一个数据仓库时代开始--Hive
###一、什么是 Apache Hive?
Apache Hive 是一个基于 Hadoop Haused 构建的开源数据仓库系统,我们使用它来查询和分析存储在 Hadoop 文件中的大型数据集。此外,通过使用 Hive,我们可以在 Hadoop 中处理结构化和半结构化数据。
换句话说,Hive 是一个数据仓库基础设施,便于查询和管理驻留在分布式存储系统中的大型数据集。它提供了一种类 SQL 的查询语言 HiveQL(Hive Query Language)查询数据的方法。 此外,编译器在内部将 HiveQL 语句转换为 MapReduce、Tez、Spark 等作业。进一步提交给 Hadoop 框架执行。
二、我们为什么要使用 Hive 技术?
随着 Hadoop MapReduce 的出现,极大的简化大数据编程的难度,使得普通程序员也能从事开发大数据编程。但在生产活动中经常要对大数据计算分析是从事商务智能行业(BI)的工程师,他们通常使用 SQL 语言进行大数据统计以及分析,而 Mapreduce 编程是有一定的门槛,如果每次都采用 MapReduce 开发计算分析,这样成本就太高效率太低,那么有没有更简单的办法,可以直接通过 SQL 在大数据平台下运行进行统计分析?有的,答案即是 Hive。
Hive 主要用于数据查询,统计和分析,提高开发人员的工作效率。Hive 通过内置函数将 SQL 语句生成 DAG(有向无环图),再让 Mapreduce 计算处理。从而得到我们想要的统计结果。而且在处理具有挑战性的复杂分析处理和数据格式时,极大的简化了开发难度。
三、Hive 架构
Hive 能够直接处理我们输入的 HiveQL 语句,调用 MapReduce 计算框架完成数据分析操作。下面是它的架构图,我们结合架构图来看看 Hive 到 MapReduce 整个流程。
由上图可知,HDFS 和 Mapreduce 是 Hive 架构的根基。Hive 架构主要分为以下几个组件:Client、Metastore、Thrift Server、Driver,下面是各个组件介绍:
Client:用户接口组件主要包含 CLI(命令行接口)、JDBC 或 ODBC、WEB GUI(以浏览器访问 Hive);
Metastore组件:元数据服务组件, 记录表名、字段名、字段类型、关联 HDFS 文件路径等这些数据库的元数据信息;
Driver(执行引擎):包括 Complier 、Optimizer 和 Executor,它们的作用是将 HiveQL 语句进行语法分析、语法解析、语法优化,生成执行计划,然后提交给 Hadoop MapReduce 计算框架处理;
Thrift Server:Thrift 是 FaceBook 开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发, 通过该服务使不同编程语言调用 Hive 的接口。
我们通过 CLI 向 Hive 提交 SQL 命令,如果 SQL 是创建数据表的 DDL,Hive 会通过 执行引擎 Driver 将数据表元数据信息存储 Metastore 中,而如果 SQL 是查询分析数据的 DQL,通过 Complier 、Optimizer 和 Executor 进行语法分析、语法解析、语法优化操作,生成执行计划生成一个 MapReduce 的作业,提交给 Hadoop MapReduce 计算框架处理。
到此 Hive 的整个流程就结束了,相信你对 Hive 的整个流程已经有基本了解。接下来我们探讨一条 SQL 在 MapReduce 是如何统计分析。
四、SQL如何在Mapreduce执行
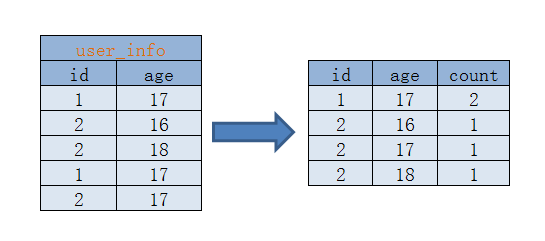
左边是数据表,右边是结果表,这条 SQL 语句对 age 分组求和,得到右边的结果表,到底一条简单的 SQL 在 MapReduce 是如何被计算, MapReduce 编程模型只包含 map 和 reduce 两个过程,map 是对数据的划分,reduce 负责对 map 的结果进行汇总。
select id,age,count(1) from student_info group by age
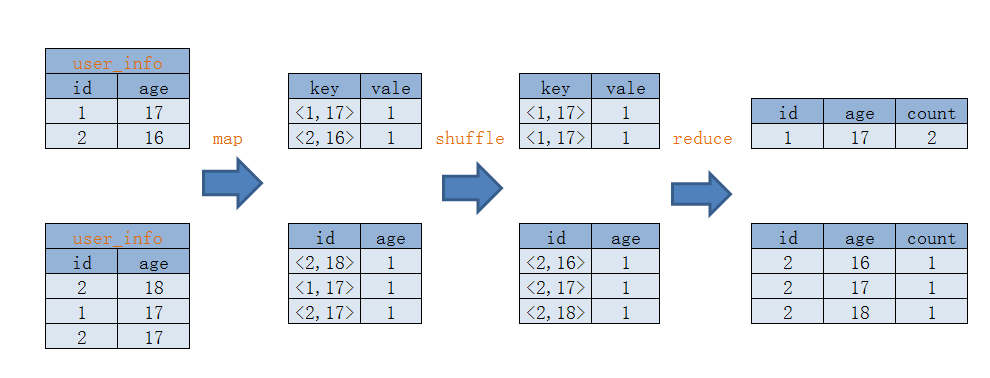
首先看 map 函数的输入的 key 和 value,输入主要看 value,value 就是 user_info 表的每一行数据,输入的 value 作为map函数输出的 key,输出的 value 固定为 1,比如<<1,17>,1>。 map 函数的输出经过 shuffle 处理,shuffle 把相同的 key 以及对应的 value 组合成新<key,value集合>,从 user_info 表看出map输出 2 次<<1,17>,1>,那么经过 shuffle 处理后则会输出<<1,17>,<1,1>>,并将输出作为 reduce 函数的输入。
在 reduce 函数会把所有 value 进行相加后输出结果,<<1,17>,<1,1>>输出为<<1,17>,2>。 这就是一条简单 SQL 在 Mapreduce 执行过程,可能你会有点迷糊,在这里我画了一张流程图,结合流程图你会更加清楚。
五、Hive 和 RDBMS 之间的区别
说到 Hive 跟 RDBMS(传统关系型数据库)相比有哪些区别,很多人可能还是说不清楚,在这里我总结一下关于 Hive 和 RDBMS 之间的区别。
1、Hive 支持部分 SQL 语法,跟标准 SQL 有一定区别。
2、传统的数据库在写入数据会严格检验数据格式,对于这种我们成为读时模式,而 Hive 是在查询数据时验证数据,这种验证我们称为写时模式,而且由于每次都是扫描整个表导致高延时;
3、Hive 是在 Hadoop 上运行的,通常而言 Hive 时一次写入多次读取,而 RDBMS 则是多次读写;
4、Hive 视图是逻辑存在,而且只读,不接受 LOAD/INSERT/ALTER,而 RDBMS 视图根据表变化而变化;
5、Hive 支持多表插入而 RDBMS 是不支持,而且 Hive 对子查询有严格要求,有许多子查询是不支持;
6、早期 Hive 只支持 INSERT OVERWRITE\INTO TABLE 插入数据,从 0.14.0 开始支持 INSERT INTO ... VALUE 语句按行添加数据,另外 UPDATE 和 DELETE 也允许被执行;
7、在 Hive 0.7.0 之后 Hive 是支持索引的,只是它跟 RDBMS 不一样,比如它不支持主键和外键,而是支持在某些列上建立索引,以提高 Hive 表指定列的查询速度(但是效果差强人意);
其实对于更新、事物和索引,一开始 Hive 是不支持的,因为这样非常影响性能,不符合当初数据仓库的设计,不过后来不断的发展,也不得不妥协,这也导致 Hive 和 RDBMS 在形式上更加相识。
相信看完这些大家已经对它们之间区别有了一些理解,在这里我还贴出一张表格,你可以对照表格加深印象。
| 比较项 | RDBMS | Hive |
|---|---|---|
| ANSI SQL | 支持 | 不完全支持 |
| 更新 | UPDATE\INSERT\DELETE | UPDATE\INSERT\DELETE(0.14.0之后) |
| 模式 | 读时模式 | 写时模式 |
| 数据保存 | 磁盘 | HDFS |
| 延时 | 低 | 高 |
| 多表插入 | 不支持 | 支持 |
| 子查询 | 完全支持 | 支持 From 子句 |
| 视图 | Updatable | Read-only |
| 索引 | 支持 | 支持表列(0.7.0之后) |
| 可扩展性 | 低 | 高 |
| 数据规模 | 小 | 大 |
| 读写 | 一次写入多次读取 | 多次读写 |
| 分析 | OLTP | OLAP |
| 执行 | Excutor | MapReduced、Spark等 |
**小结**
在实际生产过程中,其实我们不会经常编写 MapReduce 程序,起初在网站的大数据分析基本是通过 SQL 进的,也因此 Hive 在大数据中扮演着非常重要作用。随着 Hive 的普及,我们希望更多的大数据应用场景中使用 SQL 语句进行分析,于是现在越来越多的大数据 SQL 引擎被开发出来。在我看来无论是 Cloudera 的 Impala,还是后来的 Spark ,对大数据中使用 SQL需求越来迫切, 对大数据 SQL 应用场景更多样化,我们只需要通过 SQL 语句就可以轻易得到我们想要的结果。最后说一点,在这些 SQL 引擎基本都是支持类 SQL 语言,但并不像数据库那样支持那样标准 SQL,特别是 Hive 等数据仓库几乎必然会用到嵌套查询 SQL,也就是在 where 条件嵌套 select 子查询,但是几乎所有的大数据 SQL 引擎都不支持。
一个数据仓库时代开始--Hive的更多相关文章
- 基于hadoop的数据仓库工具:Hive概述
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点是学习成本低,可以通过类 ...
- 数据仓库工具:Hive
转载请标明出处: http://blog.csdn.net/zwto1/article/details/46430823: 本文出自:[明月的博客] 为什么要选择Hive 基于Hadoop的大数据的计 ...
- 数据仓库组件:Hive环境搭建和基础用法
本文源码:GitHub || GitEE 一.Hive基础简介 1.基础描述 Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取.转化.加载,是一个可以对Hadoop中的大规模存储的数据进 ...
- 一个新时代的UI设计师需要具备这些技能
如今互联网行业发展如日中天,设计师本就是稀缺人才.再加上未来也将迎接人工智能时代,未来的设计师不只像现在只是做一些网页.APP界面,还会出现更多的UI设计衍生职业.如下列举的几大类: 一.初级阶段 1 ...
- 960网格,一个web时代的标志。
如果你不知道什么是CSS框架,可以回顾我的文章 css框架,一把锋利的剑 闲言少叙,废话不说,直入正题: 1.什么是CSS框架? 正如之前说的: CSS框架是一种你能够使用在你的web项目中概念上的结 ...
- Hadoop Hive概念学习系列之什么是Hive?(一)
参考 <Hadoop大数据分析与挖掘实战>的在线电子书阅读 http://yuedu.baidu.com/ebook/d128cf8e33687e21 ...
- 什么是hive
Hadoop Hive概念学习系列之什么是Hive? 参考 <Hadoop大数据分析与挖掘实战>的在线电子书阅读 http://yuedu.baidu ...
- Hadoop Hive概念学习系列之什么是Hive?
参考 <Hadoop大数据分析与挖掘实战>的在线电子书阅读 http://yuedu.baidu.com/ebook/d128cf8e33687e21 ...
- Hive学习(一)
https://www.cnblogs.com/qingyunzong/p/8707885.html http://www.360doc.com/content/16/1006/23/15257968 ...
随机推荐
- 新建虚拟机,每次都提示无法连接虚拟设备 ide1:0
处理方式:看到了这个老哥http://www.cnblogs.com/dean-du/p/6888513.html的博客,发现问题是一样的,所以记录一下. 将虚拟机设置中的CD/DVD选项中的连接更改 ...
- 一张图看懂 JS 原型链
JS 原型链,画了张图,终于理清楚各种关系有木有 写在最后: __proto__是每个对象都有的一个属性,而prototype是函数才会有的属性!!! function Person() { } 是函 ...
- Redis 集群缓存测试要点--关于 线上 token 失效 BUG 的总结
在测试账户系统过程中遇到了线上大面积用户登录态失效的严重问题,事后对于其原因及测试盲点做了一些总结记录以便以后查阅,总结分为以下7点,其中原理性的解释有些摘自网络. 1.账户系统token失效问题复盘 ...
- 【Oozie】ambari安装oozie失败
之前对azkaban的研究比较多,现在开个新坑,对Oozie开始深入了解 Traceback (most recent call last): File "/var/lib/ambari-a ...
- JMeter中文版用户手册
1.1 简介 使用JMeter通常会有以下步骤: 1.1.1 创建测试计划 首先,运行JMeter图形化界面. 然后在文件菜单中选择Templates…->Recording,通过浏览器录制We ...
- [DP]硬币问题
今天再写一下硬币问题 为什么是再呢 这是个很羞耻的话题 昨天写了一遍硬币 在某谷上跑 没错 挂掉了 TLE MD_SB ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ...
- codeforces 17C Balance(动态规划)
codeforces 17C Balance 题意 给定一个串,字符集{'a', 'b', 'c'},操作是:选定相邻的两个字符,把其中一个变成另一个.可以做0次或者多次,问最后可以生成多少种,使得任 ...
- shell基础之脚本执行,命令别名以及快捷键等
脚本执行方式 比如我们在/root/下编写了一个脚本,名字为hello.sh.那么怎么调用执行它呢?有两种办法: (1)直接通过bash,如下: bash hello.sh 注:采用bash执行脚本 ...
- CNN识别验证码2
获得验证码图片的俩个来源: 1.有网站生成验证码图片的源码 2.通过python的requests下载验证码图片当我们的训练样本 我们通过第一种方式来得到训练样本,下面是生成验证码的php程序: &l ...
- Kali-linux渗透攻击应用
前面依次介绍了Armitage.MSFCONSOLE和MSFCLI接口的概念及使用.本节将介绍使用MSFCONSOLE工具渗透攻击MySQL数据库服务.PostgreSQL数据库服务.Tomcat服务 ...