HFile文件解析异常解决
1. 场景说明
需要对离线的 HFile 进行解析,默认可以使用如下的方式:
hbase org.apache.hadoop.hbase.io.hfile.HFile -f $HDFS_PATH -p -s
这样存在几个问题:
- 需要依赖 hbase 的环境
- -p 选项输出的结果,打印出来的不是 value 的值,里面默认使用的是
Bytes.toBinaryString - 太重了,无关的内容不需要
所以需要对上面的实现方式改造一下。
阅读了源代码之后,了解到 HFile 里面包含的 main 方法初始化了一个 HFilePrettyPrinter 对象,把外部的参数传递给 HFilePrettyPrinter 的对象执行具体的工作。类图如下:
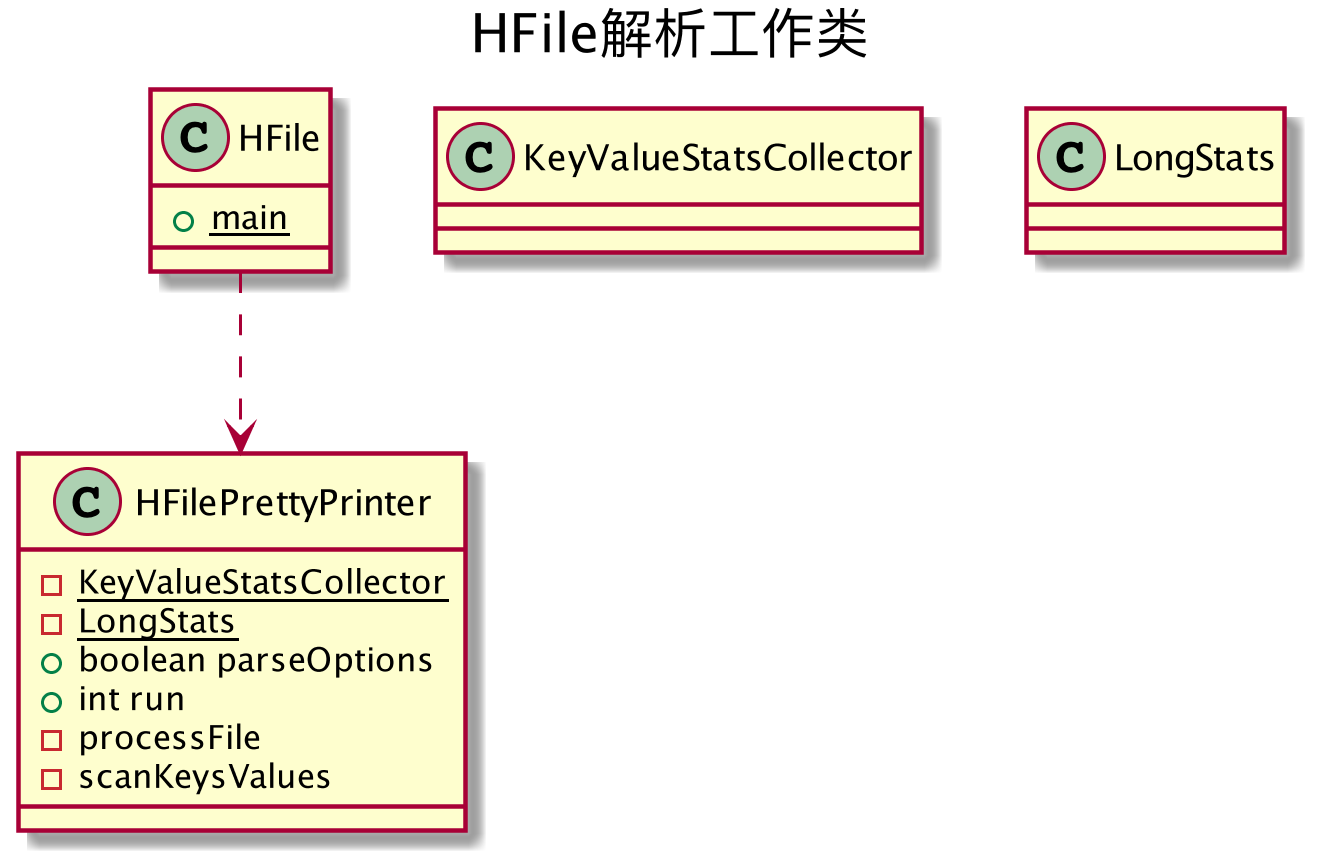
从道理上,只需要把 HFilePrettyPrinter 的代码精简一下,就可以直接拿来用。
开始的时候,为了测试的方便,直接使用 hbase -jar $CLASSNAME args 来做验证,都是 ok 的。
输出的日志如下(后续会通过日志输出比对调试):
INFO hfile.CacheConfig: Allocating LruBlockCache with maximum size 1.4g
INFO blobstore.BlobFileCache: BlobFileCache Initialize
INFO util.ChecksumType: Checksum using org.apache.hadoop.util.PureJavaCrc32
INFO util.ChecksumType: Checksum can use org.apache.hadoop.util.PureJavaCrc32C
WARN hdfs.DFSClient: Short circuit access failed
INFO util.NativeCodeLoader: Trying to load the custom-built native-hadoop library...
INFO util.NativeCodeLoader: Loaded the native-hadoop library
WARN snappy.LoadSnappy: Snappy native library is available
INFO snappy.LoadSnappy: Snappy native library loaded
INFO compress.CodecPool: Got brand-new decompressor
但是一旦脱离了 hbase (/usr/lib/hbase/bin/hbase)这个宿主,直接运行 main 方法,总是报错。
2.异常分析
2.1 CRC32校验类找不到
最开始出现的是如下的错误:
INFO org.apache.hadoop.hbase.io.hfile.CacheConfig - Allocating LruBlockCache with maximum size 1.4g
INFO org.apache.hadoop.hbase.blobstore.BlobFileCache - BlobFileCache Initialize
INFO org.apache.hadoop.hbase.util.ChecksumType - org.apache.hadoop.util.PureJavaCrc32 not available.
INFO org.apache.hadoop.hbase.util.ChecksumType - Checksum can use java.util.zip.CRC32
INFO org.apache.hadoop.hbase.util.ChecksumType - org.apache.hadoop.util.PureJavaCrc32C not available.
INFO org.apache.hadoop.hdfs.DFSClient - Failed to read block blk_-2063727887249910869_1998268 on local machineorg.apache.hadoop.ipc.RPC$VersionMismatch: Protocol org.apache.hadoop.hdfs.protocol.ClientDatanodeProtocol version mismatch. (client = 4, server = 5)
at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:401)
at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:370)
at org.apache.hadoop.hdfs.DFSClient.createClientDatanodeProtocolProxy(DFSClient.java:174)
at org.apache.hadoop.hdfs.BlockReaderLocal$LocalDatanodeInfo.getDatanodeProxy(BlockReaderLocal.java:89)
at org.apache.hadoop.hdfs.BlockReaderLocal$LocalDatanodeInfo.access$200(BlockReaderLocal.java:64)
at org.apache.hadoop.hdfs.BlockReaderLocal.getBlockPathInfo(BlockReaderLocal.java:211)
at org.apache.hadoop.hdfs.BlockReaderLocal.newBlockReader(BlockReaderLocal.java:133)
at org.apache.hadoop.hdfs.DFSClient.getLocalBlockReader(DFSClient.java:358)
关键部分是org.apache.hadoop.util.PureJavaCrc32 not available,这个问题比较明显,是lib 包中缺少必要的类。
为了避免类似的情况,直接用 hbase classpath 把打印出默认的依赖关系,然后把所有的依赖 jar 都加进来。
2.2 文件block 找不到
添加完 jar 包后,重新运行,还是报错,关键点是:
Failed to read block blk_-2063727887249910869_1998268 on local machineorg.apache.hadoop.ipc.RPC$VersionMismatch: Protocol org.apache.hadoop.hdfs.protocol.ClientDatanodeProtocol version mismatch. (client = 4, server = 5)
这里在分析的时候犯了一个错误:首先注意到的是 Failed to read block ... on local machine,而且在日志里面,后面会不断地从本地节点的 datanode 重试,直到超时;且在后面的日志中有 org.apache.hadoop.hdfs.DFSClient.getLocalBlockReader 的信息,莫名其妙地怎么会使用了 LocalBlockReader 呢?
开始就顺着这个思路去搜,找到了HDFS-2757,症状有点像,一看是个老版本的 bug,心说这下操蛋了。
但是显然我只是在读,没有写文件啊?再考虑下,既然使用 hbase 调起的方式可以正常使用,就证明现在的版本是可行的,可能这不是主要问题。
再看后面,Protocol org.apache.hadoop.hdfs.protocol.ClientDatanodeProtocol version mismatch. (client = 4, server = 5),之前没有写过 RPC 的程序,在 Google 上搜索了一下,从这里和这里了解到,这种是典型的 RPC 协议版本不一致的问题。
特别是上面的作者在回复提问的时候,先是确认了 hadoop 的版本,故我转去确认了 lib 库中 hadoop 相关 jar 的版本,结果发现如下:
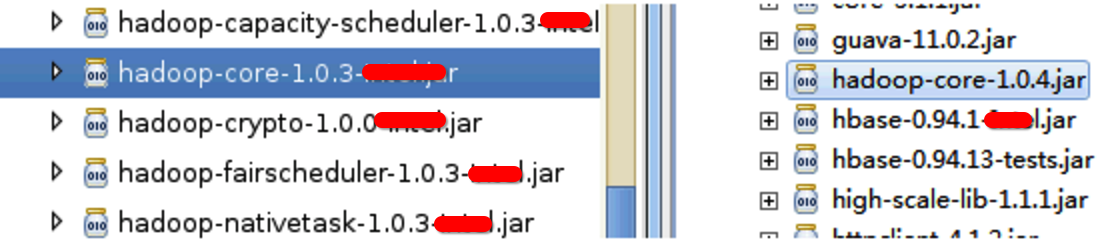
这个确实没招了。。。之前使用不仔细造成的。
于是把 lib 包里面原有的全部清空,然后重新导入 hbase classpath 的输出jar。
2.3 NativeCodeLoader问题
上一步处理完之后,再次运行,还是报错:
INFO org.apache.hadoop.hbase.io.hfile.CacheConfig - Allocating LruBlockCache with maximum size 1.4g
INFO org.apache.hadoop.hbase.blobstore.BlobFileCache - BlobFileCache Initialize
INFO org.apache.hadoop.hbase.util.ChecksumType - Checksum using org.apache.hadoop.util.PureJavaCrc32
INFO org.apache.hadoop.hbase.util.ChecksumType - Checksum can use org.apache.hadoop.util.PureJavaCrc32C
WARN org.apache.hadoop.hdfs.DFSClient - Short circuit access failed
INFO org.apache.hadoop.util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
ERROR org.apache.hadoop.util.NativeCodeLoader - Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
ERROR org.apache.hadoop.util.NativeCodeLoader - java.library.path=/usr/java/jdk1.6.0_31/jre/lib/amd64/server:/usr/java/jdk1.6.0_31/jre/lib/amd64:/usr/java/jdk1.6.0_31/jre/../lib/amd64:/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
ERROR org.apache.hadoop.io.compress.snappy.LoadSnappy - Failed to load snappy with error: java.lang.UnsatisfiedLinkError: no snappy in java.library.path
WARN org.apache.hadoop.io.compress.snappy.LoadSnappy - Snappy native library not loaded
Exception in thread "main" java.lang.RuntimeException: native snappy library not available
at org.apache.hadoop.io.compress.SnappyCodec.getDecompressorType(SnappyCodec.java:189)
at org.apache.hadoop.io.compress.CodecPool.getDecompressor(CodecPool.java:138)
at org.apache.hadoop.hbase.io.hfile.Compression$Algorithm.getDecompressor(Compression.java:290)
关键信息是:
no hadoop in java.library.pathno snappy in java.library.path
这里从新去 /usr/lib/hbase/bin/hbase 文件中查看了下,发现里面有对 $JAVA_PLATFORM 和 $JAVA_LIBRARY_PATH 这两个环境变量的整理。
这里 sudo 修改了 hbase 的执行文件,中间把上面两个环境变量打印出来。第一个 $JAVA_PLATFORM 显示的是 Linux-amd64-64,第二个是/usr/lib/hadoop/lib/native/Linux-amd64-64文件夹的内容。
然后把 $JAVA_LIBRARY_PATH的内容,通过 -Djava.library.path= 的方式,添加到 Eclipse 的 VM Variables 中。
再次运行,正常。
3. 总结
花了一个下午的时间来 DEBUG 这个异常,回过头看,有以下几点需要注意:
- 要认真读日志,通过打印出来的错误堆栈,分清楚哪些是真正错误的源头,哪些是错误扩散的结果。比如花了半天研究 HDFS-2757,后来发现没关系,这个就很没有必要;
- 认识到 hbase、hadoop 这种工具,除了看得到的组件代码之后,看不到额环境配置等内容,也很重要,没有合适的环境配置,正确的代码也是没法正常运行的,需要进一步花一点时间了解组件的运行时环境的配置需求;
- 排错是个厚积薄发的事情,遇到大小问题都要好好思考,多看源代码,解决起来才会有思路。
参考
HFile文件解析异常解决的更多相关文章
- logstash 使用glusterfs网络存储偶发性文件解析异常的问题
其实问题到现在为止也没有解决 因为服务是部署在k8s上,挂载的,偶发性的出现文件解析异常 bom头已经验证过了 手动重新解析这些文件完全正常,问题无法复现,文件本身并没有问题. 最后怀疑到了最不该怀疑 ...
- vs2015 系统找不到指定的文件(异常来自HRESULT:0x80070002)问题的解决方法
vs2015 创建mvc项目时,弹出错误信息内容(系统找不到指定的文件(异常来自HRESULT:0x80070002)) 弹出窗体如下图所示: 导致整个原因是:未安装NuGet包 解决方法: 1)打开 ...
- android基础知识13:AndroidManifest.xml文件解析
注:本文转载于:http://blog.csdn.net/xianming01/article/details/7526987 AndroidManifest.xml文件解析. 1.重要性 Andro ...
- dubbo注册服务IP解析异常及IP解析源码分析
在使用dubbo注册服务时会遇到IP解析错误导致无法正常访问. 比如: 本机设置的IP为172.16.11.111, 但实际解析出来的是180.20.174.11 这样就导致这个Service永远也无 ...
- MyBatis 源码分析 - 映射文件解析过程
1.简介 在上一篇文章中,我详细分析了 MyBatis 配置文件的解析过程.由于上一篇文章的篇幅比较大,加之映射文件解析过程也比较复杂的原因.所以我将映射文件解析过程的分析内容从上一篇文章中抽取出来, ...
- servlet上传多个文件(乱码解决)
首先,建议将编码设置为GB2312,并在WEB-INF\lib里导入:commons-fileupload-1.3.jar和commons-io-2.4.jar, 可百度下下载,然后你编码完成后,上传 ...
- 使用HttpClient MultipartEntityBuilder 上传文件,并解决中文文件名乱码问题
遇到一种业务场景,前端上传的文件需要经过java服务转发至文件服务.期间遇到了原生HttpClient怎么使用的问题.怎么把MultipartFile怎么重新组装成Http请求发送出去的问题.文件中文 ...
- C#_.net core 3.0自定义读取.csv文件数据_解决首行不是标题的问题_Linqtocsv改进
linqtocsv文件有不太好的地方就是:无法设置标题的行数,默认首行就是标题,这不是很尴尬吗? 并不是所有的csv文件严格写的首行是标题,下面全是数据,我接受的任务就是读取很多.csv报表数据, ...
- MyBatis版本升级导致OffsetDateTime入参解析异常问题复盘
背景 最近有一个数据统计服务需要升级SpringBoot的版本,由1.5.x.RELEASE直接升级到2.3.0.RELEASE,考虑到没有用到SpringBoot的内建SPI,升级过程算是顺利.但是 ...
随机推荐
- PHP MVC自己主动RBAC自己主动生成的访问路由
使用的关键点: ReflectionClass class Rbac extends MY_Controller { public function index() { $arr = glob( __ ...
- 至Android虚拟机发送短信和拨打电话
Android的emulator是已经包括了gsm 模块,能够模拟电话与短信进行调试(就不用花太多冤枉钱) 首先,肯定是打开虚拟机: emulator -avd XXXXXX -scale 0.8&a ...
- linux 3.4.103 内核移植到 S3C6410 开发板 移植失败 (问题总结,日本再战!)
linux 3.4.103 内核移植到 S3C6410 开发板 这个星期差点儿就搭在这里面了,一開始感觉非常不值得,移植这样的浪费时间的事情.想立刻搞定,然后安安静静看书 & coding. ...
- Java数据结构系列——简单排序:泡、选择、直接进入
package SimpleSort; public class SimpleSort { /** * 冒泡排序:每次循环过程中.小的排在后面的数会像水中的 * 气泡一样慢慢往上冒,所以命名为冒泡排序 ...
- HDU 4932 Miaomiao's Geometry(推理)
HDU 4932 Miaomiao's Geometry pid=4932" target="_blank" style="">题目链接 题意: ...
- Swift游戏开发实战教程(霸内部信息大学)
Swift游戏开发实战教程(大学霸内部资料) 试读下载地址:http://pan.baidu.com/s/1sj7DvQH 介绍:本教程是国内第一本Swift游戏开发专向资料. 本教程具体解说记忆配对 ...
- Dom中的nodeName、nodeValue 、nodeType
nodeName.nodeValue 以及 nodeType 包含有关于节点的信息. nodeName 属性含有某个节点的名称. 元素节点的 nodeName 是标签名称 属性节点的 nodeName ...
- C#将Excel数据导入数据库(MySQL或Sql Server)
最近一直很忙,很久没写博客了.今天给大家讲解一下如何用C#将Excel数据导入Excel,同时在文章最后附上如何用sqlserver和mysql工具导入数据. 导入过程大致分为两步: 1.将excel ...
- CSS3火焰文字特效制作教程
原文:CSS3火焰文字特效制作教程 用一句很俗气的话概括这两天的情况就是:“最近很忙”,虽然手头上有不少很酷的HTML5和CSS3资源,但确实没时间将它们的实现过程写成教程分享给大家.今天刚完成了一个 ...
- Utility Classes Are Evil
原文地址:http://alphawang.com/blog/2014/09/utility-classes-are-evil/ This post is a summary of this arti ...