢迎一起讨论相互学习~Fol ...
- Flask 学习(三)路由介绍
Flask路由规则都是基于Werkzeug的路由模块的,它还提供了很多强大的功能. 两种添加路由的方式 方式一: @app.route('/xxxx') # @decorator def index( ...
- 经常开车的朋友必备 它是你的GPS
经常开车的朋友肯定知道,每天都要查下当天的限行尾号,还有哪条路拥堵.还有,最不想发生的事儿就是车子快没油的时候,附近查不到加油站. 现在用这款小程序,可以轻松解决上述这些头痛的事情.扫描下面二维码,进 ...
- java CountDownLatch报错java.lang.IllegalMonitorStateException: null
笔者使用websocket进行通信,服务器异步返回.websocket服务器又异步调用其他websocket,也是异步访问. 由于无法预测服务器调用第三方websocket什么时候调用结束,使用了Co ...
- Leetcode problems classified by company 题目按公司分类(Last updated: October 2, 2017)
All LeetCode Questions List 题目汇总 Sorted by frequency of problems that appear in real interviews. Las ...
- QT+FFMPEG+SDL2.0实现视频播放
开发环境:MinGW+QT5.9+FFMPEG20190212+SDL2.0.9 一.开发环境搭建 (1)下载工具 在https://ffmpeg.zeranoe.com/builds/下载对应版本. ...
- (CSDN 迁移) jFinal找不到或无法加载主类
错误: 找不到或无法加载主类 com.demo.common.DemoConfig 项目上右键 -> Build Path -> Order and Export 修改顺序: 从上到下依次 ...
- Redis实现实时热点查询
Redis内存淘汰 定义: 指的是用户存储的一些键被可以被Redis主动地从实例中删除,从而产生读miss的情况 机制存在原因: Redis最常见的两种应用场景为缓存和持久存储 首先要明确的一个问题是 ...
- 【记录】【solr】whose UTF8 encoding is longer than the max length 32766
java添加数据到solr报错 whose UTF8 encoding is longer than the max length 32766 原因是长度太长,string类型改成text_gener ...