HBase 第四章 HBase原理
1 体系图
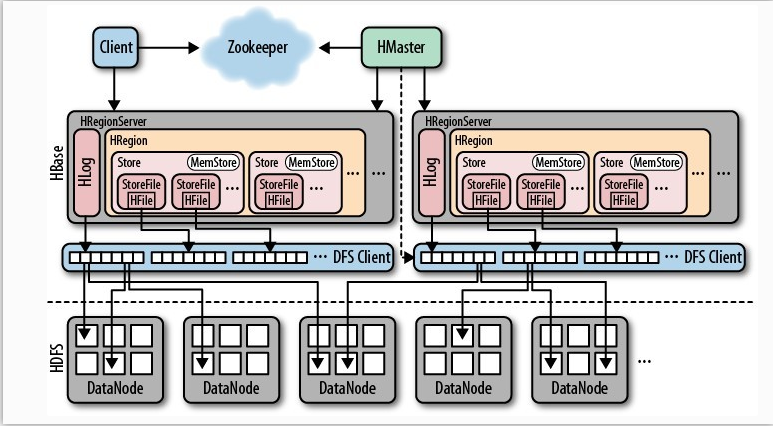
HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
HMaster
1、为Region server分配region
2、负责Region server的负载均衡
3、发现失效的Region server并重新分配其上的region
4、HDFS上的垃圾文件回收
5、处理schema更新请求
HRegionServer
1、维护master分配给他的region,处理对这些region的io请求。
2、负责切分正在运行过程中变的过大的region。
3、可以看到,client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。 HRegionServer存取一个子表时,会创建一个HRegion对象,
然后对表的每个列族创建一个Store实例,每个Store都会有一个MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile, HFile就是实际的存储文件。
因此,一个HRegion有多少个列族就有多少个Store。 一个HRegionServer会有多个HRegion和一个HLog。
HRegion
1、table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一般是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
2、每个region由以下信息标识:
2.1 < 表名,startRowkey,创建时间>
2.2 由目录表(-ROOT-和.META.)记录该region的endRowkey
3、HRegion定位:Region被分配给哪个Region Server是完全动态的,所以需要机制来定位Region具体在哪个region server。
4、HBase使用三层结构来定位region:
4.1 通过zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
4.2 通过-ROOT-表查找.META.表的第一个表中相应的region的位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个region在-ROOT-表中都是一行记录。
4.3 通过.META.表找到所要的用户表region的位置。用户表中的每个region在.META.表中都是一行记录。
5、-ROOT-表永远不会被分隔为多个region,保证了最多需要三次跳转,就能定位到任意的region。client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region,其中三次用来发现缓存失效,
另外三次用来获取位置信息。
6、table 和region 的关系:
6.1 table 默认最初只有一个region,随着记录数的不断增加而变大,起初的region会逐渐分裂成多个region,一个region有【startkey,endkey】表示,不同的region会被master分配给相应的regionserver管理。
6.2 region 是hbase分布式存储和负载均衡的最小单元,不同的region分不到不同的regionserver。
6.3 region 虽然是分布式存储的最小单元,但并不是存储的最小单元
6.4 region 是由一个或者多个store 组成的,每个store就是一个 column family,每个stroe 又由一个memstore 和 1至多个store file组成(memstore 到一个阈值会刷新,写入到storefile,有hlog 来保证数据的安全性,一个 regionserver 有且只有一个hlog
Store
每一个region由一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。
HBase以store的大小来判断是否需要切分region
MemStore
memStore 是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。
StoreFile
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HFile
HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。 Data Block是hbase io的基本单元,为了提高效率,
HRegionServer中有基于LRU的block cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,
Magic内容就是一些随机数字,目的是防止数据损坏。
HLog
其实HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,sequence number的起始值为0,或者是最近
一次存入文件系统中的sequence number。 Sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue。
Client
HBASE Client使用HBASE的RPC机制与HMaster和RegionServer进行通信
管理类操作:Client与HMaster进行RPC
数据读写类操作:Client与HRegionServer进行RPC.
2 流程介绍
2.1 写流程
2.1.1 client向hregionserver发送写请求。
2.1.2 hregionserver将数据写到hlog(write ahead log)。为了数据的持久化和恢复。
2.1.3 hregionserver将数据写到内存(memstore)
2.1.4 反馈client写成功。
2.2 数据flush 过程
2.2.1 当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除,同时删除Hlog中的历史数据。
2.2.2 并将数据存储到hdfs中。
2.2.3 在hlog中做标记点。
2.3 数据合并过程
2.3.1 当数据块达到4块,hmaster将数据块加载到本地,进行合并。
2.3.2 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理。
2.3.3 当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
2.3.4 注意:hlog会同步到hdfs。
2.4 hbase的读流程
2.4.1 通过zookeeper和-ROOT- .META.表定位hregionserver。
2.4.2 数据从内存和硬盘合并后返回给client。
2.4.3 数据块会缓存
HBase 第四章 HBase原理的更多相关文章
- HBase(四)HBase集群Shell操作
一.进入HBase命令行 在你安装的随意台服务器节点上,执行命令:hbase shell,会进入到你的 hbase shell 客 户端 [admin@node21 ~]$ hbase shell S ...
- 郑捷《机器学习算法原理与编程实践》学习笔记(第四章 推荐系统原理)(二)kmeans
(上接第二章) 4.3.1 KMeans 算法流程 算法的过程如下: (1)从N个数据文档随机选取K个文档作为质心 (2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类 (3)重新计 ...
- 【HBase】四、HBase的安装及命令行接口
通过前面的介绍,对HBase数据模型,运行机制等理论基本了解,接下来从实践的角度介绍HBase的安装以及其各种接口的使用方法. 1.HBase的安装 HBase安装很简单,和所有的Hadoop ...
- 第四章:大数据 の HBase 基础
本课主题 NoSQL 数据库介绍 HBase 基本操作 HBase 集群架构与设计介紹 HBase 与HDFS的关系 HBase 数据拆分和紧缩 引言 介绍什么是 NoSQL,NoSQL 和 RDBM ...
- Hbase学习之概念与原理
一.hbase与列式存储 hbase最早起源于谷歌的一篇BigTable的论文,它是由java编写的.开源的一个nosql数据库,同时它也是一个列式存储的.支持分布式(基于hdfs)的数据库.什么是列 ...
- 8.HBase In Action 第一章-HBase简介(1.2.2 捕获增量数据)
Data often trickles in and is added to an existing data store for further usage, such as analytics, ...
- hadoop(四): 本地 hbase 集群配置 Azure Blob Storage
基于 HDP2.4安装(五):集群及组件安装 创建的hadoop集群,修改默认配置,将hbase 存储配置为 Azure Blob Storage 目录: 简述 配置 验证 FAQ 简述: hadoo ...
- HBase 事务和并发控制机制原理
作为一款优秀的非内存数据库,HBase和传统数据库一样提供了事务的概念,只是HBase的事务是行级事务,可以保证行级数据的原子性.一致性.隔离性以及持久性,即通常所说的ACID特性.为了实现事务特性, ...
- Android艺术开发探索第四章——View的工作原理(下)
Android艺术开发探索第四章--View的工作原理(下) 我们上篇BB了这么多,这篇就多多少少要来点实战了,上篇主席叫我多点自己的理解,那我就多点真诚,少点套路了,老司机,开车吧! 我们这一篇就扯 ...
随机推荐
- fastjson反序列化TemplatesImpl
环境参考第一个链接,直接用IDEA打开 编译EvilObject.java成EvilObject.class 先看poc,其中NASTY_CLASS为TemplatesImpl类,evilCode是E ...
- 通过css使文字有渐变的效果
<style> .color{ background-image: -webkit-gradient(linear, left center, right center, from(rgb ...
- 9、Web Service-IDEA-jaxrs 服务端客户端的实现
关于RestFul编程可以参考:https://www.cnblogs.com/wang-yaz/p/9237981.html 关于jaxrs的实现需要有restful的理解. 话不多说直接上代码!! ...
- 关于selenium获取token sessionid
# 获取sessionid def get_sessionid(self): # 是要从localStorage中获取还是要从sessionStorage中获取,具体看目标系统存到哪个中 # wind ...
- UVALive - 6837 Kruskal+一点性质(暴力枚举)
ICPC (Isles of Coral Park City) consist of several beautiful islands. The citizens requested constru ...
- ArrayList两个对象之间的赋值
List<String> list1 = new ArrayList<String>(); List<String> list2 = new ArrayList&l ...
- 关于TCP传输的三次握手四次挥手策略
简单小总结: 一般为了能够准确无误地把数据送达目标处,TCP协议采用了三次握手策略.用TCP协议把数据包送出去后,TCP不会对传送后的情况置之不理,它一定会向对方确认是否成功送达. 注:握手过程中使用 ...
- solr 服务器搭建(Linux版)
1.下载访问linux工具 securcrt 链接:https://pan.baidu.com/s/1zTwzmnzUmnwbKUCNHCLN1g 密码:kpyg 2.下载所需的 jdk so ...
- Sppring MVC核心应用-2
一.Spring MVC框架中400状态码的请求错误:控制台BindException异常, 解决方法: 二.Sping 表单标签 三.数据校验 实现JSR 303验证步骤 四.REST风格 五.Sp ...
- HTML5视频播放练习:鼠标经过视频播放,鼠标移除停止播放,再次经过继续播放。
随着HTML5的广泛应用,在一些网站中,经常看到有些预览的短视频预览,鼠标经过就会播放,移除就会停止播放,再次移进去就会继续播放. 自己也研究着做一个比较简单的类似的练习. 视频可以自己到包图网下载, ...