Akka源码分析-Cluster-Distributed Publish Subscribe in Cluster
在ClusterClient源码分析中,我们知道,他是依托于“Distributed Publish Subscribe in Cluster”来实现消息的转发的,那本文就来分析一下Pub/Sub是如何实现的。
还记得之前分析Cluster源码的文章吗?其实Cluster只是把集群内各个节点的信息通过gossip协议公布出来,并把节点的信息分发出来。但各个actor的地址还是需要开发者自行获取或设计的,比如我要跟worker通信,那就需要知道这个actor在哪个节点,通过actorPath或actorRef通信。
“Distributed Publish Subscribe”就是用来屏蔽Actor位置的一个组件,通过它你可以给actor发消息而不需要知道actor的网咯位置。其实就是提供了一个类似kafka的消息发布、订阅的机制,其实吧,如果这个功能让你实现,你准备怎么做?肯定是在集群层面提供一个proxy,来屏蔽目标actor的网络位置啊。简单来说,就是提供一个通用的actor,来对消息进行转发,发送者只需要提供目标actor的路径就好了(比如/user/serviceA)。不过还是那句话,akka的都是对的,akka的都是好的。akka帮你实现这个事儿,就不用你自己考虑通用、稳定的问题啦。
消息订阅发布模式提供了一个中继actor:akka.cluster.pubsub.DistributedPubSubMediator。它管理actor的注册引用、分发实例引用给端actor,而且必须在所有的节点或一组节点内启动。它可以通过DistributedPubSub扩展启动,也可以像普通actor那样启动。
服务actor的注册是最终一致的,也就是说服务信息在变化时并不能立即通知给其他节点,过一段时间参会分发给所有节点。当然了每次都是以增量的信息分发这些信息。
消息的发送有两种模式:Send和Publish。简单来说就是点对点、广播。
Publish模式下,只有注册到命名的topic的actor才会收到消息,topic是啥?。其实这才是真正的订阅、发布模式。
class Subscriber extends Actor with ActorLogging {
import DistributedPubSubMediator.{ Subscribe, SubscribeAck }
val mediator = DistributedPubSub(context.system).mediator
// subscribe to the topic named "content"
mediator ! Subscribe("content", self)
def receive = {
case s: String ⇒
log.info("Got {}", s)
case SubscribeAck(Subscribe("content", None, `self`)) ⇒
log.info("subscribing")
}
}
class Publisher extends Actor {
import DistributedPubSubMediator.Publish
// activate the extension
val mediator = DistributedPubSub(context.system).mediator
def receive = {
case in: String ⇒
val out = in.toUpperCase
mediator ! Publish("content", out)
}
}
上面是官方的demo,可以看出,订阅者actor订阅了名为“content”的topic,在发布者actor发送指定topic的消息时,会自动收到对应的消息。怎么样,是不是很简单。其实吧,mediator只需要维护一个topic到订阅者的映射列表就好了,当收到对应topic的消息时,取出对应的订阅者(也就是ActorRef或actorSelection)把消息转发给他就好了。
Send模式就是一个点对点模式,每个消息被发送给一个目标,而不用知道这个目标actors的位置。既然之前我们说了,这是通过ActorPath发送的,那如果集群中同时有多个节点命中了这个ActorPath怎么办呢?那就路由呗,提供一个RoutingLogic 路由策略。默认策略是随机发送,当然了我们是可以修改这个策略的。与Publish模式不同,这里注册服务actor是通过Put消息实现的。不过实现原理都差不多,反正都要维护列表。
class Destination extends Actor with ActorLogging {
import DistributedPubSubMediator.Put
val mediator = DistributedPubSub(context.system).mediator
// register to the path
mediator ! Put(self)
def receive = {
case s: String ⇒
log.info("Got {}", s)
}
}
class Sender extends Actor {
import DistributedPubSubMediator.Send
// activate the extension
val mediator = DistributedPubSub(context.system).mediator
def receive = {
case in: String ⇒
val out = in.toUpperCase
mediator ! Send(path = "/user/destination", msg = out, localAffinity = true)
}
}
当然了,我们还是可以通过SendToAll把消息发送给所有命中指定path的actor的。
这里需要注意的是,官方的订阅发布组件只能保证至少一次投递,想想都是这样的,哈哈。废话不多说了,上代码。
object DistributedPubSub extends ExtensionId[DistributedPubSub] with ExtensionIdProvider {
override def get(system: ActorSystem): DistributedPubSub = super.get(system)
override def lookup = DistributedPubSub
override def createExtension(system: ExtendedActorSystem): DistributedPubSub =
new DistributedPubSub(system)
}
很显然DistributedPubSub这个扩展也是可以通过配置直接实例化的,不需要我们自行写代码实例化。由于其源码非常简单就是定义并创建了mediator这个actor(DistributedPubSubMediator),下面直接转到DistributedPubSubMediator源码的分析。
/**
* This actor manages a registry of actor references and replicates
* the entries to peer actors among all cluster nodes or a group of nodes
* tagged with a specific role.
*
* The `DistributedPubSubMediator` actor is supposed to be started on all nodes,
* or all nodes with specified role, in the cluster. The mediator can be
* started with the [[DistributedPubSub]] extension or as an ordinary actor.
*
* Changes are only performed in the own part of the registry and those changes
* are versioned. Deltas are disseminated in a scalable way to other nodes with
* a gossip protocol. The registry is eventually consistent, i.e. changes are not
* immediately visible at other nodes, but typically they will be fully replicated
* to all other nodes after a few seconds.
*
* You can send messages via the mediator on any node to registered actors on
* any other node. There is three modes of message delivery.
*
* You register actors to the local mediator with [[DistributedPubSubMediator.Put]] or
* [[DistributedPubSubMediator.Subscribe]]. `Put` is used together with `Send` and
* `SendToAll` message delivery modes. The `ActorRef` in `Put` must belong to the same
* local actor system as the mediator. `Subscribe` is used together with `Publish`.
* Actors are automatically removed from the registry when they are terminated, or you
* can explicitly remove entries with [[DistributedPubSubMediator.Remove]] or
* [[DistributedPubSubMediator.Unsubscribe]].
*
* Successful `Subscribe` and `Unsubscribe` is acknowledged with
* [[DistributedPubSubMediator.SubscribeAck]] and [[DistributedPubSubMediator.UnsubscribeAck]]
* replies.
*
* Not intended for subclassing by user code.
*/
@DoNotInherit
class DistributedPubSubMediator(settings: DistributedPubSubSettings) extends Actor with ActorLogging with PerGroupingBuffer
PerGroupingBuffer这个trait不再分析源码,从代码和命名来看,就是给每个group提供一个消息缓存的列表。其实这个actor最重要的功能是要能够感知集群节点的变化和对应服务actor的变化,并及时的把这些信息分发给其他DistributedPubSubMediator,还有就是能够把消息路由给指定的订阅者。为了简化分析,我们忽略第一个功能点,只分析是如何路由消息的。分析这点需要关注几个消息的处理逻辑:Put、Subscribe、Publish、Send、SendToAll。
先来看Subscribe 。
case msg @ Subscribe(topic, _, _) ⇒
// each topic is managed by a child actor with the same name as the topic val encTopic = encName(topic) bufferOr(mkKey(self.path / encTopic), msg, sender()) {
context.child(encTopic) match {
case Some(t) ⇒ t forward msg
case None ⇒ newTopicActor(encTopic) forward msg
}
}
Subscribe消息表明某个actor需要订阅某个topic的消息,简单来说就是先判断是否需要缓存,不需要的话就执行{}代码块。很显然,刚开始的时候是不需要缓存的。上面的逻辑就是从当前的children中查找encTopic的一个actor,然后把消息转发给它;不存在则创建之后再转发给它。那猜一下这个子actor的功能?其实吧,它应该是一个actor负责维护某个topic与所有订阅者的关系,所有发给这个topic的消息都会转发给所有的订阅者。
def newTopicActor(encTopic: String): ActorRef = {
val t = context.actorOf(Props(classOf[Topic], removedTimeToLive, routingLogic), name = encTopic)
registerTopic(t)
t
}
很显然newTopicActor创建了Topic这个actor,名字就是topic的值,并传入了两个参数:removedTimeToLive、routingLogic。第二个是路由策略。
def registerTopic(ref: ActorRef): Unit = {
put(mkKey(ref), Some(ref))
context.watch(ref)
}
put这个函数的功能我们先略过,其功能大概是把这个actor注册到系统内,把它与当前地址、版本号做关联并保存,在适当的时机分发出去。
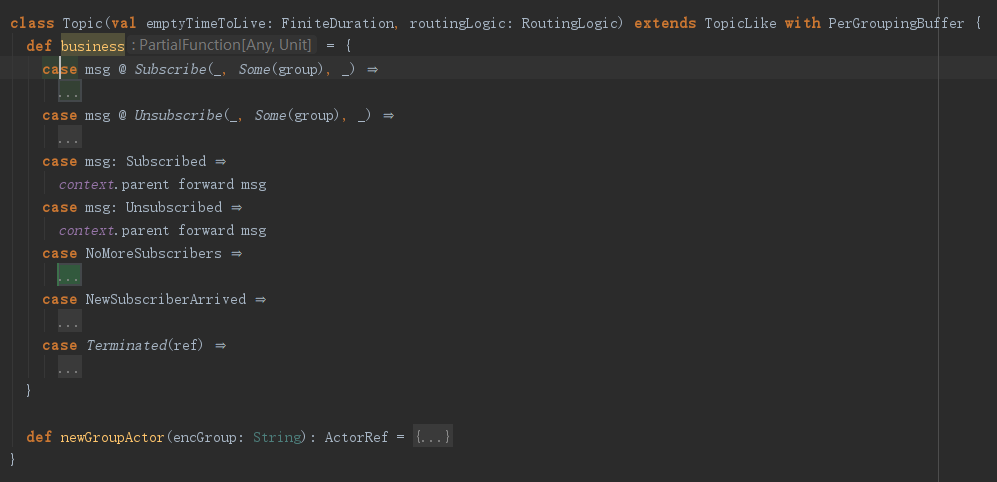
Topic这个actor只有两个方法,所以还需要去看下TopicLike的代码。
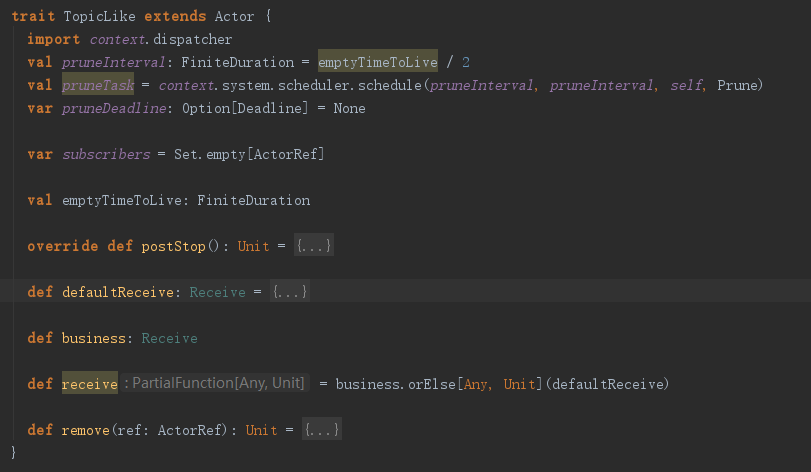
可以看到TopicLike中有一个subscribers列表,这也是预期之中的。这个actor的消息会被business和defaultReceive处理,business在Topic中重新实现了,且会优先处理。
case msg @ Subscribe(_, Some(group), _) ⇒
val encGroup = encName(group)
bufferOr(mkKey(self.path / encGroup), msg, sender()) {
context.child(encGroup) match {
case Some(g) ⇒ g forward msg
case None ⇒ newGroupActor(encGroup) forward msg
}
}
pruneDeadline = None
收到Subscribe消息后,做了跟DistributedPubSubMediator类似的逻辑,又创建了一个子actor(Group),并把消息转发给了它。其实这一点在官方也有说过,也就是说,topic也是可以分组的,一个消息并不一定会发给所有订阅者,可以发给一组订阅者,其实吧,这一点我不太喜欢,感觉功能有点过了,如果要对topic划分子topic,用户自定义实现好了啊,搞得现在源码这么复杂。
class Group(val emptyTimeToLive: FiniteDuration, routingLogic: RoutingLogic) extends TopicLike {
def business = {
case SendToOneSubscriber(msg) ⇒
if (subscribers.nonEmpty)
Router(routingLogic, (subscribers map ActorRefRoutee).toVector).route(wrapIfNeeded(msg), sender())
}
}
Group的代码还这么简单,它又把Subscribe发给了TopicLike的defaultReceive
def defaultReceive: Receive = {
case msg @ Subscribe(_, _, ref) ⇒
context watch ref
subscribers += ref
pruneDeadline = None
context.parent ! Subscribed(SubscribeAck(msg), sender())
上面是defaultReceive对Subscribe消息的处理,就是watch,然后把订阅者添加到subscribers列表中,再告诉父actor(就是Topic这个actor)订阅成功了。
聪明的读者可能会问了,为啥topic还需要弄个消息缓存呢?其实吧,如果是我实现,肯定不搞这么麻烦啊。消息丢了就丢了啊,没有订阅者的时候,消息缓存起来等有订阅者的时候再发送出去?哈哈,有点浪费内存啊。不过为了稳定性、功能性、完善性,akka还是做了很多额外努力的。不过吧,建议还是把这个队列的大小调小一点,要不然太浪费内存了。不过很不幸的告诉你,目前没有这个开关。
既然订阅topic的逻辑跟我们的猜测差不多,那么发布消息的逻辑就应该也符合我们的猜测喽。其实就是获取某个topic对应的订阅者,然后foreach把消息发出去。
case Publish(topic, msg, sendOneMessageToEachGroup) ⇒
if (sendOneMessageToEachGroup)
publishToEachGroup(mkKey(self.path / encName(topic)), msg)
else
publish(mkKey(self.path / encName(topic)), msg)
简单起见,我们只分析消息不分组的情况
def publish(path: String, msg: Any, allButSelf: Boolean = false): Unit = {
val refs = for {
(address, bucket) ← registry
if !(allButSelf && address == selfAddress) // if we should skip sender() node and current address == self address => skip
valueHolder ← bucket.content.get(path)
ref ← valueHolder.ref
} yield ref
if (refs.isEmpty) ignoreOrSendToDeadLetters(msg)
else refs.foreach(_.forward(msg))
}
还记得registry什么时候赋值的嘛?如果忘了,可以翻翻registerTopic的代码,因为我没有分析,哈哈。不过不重要了,其实就是获取当前的Topic的Group的ActorRef,然后把消息转发给它。
case msg ⇒
subscribers foreach { _ forward msg }
Group继承的TopicLike中的defaultReceive方法处理了消息,其实就是把消息转发给所有的subscribers。
pub/sub的逻辑就分析到这里了,其实这里面的逻辑还是有点复杂的,当然了有一部分是因为topic分组带来的,其他的都是gossip协议分发订阅者、发布者的相关信息带来的。
下面分析Send模式。从Put消息的处理入手。
case Put(ref: ActorRef) ⇒
if (ref.path.address.hasGlobalScope)
log.warning("Registered actor must be local: [{}]", ref)
else {
put(mkKey(ref), Some(ref))
context.watch(ref)
}
这就有点简单了,就是把ref注册一下,然后watch。这个ref的key是ActorRef值,其实就是ActorPath.toString
case Send(path, msg, localAffinity) ⇒
val routees = registry(selfAddress).content.get(path) match {
case Some(valueHolder) if localAffinity ⇒
(for {
routee ← valueHolder.routee
} yield routee).toVector
case _ ⇒
(for {
(_, bucket) ← registry
valueHolder ← bucket.content.get(path)
routee ← valueHolder.routee
} yield routee).toVector
} if (routees.isEmpty) ignoreOrSendToDeadLetters(msg)
else Router(routingLogic, routees).route(wrapIfNeeded(msg), sender())
其实就是从registry中优先找当前节点的订阅者,然后通过Router和指定的策略把消息发送出去,这个比pub/sub模式稍微简单点。wrapIfNeeded的功能不再分析,其实就是为了防止与用户本身的路由消息发生冲突。
关于节点信息同步,感兴趣的读者可以自行阅读源码,不过我看下来还是有几个问题的。比如当前注册信息的版本是通过时间戳来标志的,如果节点间时间不同步,会发生意外的结果啊;另外所谓的gossip协议,其实就是随机把注册信息发送给其他节点,也就是说集群内的节点都会把消息按照心跳时间,把注册信息随机发送给本身节点以外的节点,达到最终注册信息的同步。如果是我来实现,直接就是粗暴的广播注册信息,哈哈,不过这在集群规模比较大的时候比较耗时,啊哈哈。
Akka源码分析-Cluster-Distributed Publish Subscribe in Cluster的更多相关文章
- AKKA 集群中的发布与订阅Distributed Publish Subscribe in Cluster
Distributed Publish Subscribe in Cluster 基本定义 在单机环境下订阅与发布是很常用的,然而在集群环境是比较麻烦和不好实现的: AKKA已经提供了相应的实现,集群 ...
- Akka源码分析-Cluster-Singleton
akka Cluster基本实现原理已经分析过,其实它就是在remote基础上添加了gossip协议,同步各个节点信息,使集群内各节点能够识别.在Cluster中可能会有一个特殊的节点,叫做单例节点. ...
- Akka源码分析-Cluster-ActorSystem
前面几篇博客,我们依次介绍了local和remote的一些内容,其实再分析cluster就会简单很多,后面关于cluster的源码分析,能够省略的地方,就不再贴源码而是一句话带过了,如果有不理解的地方 ...
- Akka源码分析-Cluster-Metrics
一个应用软件维护的后期一定是要做监控,akka也不例外,它提供了集群模式下的度量扩展插件. 其实如果读者读过前面的系列文章的话,应该是能够自己写一个这样的监控工具的.简单来说就是创建一个actor,它 ...
- Akka源码分析-Persistence
在学习akka过程中,我们了解了它的监督机制,会发现actor非常可靠,可以自动的恢复.但akka框架只会简单的创建新的actor,然后调用对应的生命周期函数,如果actor有状态需要回复,我们需要h ...
- Akka源码分析-Akka-Streams-概念入门
今天我们来讲解akka-streams,这应该算akka框架下实现的一个很高级的工具.之前在学习akka streams的时候,我是觉得云里雾里的,感觉非常复杂,而且又难学,不过随着对akka源码的深 ...
- Akka源码分析-local-DeathWatch
生命周期监控,也就是死亡监控,是akka编程中常用的机制.比如我们有了某个actor的ActorRef之后,希望在该actor死亡之后收到响应的消息,此时我们就可以使用watch函数达到这一目的. c ...
- Akka源码分析-Akka Typed
对不起,akka typed 我是不准备进行源码分析的,首先这个库的API还没有release,所以会may change,也就意味着其概念和设计包括API都会修改,基本就没有再深入分析源码的意义了. ...
- Akka源码分析-Cluster-ClusterClient
ClusterClient可以与某个集群通信,而本身节点不必是集群的一部分.它只需要知道一个或多个节点的位置作为联系节点.它会跟ClusterReceptionist 建立连接,来跟集群中的特定节点发 ...
随机推荐
- hdu 5093 二分匹配
/* 题意:给你一些冰岛.公共海域和浮冰,冰岛可以隔开两个公共海域,浮冰无影响 求选尽可能多的选一些公共海域点每行每列仅能选一个. 限制条件:冰山可以隔开这个限制条件.即*#*可以选两个 预处理: * ...
- [K/3Cloud] 树形单据体的应用说明
1.BOSIDE制作单据,支持动态表单,单据,基础资料,报表等域模型. 2.添加列,和原来单据体一样. 3.设置主键列名,父级主键字段名,行类型字段名,节点图片字段名(没有可以为空) 4.运行时展 ...
- android开发里跳过的坑——button不响应点击事件
昨天遇到一个头疼的问题,在手机上按钮事件都很正常,但是在平板上(横屏显示的状态),button点击事件不响应,代码简化如下: public class Test extends Activity im ...
- 文件权限设置与http,php的关系
在web服务器上的文件要使用什么权限比较好呢.我开始的时候直接都是777,后台安全部门的同事,通过漏洞把我管理的服务器给搞了.报告到我这里,我才意识到权限的设置不能马虎.环境采用nginx+php,一 ...
- AtCoder Grand Contest 020 D - Min Max Repetition
q<=1000个询问,每次问a,b,c,d:f(a,b)表示含a个A,b个B的字符串中,连续A或连续B最小的串中,字典序最小的一个串,输出这个串的c到d位.a,b<=5e8,d-c+1&l ...
- gulp基本语法
pipe:用管道输送 1.gulp.src(glops[, options]) 输出(Emits)符合所提供的匹配模式(glob)或者匹配模式的数组(array of globs)的文件. 将返回一个 ...
- 【c++】static_cast, dynamic_cast探讨
C++类型转换分为:隐式类型转换和显式类型转换 一.隐式类型转换 1) 算术转换(Arithmetic conversion) : 在混合类型的算术表达式中, 最宽的数据类型成为目标转换类型. ; d ...
- alias记录
在seajs里边会有配置alias对象属性的,这个就是一个别名,下次在模块加载的时候直接引用别名就好了. 别名配置,配置之后可在模块中使用require调用 require('jquery'); se ...
- scikit-learn:3. Model selection and evaluation
參考:http://scikit-learn.org/stable/model_selection.html 有待翻译,敬请期待: 3.1. Cross-validation: evaluating ...
- document.body.className = document.body.className.replace("siteorigin-panels-before-js","");
document.body.className = document.body.className.replace("siteorigin-panels-before-js",&q ...