爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛
本着 “用技术改变生活” 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序
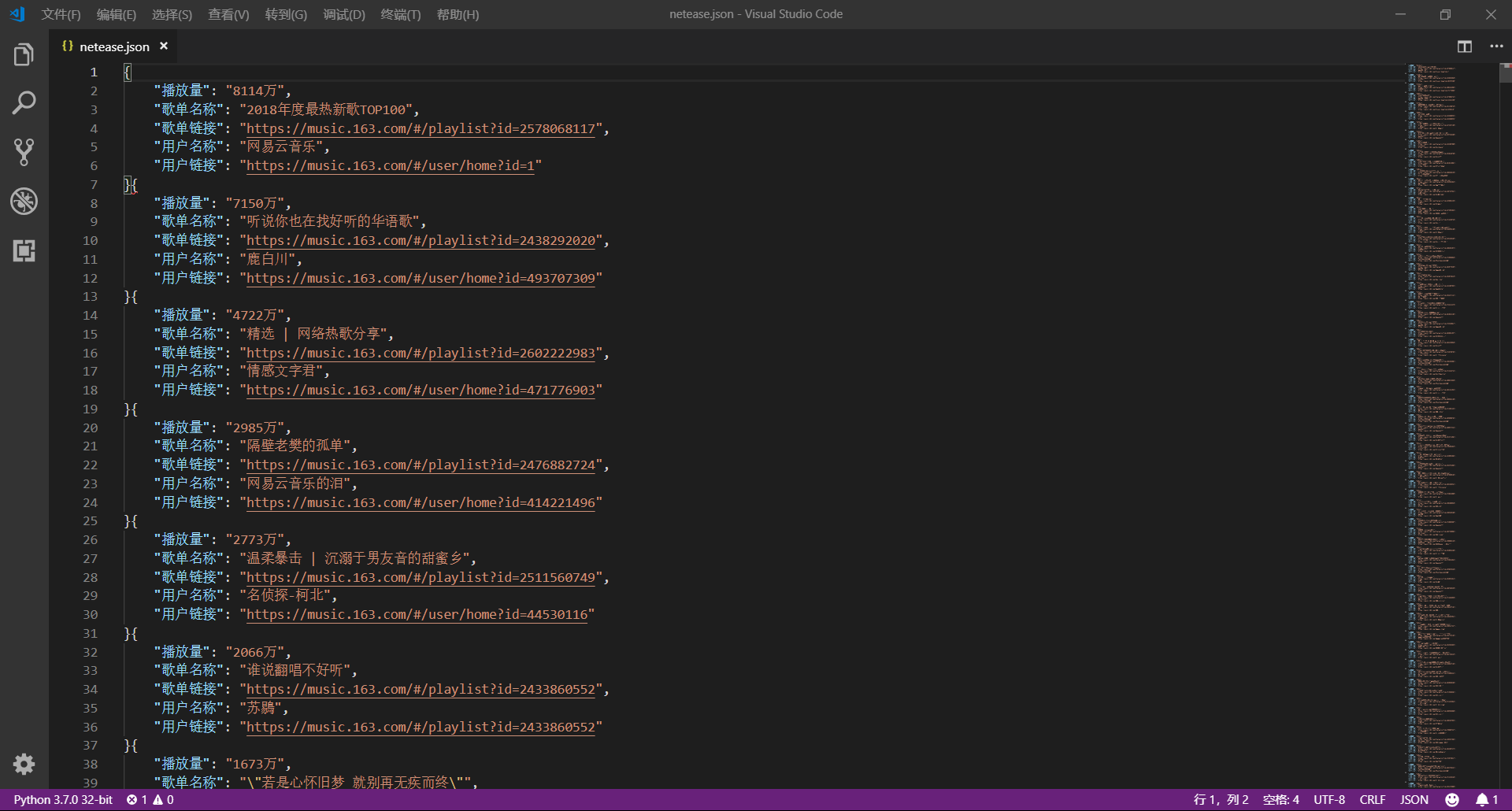
这篇文章,我们就来讲讲怎样爬取网易云歌单,并将歌单按播放量进行排序,下面先上效果图
1、用 requests 爬取网易云歌单
打开 网易云音乐 歌单首页,不难发现这是一个静态网页,而且格式很有规律,爬取起来应该十分简单
按照以前的套路,很快就可以写完代码,无非就是分为下面几个部分:
(1)获取网页源代码
这里我们使用 requests 发送和接收请求,核心代码如下:
import requests
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求,获得响应
response = requests.get(url=url,headers=headers)
# 获取响应内容
html = response.text
return html
(2)解析网页源代码
解析数据部分我们使用 xpath(对于 xpath 的语法不太熟悉的朋友,可以看看博主之前的文章)
文章传送门:
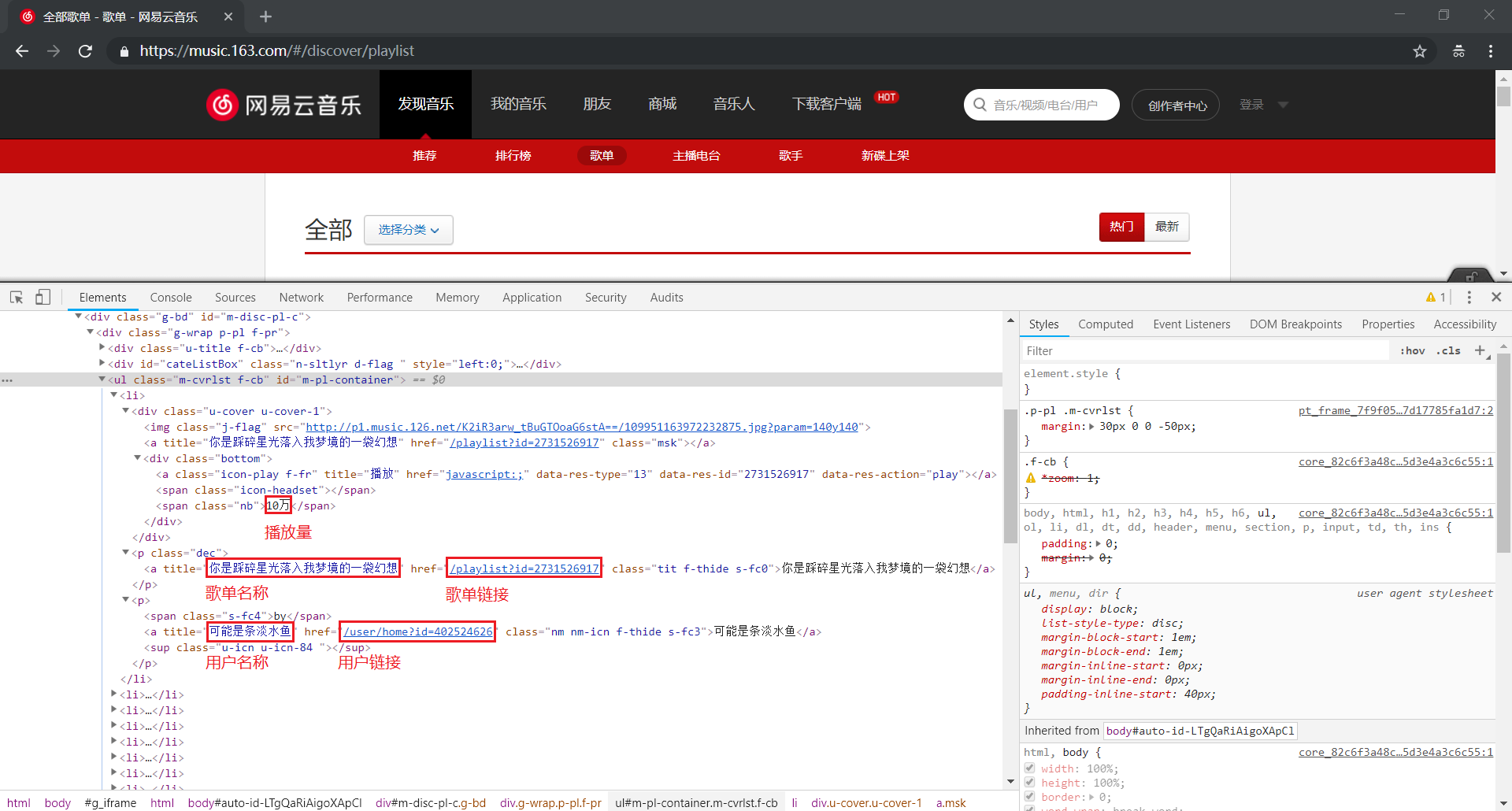
核心代码如下:
from lxml import etree
# 解析网页源代码,获取数据
def parse4data(self,html):
html_elem = etree.HTML(html)
# 播放量
play_num = html_elem.xpath('//ul[@id="m-pl-container"]/li/div/div/span[@class="nb"]/text()')
# 歌单名称
song_title = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[1]/a/@title')
# 歌单链接
song_href = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[1]/a/@href')
song_link = ['https://music.163.com/#'+item for item in song_href]
# 用户名称
user_title = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[2]/a/@title')
# 用户链接
user_href = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[2]/a/@href')
user_link = ['https://music.163.com/#'+item for item in user_href]
# 将数据打包成列表,其中列表中的每一个元素是一个字典,每一个字典对应一份歌单信息
data = list(map(lambda a,b,c,d,e:{'播放量':a,'歌单名称':b,'歌单链接':c,'用户名称':d,'用户链接':e},play_num,song_title,song_link,user_title,user_link))
# 返回数据
return data
# 解析网页源代码,获取下一页链接
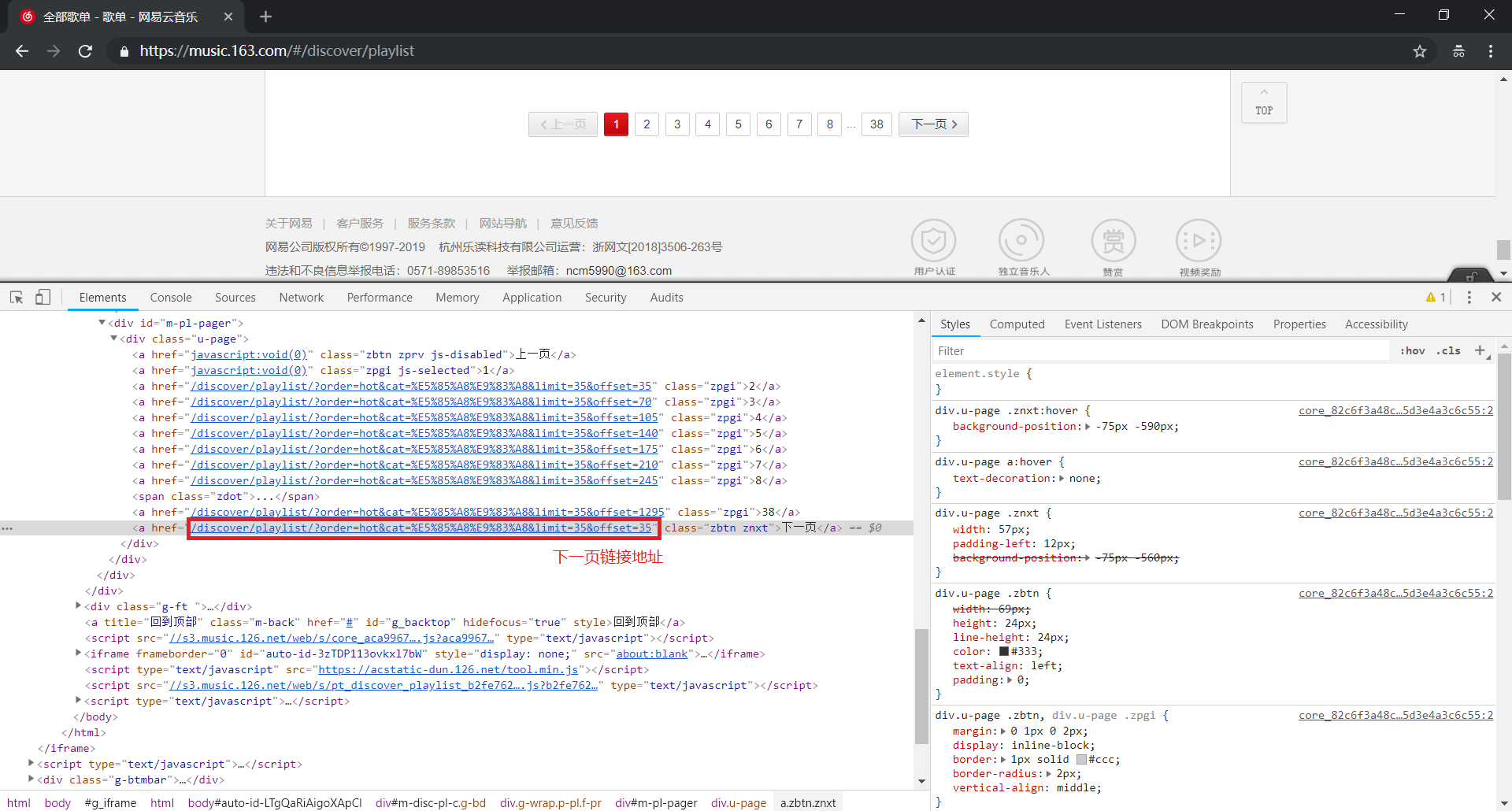
def parse4link(self,html):
html_elem = etree.HTML(html)
# 下一页链接
href = html_elem.xpath('//div[@id="m-pl-pager"]/div[@class="u-page"]/a[@class="zbtn znxt"]/@href')
# 如果为空,则返回 None;如果不为空,则返回链接地址
if not href:
return None
else:
return 'https://music.163.com/#' + href[0]
(3)完整代码
import requests
from lxml import etree
import json
import time
import random
class Netease_spider:
# 初始化数据
def __init__(self):
self.originURL = 'https://music.163.com/#/discover/playlist'
self.data = list()
# 获取网页源代码
def get_page(self,url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
html = response.text
return html
# 解析网页源代码,获取数据
def parse4data(self,html):
html_elem = etree.HTML(html)
play_num = html_elem.xpath('//ul[@id="m-pl-container"]/li/div/div/span[@class="nb"]/text()')
song_title = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[1]/a/@title')
song_href = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[1]/a/@href')
song_link = ['https://music.163.com/#'+item for item in song_href]
user_title = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[2]/a/@title')
user_href = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[2]/a/@href')
user_link = ['https://music.163.com/#'+item for item in user_href]
data = list(map(lambda a,b,c,d,e:{'播放量':a,'歌单名称':b,'歌单链接':c,'用户名称':d,'用户链接':e},play_num,song_title,song_link,user_title,user_link))
return data
# 解析网页源代码,获取下一页链接
def parse4link(self,html):
html_elem = etree.HTML(html)
href = html_elem.xpath('//div[@id="m-pl-pager"]/div[@class="u-page"]/a[@class="zbtn znxt"]/@href')
if not href:
return None
else:
return 'https://music.163.com/#' + href[0]
# 开始爬取网页
def crawl(self):
# 爬取数据
print('爬取数据')
html = self.get_page(self.originURL)
data = self.parse4data(html)
self.data.extend(data)
link = self.parse4link(html)
while(link):
html = self.get_page(link)
data = self.parse4data(html)
self.data.extend(data)
link = self.parse4link(html)
time.sleep(random.random())
# 处理数据,按播放量进行排序
print('处理数据')
data_after_sort = sorted(self.data,key=lambda item:int(item['播放量'].replace('万','0000')),reverse=True)
# 写入文件
print('写入文件')
with open('netease.json','w',encoding='utf-8') as f:
for item in data_after_sort:
json.dump(item,f,ensure_ascii=False)
if __name__ == '__main__':
spider = Netease_spider()
spider.crawl()
print('Finished')
2、用 selenium 爬取网易云歌单
然而,事情真的有这么简单吗?
当我们运行上面的代码的时候,会发现解析网页源代码部分,返回的竟然是空列表!
这是为什么呢?敲重点,敲重点,敲重点,这绝对是一个坑啊!
我们重新打开浏览器,认真观察网页的源代码
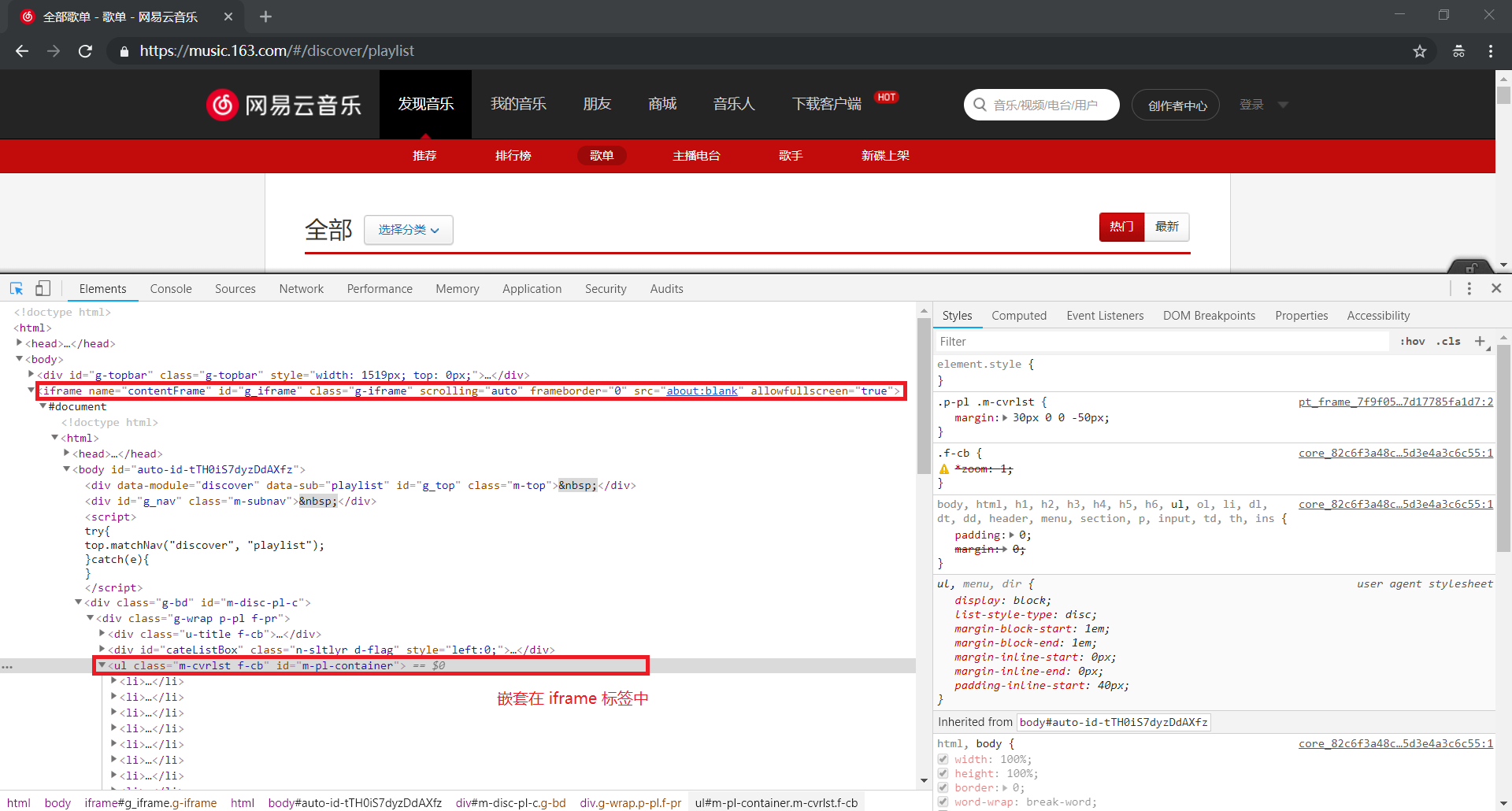
原来,我们所提取的元素被包含在 <iframe> 标签内部,这样我们是无法直接进行定位的
因为 iframe 会在原有页面中加载另外一个页面,当我们需要获取内嵌页面的元素时,需要先切换到 iframe 中
明白了原理之后,重新修改一下上面的代码
思路是利用 selenium 获取原有网页,然后使用 switch_to.frame() 方法切换到 iframe 中,最后返回内嵌网页
对 selenium 的使用以及环境配置不清楚的朋友,可以参考博主之前的文章
需要修改的地方是获取网页源代码的函数,另外也需要在初始化数据的函数中实例化 webdriver,完整代码如下:
from selenium import webdriver
from lxml import etree
import json
import time
import random
class Netease_spider:
# 初始化数据(需要修改)
def __init__(self):
# 无头启动 selenium
opt = webdriver.chrome.options.Options()
opt.set_headless()
self.browser = webdriver.Chrome(chrome_options=opt)
self.originURL = 'https://music.163.com/#/discover/playlist'
self.data = list()
# 获取网页源代码(需要修改)
def get_page(self,url):
self.browser.get(url)
self.browser.switch_to.frame('g_iframe')
html = self.browser.page_source
return html
# 解析网页源代码,获取数据
def parse4data(self,html):
html_elem = etree.HTML(html)
play_num = html_elem.xpath('//ul[@id="m-pl-container"]/li/div/div/span[@class="nb"]/text()')
song_title = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[1]/a/@title')
song_href = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[1]/a/@href')
song_link = ['https://music.163.com/#'+item for item in song_href]
user_title = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[2]/a/@title')
user_href = html_elem.xpath('//ul[@id="m-pl-container"]/li/p[2]/a/@href')
user_link = ['https://music.163.com/#'+item for item in user_href]
data = list(map(lambda a,b,c,d,e:{'播放量':a,'歌单名称':b,'歌单链接':c,'用户名称':d,'用户链接':e},play_num,song_title,song_link,user_title,user_link))
return data
# 解析网页源代码,获取下一页链接
def parse4link(self,html):
html_elem = etree.HTML(html)
href = html_elem.xpath('//div[@id="m-pl-pager"]/div[@class="u-page"]/a[@class="zbtn znxt"]/@href')
if not href:
return None
else:
return 'https://music.163.com/#' + href[0]
# 开始爬取网页
def crawl(self):
# 爬取数据
print('爬取数据')
html = self.get_page(self.originURL)
data = self.parse4data(html)
self.data.extend(data)
link = self.parse4link(html)
while(link):
html = self.get_page(link)
data = self.parse4data(html)
self.data.extend(data)
link = self.parse4link(html)
time.sleep(random.random())
# 处理数据,按播放量进行排序
print('处理数据')
data_after_sort = sorted(self.data,key=lambda item:int(item['播放量'].replace('万','0000')),reverse=True)
# 写入文件
print('写入文件')
with open('netease.json','w',encoding='utf-8') as f:
for item in data_after_sort:
json.dump(item,f,ensure_ascii=False)
if __name__ == '__main__':
spider = Netease_spider()
spider.crawl()
print('Finished')
这样,得到目前网易云音乐中播放量排名前十的歌单如下(哈哈,又可以愉快的听歌啦):
- 2018年度最热新歌TOP100
- 听说你也在找好听的华语歌
- 精选 | 网络热歌分享
- 隔壁老樊的孤单
- 温柔暴击 | 沉溺于男友音的甜蜜乡
- 谁说翻唱不好听
- 若是心怀旧梦 就别再无疾而终
- KTV必点:有没有一首歌,唱着唱着就泪奔
- 化妆拍照BGM.
- 会讲故事的男声 歌词唱的太像自己
注意:本项目代码仅作学习交流使用!!!
爬虫实战(二) 用Python爬取网易云歌单的更多相关文章
- Python爬取网易云歌单
目录 1. 关键点 2. 效果图 3. 源代码 1. 关键点 使用单线程爬取,未登录,爬取网易云歌单主要有三个关键点: url为https://music.163.com/discover/playl ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- Python 爬取网易云歌手的50首热门作品
使用 requests 爬取网易云音乐 Python 代码: import json import os import time from bs4 import BeautifulSoup impor ...
- python爬取网易云音乐歌单音乐
在网易云音乐中第一页歌单的url:http://music.163.com/#/discover/playlist/ 依次第二页:http://music.163.com/#/discover/pla ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- 爬虫实战(三) 用Python爬取拉勾网
目录 0.前言 1.初始化 2.爬取数据 3.保存数据 4.数据可视化 5.大功告成 0.前言 最近,博主面临着选方向的困难(唉,选择困难症患者 >﹏<),所以希望了解一下目前不同岗位的就 ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
随机推荐
- 【Dairy】2016.10.24 - made 嘲讽垃圾
//这个还找不到我的博客,但在看到原文 //这个还找不到我的博客,但在看到原文 //这个还找不到我的博客,但在看到原文 //这个还在我前面,访问多 一波嘲讽,woc 今天百度一下文章,发现有一篇和我一 ...
- 5 Application 对象
5.1鸟瞰Application对象 5.2 必须了解的面向显示特性 5.2.1 使用ScreenUpdating改进和完善执行性能 代码清单5.1:实现屏幕更新的性能 '代码清单5.1: 实现屏幕更 ...
- python-----删除文件到回收站
python删除文件一般使用os.remove,但这样删是直接删除文件,不删到回收站的,那么想删除文件到回收站怎么办? 这时,就需要使用shell模块了 from win32com.shell imp ...
- [置顶][终极精简版][图解]Nginx搭建flv mp4流媒体服务器
花了我接近3周,历经了重重问题,今日终于把流媒体服务器搞定,赶紧的写个博文以免忘记... 起初是跟着网上的一些教程来的,但是说的很不全面,一些东西也过时不用了(比如jwplayer老版本).我这次是用 ...
- 【Learning】多项式的一些东西
FFT 坑 NTT 将\(FFT\)中的单位复数根改成原根即可. 卡常版NTT模版 struct Mul { int Len; int wn[N], Lim; int rev[N]; inline v ...
- (博弈论)51NOD 1072 威佐夫游戏
有2堆石子.A B两个人轮流拿,A先拿.每次可以从一堆中取任意个或从2堆中取相同数量的石子,但不可不取.拿到最后1颗石子的人获胜.假设A B都非常聪明,拿石子的过程中不会出现失误.给出2堆石子的数量, ...
- 计算几何值平面扫面poj2932 Coneology
Coneology Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 4097 Accepted: 859 Descript ...
- NHibernate学习笔记(3)-实体反射到数据库
一.开发环境 NHiberate版本:4.0.4 开发工具:VS2013 数据库:SQLServer2012 二.开发流程 1.编写领域类与映射文件 namespace Domain { public ...
- MySQL的主从复制(windows)
在我们实际的开发中,当系统业务到达一定的程度,可能数据库会到达一定的瓶颈,但实际开发中最容易到达数据库瓶颈的应该是数据库的读性能,一般的业务大多都是读多写少,我们可以通过提高读的性能来提高数据库的整体 ...
- 如何向expect脚本里面传递参数
如何向expect脚本里面传递参数 比如下面脚本用来做ssh无密码登陆,自动输入确认yes和密码信息,用户名,密码,hostname通过参数来传递 ssh.exp Python代码 # ...