初次用R的实际案例数据分析
这是一次教授布置的期末作业,也是书籍《商务数据分析与应用》的一个课后作业
目录
数据描述
数据预处理
描述性统计分析
模型分析(方差分析)
数据描述
非学位职业培训机构的178个学员的数据,目的是了解什么样的学员可能获得更好的学习效果
数据预处理
打开数据,查看一部分数据并锁定数据(这样之后可以直接使用变量名而不用$来指定数据)
grades=read.table('E:/SWlearning/R/assighment/RegressionAnalysis/Report/ins1.csv',
header=TRUE,sep=',')
head(grades)
attach(grades)
*结果显示*

*将变量名改成英文*
```
names(grades)=c('aveGrades','gender','birth','firmType','eduBG','eduGrd')
<br/>
响应变量(因变量):因变量.平均成绩(aveGrades)
自变量:性别(gender),出生日期(birth),企业性质(firmType),最高学历(eduBG),最高学历毕业时间(eduGrd)
<br/>
*检查相应变量的正态性*
shapiro.test(aveGrades)
<br/>
*结果显示*
Shapiro-Wilk normality test
data: aveGrades
W = 0.89736, p-value = 9.286e-10
<br/>
p值非常的小故拒绝原假设,即拒绝数据是正态分布的原假设
<br/>
*接下来用BoxCox的方法,建立新的相应变量从而保证其正态性,注意BoxCox.ar是包TSA里的函数*
library(TSA)
boxcox=BoxCox.ar(aveGrades,lambda = seq(4, 8, 0.1))
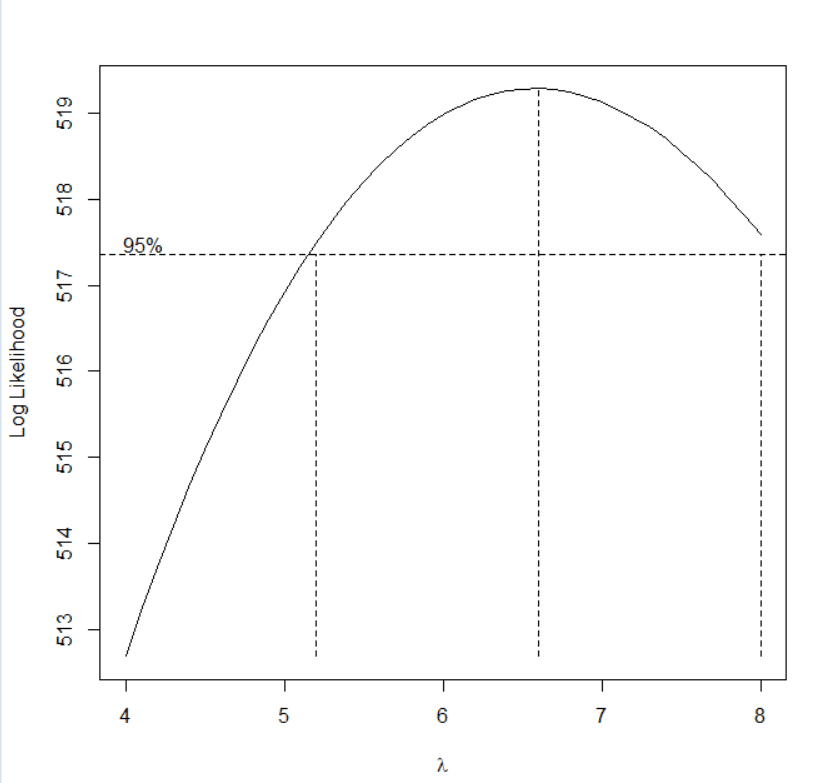
<br/>
*查看最优的lamda值*
boxcox$mle

<br/>
*建立新的响应变量*
aveGrades_mod=grades$aveGrades^6.6
<br/>
*检验新的响应变量的正态性*
shapiro.test(aveGrades_mod)
<br/>
*结果显示*
Shapiro-Wilk normality test
data: aveGrades_mod
W = 0.99007, p-value = 0.2522
<br/>
p值达到了我们期望的结果,不拒绝原假设,即接受新的响应变量是正态分布的假设
<br/>
#描述性统计分析
<br/>
*注意我们的因变量中,出生日期(birth)和最高学历毕业时间(eduGrd)不是离散变量,我们将以十年的单位将这两个变量分类
出生日期(birth)中最大是 1952-6-26,最小是 1979-11-10,分成五十年代(1),六十年代(2), 七十年代(3)
最高学历毕业时间(eduGrd)中最大是 1982-1-1,最小是 2004-3-1,分为八十年代(1),九十年代(2), 零零后(3)*
<br/>
*第一步
将出生日期(birth)和最高学历毕业时间(eduGrd)变成日期型变量以便之后的操作*
birthmod=as.Date(grades$birth)
eduGrdmod=as.Date(grades$eduGrd)
<br/>
*第二步
我们先对出生年月进行分类*
//d1~d4分别是四个时间节点,用来将数据分成五十年代(1),六十年代(2), 七十年代(3)
d1=as.Date('1950/1/1')
d2=as.Date('1960/1/1')
d3=as.Date('1970/1/1')
d4=as.Date('1980/1/1')
//计算出生日期(birthmod)中的数据个数
s=0
for(i in birthmod){
s=s+1
}
//建立新的数值型变量。因为birthmod是日期型变量,不能直接赋数值型的值如1,2,3
birth_mod=1:s
//开始分类
for(i in 1:s){
fac1=birthmod[i]-d1>0 & birthmod[i]-d2<=0
fac2=birthmod[i]-d2>0 & birthmod[i]-d3<=0
fac3=birthmod[i]-d3>0 & birthmod[i]-d4<=0
if(fac1){birth_mod[i]=1}
if(fac2){birth_mod[i]=2}
if(fac3){birth_mod[i]=3}
}
//给新变量birth_mod三个水平1,2,3
levels(birth_mod)=c(1,2,3)
//将数据类型变成factor,以便之后的统计
birth_mod=as.factor(birth_mod)
<br/>
*对最高学历毕业时间是同样的程序*
d5=as.Date('1990/1/1')
d6=as.Date('2000/1/1')
d7=as.Date('2010/1/1')
s=0
for(i in eduGrdmod){
s=s+1
}
eduGrd_mod=1:s
for(i in 1:s){
fac3=eduGrdmod[i]-d4>0 & eduGrdmod[i]-d5<=0;fac3
fac4=eduGrdmod[i]-d5>0 & eduGrdmod[i]-d6<=0;fac4
fac5=eduGrdmod[i]-d6>0 & eduGrdmod[i]-d7<=0;fac5
if(fac3){eduGrd_mod[i]=1}
if(fac4){eduGrd_mod[i]=2}
if(fac5){eduGrd_mod[i]=3}
}
levels(eduGrd_mod)=c(1,2,3)
eduGrd_mod=as.factor(eduGrd_mod)
<br/>
*第三步
建立新的数据集grades_mod,注意此处的响应变量(aveGrades)没有用之前为了正态性修改的新的响应变量(aveGrades_mod),这里用aveGrades是为了结果好看,且不影响我们进行描述性统计分析*
grades_mod=cbind(grades$aveGrades,grades[2],birth_mod,grades[4:5],eduGrd_mod)
summary(grades_mod)
*结果显示*
grades$aveGrades gender birth_mod firmType eduBG eduGrd_mod
Min. :50.00 男:133 1:10 国企:95 本科 :148 1: 48
1st Qu.:77.00 女: 45 2:85 民企:43 大专 : 25 2:104
Median :81.00 3:83 外企:40 硕士 : 2 3: 26
Mean :79.72 硕士或以上: 3
3rd Qu.:84.00
Max. :91.00
<br/>
*第四步
我们还想知道,各个因变量不同水平对应的学员平均成绩*
//编写一个输出均值,标准差,最大值,中位数,最小值的函数
stats = function(x){
m = mean(x)
sd= sd(x)
max = max(x)
median = median(x)
min= min(x)
return=c(m,sd,max,median,min)
}
//aggregate是一个重新显示数据的函数,比如在aggdata1中,能显示按性别分类后,男性学员和女性学员对应的平均成绩的均值,标准差,最大值,中位数,最小值,FUN是function函数的意思
aggdata1= aggregate(grades['aveGrades'],
by=list(gender),FUN=stats);aggdata1
aggdata2= aggregate(grades['aveGrades'],
by=list(birth_mod),FUN=stats)
aggdata3= aggregate(grades['aveGrades'],
by=list(firmType),FUN=stats)
aggdata4= aggregate(grades['aveGrades'],
by=list(eduBG),FUN=stats);aggdata
aggdata5= aggregate(grades['aveGrades'],
by=list(eduGrd_mod),FUN=stats)
//按行将数据重叠起来
aggdata=rbind(aggdata1,aggdata2,aggdata3,aggdata4,aggdata5);aggdata
<br/>
*结果显示*
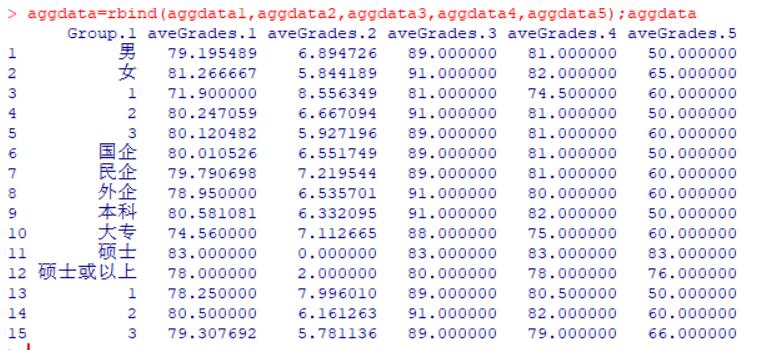
<br/>
#模型分析
*接下来我们将进行方差分析*
*第一步*
//进行方差分析的函数是aov,前面是响应变量,注意此时我们得保证响应变量的正态性,所以用的是新的响应变量(aveGrades_mod)而非原始数据,后面是自变量,在此模型中还包括了所有的交互项
res.ano1=aov(aveGrades_mod~gender+birth_mod+firmType+eduBG+eduGrd_mod+
gender:birth_mod+gender:firmType+gender:eduBG+gender:eduGrd_mod+
birth_mod:firmType+birth_mod:eduBG+birth_mod:eduGrd_mod+
firmType:eduBG+firmType:eduGrd_mod+
eduBG:eduGrd_mod)
//显示方差分析结果
res1=summary(res.ano1);res1
<br/>
*结果显示*

<br/>
*第二步
剔除没通过显著性检验的变量, 用剩下的变量再做一次方差分析*
res.ano2=aov(aveGrades_mod~gender+birth_mod+eduBG+
gender:firmType+gender:eduGrd_mod+
birth_mod:firmType+
firmType:eduBG)
res2=summary(res.ano2);res2
<br/>
*结果显示*
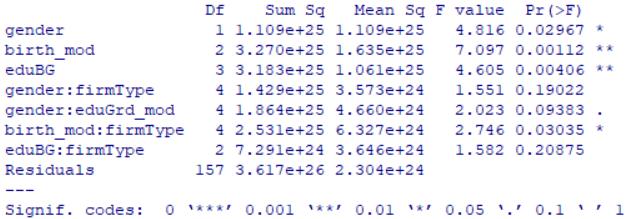
<br/>
*第三步
剔除没通过显著性检验的变量, 用剩下的变量再做一次方差分析*
res.ano3=aov(aveGrades_mod~gender+birth_mod+eduBG+
gender:eduGrd_mod+
birth_mod:firmType)
res3=summary(res.ano3);res3
<br/>
*结果显示*
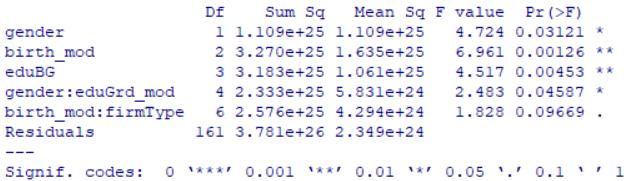
<br/>
性别(gender),出生日期(birth_mod),最高学历(eduBG)以及交互作用, 性别:最高学历毕业日期(gender:eduGrd_mod),出生日期:企业性质(birth_mod:firmType)都通过了在 0.1 水平下的显著性检验
拒绝原假设,即变量的水平不同会显著影响成绩,如性别中,男生和女生的成绩显著不同,而企业性质的不同不影响学员的成绩初次用R的实际案例数据分析的更多相关文章
- 用 R 进行高频金融数据分析简介
作者:李洪成 摘自:http://cos.name/wp-content/uploads/2013/11/ChinaR2013SH_Nov03_04_LiHongcheng.pdf 高频数据 金融市场 ...
- R vs Python,数据分析中谁与争锋?
R和Python两者谁更适合数据分析领域?在某些特定情况下谁会更有优势?还是一个天生在各方面都比另一个更好? 当我们想要选择一种编程语言进行数据分析时,相信大多数人都会想到R和Python——但是从这 ...
- R语言-上海二手房数据分析
案例:通过分析上海的二手房的数据,分析出性价比(地段,价格,未来的升值空间)来判断哪个区位的二手房性价比最高 1.载入包 library(ggplot2) library(Hmisc) library ...
- 分类算法的R语言实现案例
最近在读<R语言与网站分析>,书中对分类.聚类算法的讲解通俗易懂,和数据挖掘理论一起看的话,有很好的参照效果. 然而,这么好的讲解,作者居然没提供对应的数据集.手痒之余,我自己动手整理了一 ...
- R中的空间数据分析
> library(sp) > library(maptools) > library(raster) > library(rgeos) > maxd3 = readAs ...
- 92、R语言分析案例
1.读取数据 > bank=read.table("bank-full.csv",header=TRUE,sep=";") > 2.查看数据结构 & ...
- 【R】爬虫案例
爬取豆瓣相册 library(RCurl) library(XML) myHttpheader <- c("User-Agent"="Mozilla/5.0 (Wi ...
- 【翻译】Awesome R资源大全中文版来了,全球最火的R工具包一网打尽,超过300+工具,还在等什么?
0.前言 虽然很早就知道R被微软收购,也很早知道R在统计分析处理方面很强大,开始一直没有行动过...直到 直到12月初在微软技术大会,看到我软的工程师演示R的使用,我就震惊了,然后最近在网上到处了解和 ...
- R统计分析处理
[翻译]Awesome R资源大全中文版来了,全球最火的R工具包一网打尽,超过300+工具,还在等什么? 阅读目录 0.前言 1.集成开发环境 2.语法 3.数据操作 4.图形显示 5.HTML部件 ...
随机推荐
- Docker 容器命令大全
容器命令: 命令 描述 attach 将本地标准输入,输出和错误流转到到正在运行的容器 build 从Dockerfile构建映像 commit 根据容器的更改创建新镜像 cp 在容器和本地文件系统之 ...
- React的jsx语法,详细介绍和使用方法!
jsx语法 一种混合使用html及javascript语法的代码 在js中 遇到<xx>即开始html语法 遇到</xx>则结束html语法 恢复成js语法 例如: let D ...
- js javascript 如何获取某个值在数组中的下标
js 某个值在数组中的下标javascript中知道一个数组中的一个元素的值,如何获取数组下标JS 获取数组某个元素下标 函数方法 采用prototype原型实现方式,查找元素在数组中的索引值js查找 ...
- maven 学习---使用Maven模板创建项目
在本教程中,我们将向你展示如何使用mvn archetype:generate从现有的Maven模板列表中生成项目.在Maven 3.3.3,有超过1000+个模板,Maven 团队已经过滤掉一些无用 ...
- 高性能TcpServer(C#) - 5.客户端管理
高性能TcpServer(C#) - 1.网络通信协议 高性能TcpServer(C#) - 2.创建高性能Socket服务器SocketAsyncEventArgs的实现(IOCP) 高性能TcpS ...
- EM算法直观认识
Expectation Maximization, 字面翻译为, "最大期望". 我个人其实一直都不太理解EM算法, 从我个人的渊源来看, 之前数理统计里面的参数估计, 也是没有太 ...
- Git的认识与使用
Git教程 https://www.liaoxuefeng.com/wiki/896043488029600/897271968352576 Git与SVN区别 Git 不仅仅是个版本控制系统,它也是 ...
- 5-剑指offer: 和为S的两个数字
题目描述 输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的. 输出描述: 对应每个测试案例,输出两个数,小的先输出. 代码 ...
- 《面向对象程序设计(java)》第十周学习总结
201871010115 马北<面向对象程序设计(java)>第十周学习总结 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh ...
- 201871010124--王生涛--《面向对象程序设计(java)》第十二周学习总结
博文正文开头格式: 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nw ...