四、spark集群架构
spark集群架构官方文档:http://spark.apache.org/docs/latest/cluster-overview.html
集群架构
我们先看这张图
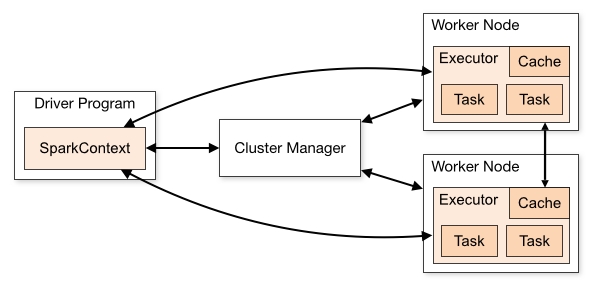
这张图把spark架构拆分成了两块内容:
1)spark应用程序:即左边的DriverProgram这块;
2)spark 集群:即右边的ClusterManager和另外两个Worker Node;
这样的结构,我们大概可以猜测一下spark是怎么工作的。首先我们会编写一个spark程序,然后启动spark集群,这个spark程序需要和spark集群交互并让spark集群运行计算并最终产生结果。
下面,分别看看什么是spark程序,什么是spark集群
什么是spark应用程序?
spark应用程序指的就是我们编写程序代码,我们的程序代码会包含一个驱动程序Driver,有了这个Driver它会调用程序的main方法去启动我们的程序,并创建一个SparkContext。
当我们的sparkContext创建完成之后,我们的程序就可以通过sparkContext和Spark集群进行交互了。
如:Driver -> 调用main() -> 创建sparkContext -> 与spark集群交互
什么是spark集群?
spark集群分为三种运行模式:standalone、yarn、mesos
为了排除干扰因素,我们这里只以standalone来理解spark集群
我们先看上图右侧部分,spark集群分为两部分:Cluster Manager和两个WorkNode。这个结构就是一个很明显的master-slaver(主从)的结构,由master来负责资源管理,而slaver来负责执行相应的任务。
sparkContext在与Cluster Manager建立连接以后就会向Cluster Manager申请资源,之后sparkContext把程序代码解析成一些task,并把这些task分发给WorkNode让WorkNode去执行task。直到所有的task执行完毕以后,sparkContext会注销,并释放资源。
如:sparkContext -> 连接ClusterManager -> 申请资源 -> 解析成多个task -> 分发给workNode -> 执行task -> 执行完毕释放资源
总结
当前Driver启动以后,会去执行应用程序的main方法,并构建sparkConext对象。sparkContext与ClusterManager连接交互,并且sparkContext将程序代码解析成多个task,将task发送给workNode,workNode又会把task丢给任务执行器executor去执行,executor会启动线程池开始执行task。当所有的task执行完毕,spark向ClusterManager注销,并释放资源。
下面是spark集群架构的一些概念:
| Application | 用户编程的spark程序. 包含一个Driver驱动程序和executor要执行的代码 |
| Application jar | 一个包含spark应用程序的jar包 |
| Driver program | 驱动程序,包含在application当中,用于执行main方法和创建sparkContext。注意:Driver可以运行在Client中,也可以运行在master中。例如,当使用spark-shell提交spark job的时候Driver运行在master上,当使用spark-submit提交或者IDEA开发的时候Driver运行在Client上 |
| Cluster manager | spark集群,主要有三种运行模式在standalone(默认)、yarn、mesos,你也可以理解为后两者是基于standalone的 |
| Deploy mode | 部署模式,分为单机部署、伪分布式、完全分布式 |
| Worker node | spark的集群的从节点,用于执行任务 |
| Executor | 任务的执行器,存在于workNode当中 |
| Task | application的代码被解析成许多task,并发送给executor去执行 |
| Job | 当碰到action操作的时候就会催生job,job中包含着多个task并行计算 |
| Stage | task的组 |
| Client | 客户端程序,用于提交spark job |
这里的job、task、stage你可能会产生疑惑,它们具体是什么东西
spark的应用程序包含着用户编写的可执行代码,那么这些程序代码会被sparkContext解析成一个叫有向无环图(dag)的结构(这里我们不讨论dag,只需要知道它是一种结构)。
而后,当碰到一个action这种代码操作的时候,就会根据dag结构去催生job。这个job包含着许多task,而这些混乱的task需要被组织起来,task的组就是stage。
如:task -> 分组 -> stage -> 组成 -> job
四、spark集群架构的更多相关文章
- Spark集群架构
集群架构 SparkContext底层调度模块 Spark集群架构细化
- Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力.Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 从0到1搭建spark集群---企业集群搭建
今天分享一篇从0到1搭建Spark集群的步骤,企业中大家亦可以参照次集群搭建自己的Spark集群. 一.下载Spark安装包 可以从官网下载,本集群选择的版本是spark-1.6.0-bin-hado ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
随机推荐
- IIS7的网站通过https访问提示ssl_error_rx_record_too_long
IIS7的网站通过https访问,提示ssl_error_rx_record_too_long,如下图所示: 解决办法: 一.导入服务器的SSL证书至IIS 1.打开IIS,找到服务器证书 2.导入本 ...
- robot framework踩坑记录
一.报错:FAIL : 'Return' is a reserved keyword. 给Retrun加上中括号即可 二.报错:True != true 三.报错 /Library/Python/2. ...
- 初探APT 攻击
作者:joe 所属团队:Arctic Shell 本文编写参考: https://www.freebuf.com/vuls/175280.html https://www.freebuf. ...
- 【JVM】jvm启动参数
-server -Xmx2048m -Xms1500m -Xmn1024m -XX:PermSize=128m -Xss256k -XX:+DisableExplicitGC -XX:+UseConc ...
- 解决 MySQL 1045错误的三种方法 (转)
连接MySQL数据库时难免会遇到1045错误,主要是因为用户输入的用户名或密码错误被拒绝访问,如果不想重装,需要找回密码或者重置密码. 问题描述: 1045-Access denied for use ...
- iOS关于代码风格问题
cocoapods管理第三方库,详见cocoapods安装及使用 OC代码风格需要规范,所有第三方依赖需要用cocoapods管理.代码风格需要: 1. pod 'CodeFormatter', :g ...
- ThreadLocal系列(二)-InheritableThreadLocal的使用及原理解析
ThreadLocal系列之InheritableThreadLocal的使用及原理解析(源码基于java8) 上一篇:ThreadLocal系列(一)-ThreadLocal的使用及原理解析 下一篇 ...
- 【App性能】:TraceView分析法
抓取traceview的日志有两种方式, 1,是在代码中片段中添加: Debug.startMethodTracing(“hello”); ....... Debug.stopMethodTracin ...
- Cisco ASA 8.3前及8.3后版本Access-list 变化
8.2及之前 access-list:源地址是真实IP地址,目的地址是映射地址packet-tracer:源地址为真实IP地址,目的地址为映射地址 8.3及之后access-list:源地址和目的地址 ...
- 检查SQL语句是否合法
昨天又有一个新的需求:验证文本框输入的SQL语法是否正确. 于是就开始百度,其实也挺简单的. 首先需要知道“SET PARSEONLY { ON | OFF }”. 当 SET PARSEONLY 为 ...