Python Elasticsearch
以下所用版本为Elasticsearch 7.2.0
1.安装
pip3 install elasticsearch -i https://pypi.tuna.tsinghua.edu.cn/simple
2.连接ES
es = Elasticsearch([{'host': '127.0.0.1', 'port': 9200}])
3.创建index
index = 'index_tushare'
body = {
"mappings": {
"properties": {
"ts_code": {
"type": "keyword"
},
"symbol": {
"type": "keyword"
},
"ts_name": {
"type": "keyword"
},
"fullname": {
"type": "keyword"
},
"area": {
"type": "keyword"
},
"industry": {
"type": "keyword"
},
"list_date": {
"type": "keyword"
},
"tab_name": {
"type": "keyword"
}
}
}
}
# create an index in elasticsearch, ignore status code 400 (index already exists)
es.indices.create(index=index, body=body, ignore=400)
4.创建mapping之后,添加字段
index_daily_close = 'index_daily_close'
body_daily_close = {
"mappings": {
"properties": {
"trade_date": {
"type": "keyword"
}
}
}
}
es.indices.create(index=index_daily_close, body=body_daily_close, ignore=400) properties = body_daily_close.get("mappings").get("properties") def daily_close_add_tscodes(tscode):
properties.setdefault(tscode, {"type": "keyword"})
es.indices.put_mapping(index=index_daily_close, body=body_daily_close.get("mappings"))
print(body_daily_close.get("mappings"))
添加字段的时候要注意,elasticsearch默认最大字段数为1000,超过1000就会报错
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Limit of total fields [1000] in index [index_daily_close] has been exceeded"
}
],
"type": "illegal_argument_exception",
"reason": "Limit of total fields [1000] in index [index_daily_close] has been exceeded"
},
"status": 400
}
这里的1000是整个节点不能超过1000,我尝试了在多个索引里面添加字段,最终出现的结果是:
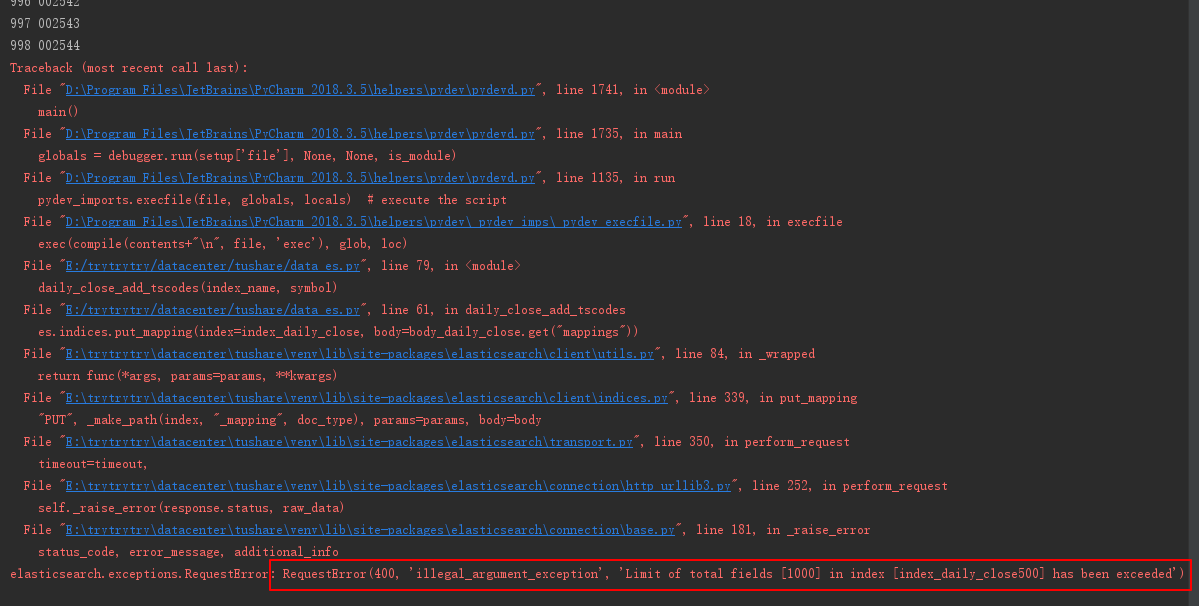
以上实验的方式是在第一个表中500个,然后第二个表中500个,在第998个的时候报错了。加上每个表本身有的 trade_date 字段,刚好加起来1000个。然后报错在了第1001个

Python Elasticsearch的更多相关文章
- Python Elasticsearch api,组合过滤器,term过滤器,正则查询 ,match查询,获取最近一小时的数据
Python Elasticsearch api 描述:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.下 ...
- Python Elasticsearch api
描述:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.下面介绍了利用Python API接口进行数据查询,方便 ...
- Python Elasticsearch批量操作客户端
基于Python实现的Elasticsearch批量操作客户端 by:授客 QQ:1033553122 1. 代码用途 1 2. 测试环境 1 3. 使用方法 1 3.1 配置ES服务器信息 1 ...
- python elasticsearch 批量写入数据
from elasticsearch import Elasticsearch from elasticsearch import helpers import pymysql import time ...
- Elasticsearch安装配置
文档地址: https://www.elastic.co/guide/en/elasticsearch/reference/6.5/setup.html 官方页面提供自0.9版本以来的说明文档,由于我 ...
- django学习系列——python和php对比
python 和 php 我都是使用过,这里不想做一个非常理性的分析,只是根据自己的经验谈一下感想. 在web开发方面,无疑 php 更甚一筹. 从某种角度来说,php 就是专门为 web 定制的语言 ...
- ELK系列三:Elasticsearch的简单使用和配置文件简介
1.定义模板创建索引: 首先定义好一个模板的例子 { "order":14, "template":"ids-1", "state ...
- linux 安装elasticsearch
一.检测是否已经安装的elasticsearch ps aux|grep elasticsearch. 二.下载elasticsearch.tar.gz并上传至服务器usr/local/文件夹下 三. ...
- 工作笔记 之 Python应用技术
python socket编程详细介绍 网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket,建立网络通信连接至少要一对端口号(socket). Socket本质是 ...
随机推荐
- node.js的iconv模块----在linux上读取windows编码文件
有时候我们在windows上会保存一些中文文字信息文件,然而由于编码集的差异,这文件在linux上显示为乱码,其中一种解决方法是node.js的iconv模块 var fs = require('fs ...
- java 正则《转载》
Java 正则表达式 正则表达式定义了字符串的模式. 正则表达式可以用来搜索.编辑或处理文本. 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别. 正则表达式实例 一个字符串其实就是一个简 ...
- SSH 远程上传本地文件至服务器
使用SSH命令行传输文件到远程服务器 以前一直在windows下用SSH Secure Shell连接远程服务器,它自带了一个可视化的文件传输工具,跟ftp差不多 但是它也存在一个缺陷,不支持编码 ...
- 畅通工程续(HDU 1874)(简单最短路)
某省自从实行了很多年的畅通工程计划后,终于修建了很多路.不过路多了也不好,每次要从一个城镇到另一个城镇时,都有许多种道路方案可以选择,而某些方案要比另一些方案行走的距离要短很多.这让行人很困扰. 现在 ...
- 代码审计-Typecho反序列化getshell
0x01 漏洞代码 install.php: <?php $config = unserialize(base64_decode(Typecho_Cookie::get('__typecho_c ...
- 安装Rabbitmq脚本
安装RabbitMQ时需要先安装erlang插件 [root@ZHONG-LONG javascripts]# vim -erlang.sh #!/bin/sh ######安装erl插件 PRO=/ ...
- Kotlin入门-Android的基础布局
线性布局线性布局LinearLayout是最常用的布局,顾名思义,它下面的子视图像是用一根线串了起来,所以其内部视图的排列是有顺序的,要么从上到下垂直排列,要么从左到右水平排列.排列顺序只能指定一维方 ...
- powershell命令教程
启动 powershell #字符串操作 对象操作 "hello".Length #进程操作 PS C:\> notepad PS C:\> $process=get- ...
- 程序间获取ALV显示数据(读取ALV GRID上的数据)
程序间获取ALV数据的两种方法: 方法1:通过修改SUBMIT的目标程序,把内表EXPORT到内存,SUBMIT后IMPORT ,该方法需要修改目标程序,可以任意设置目标程序的中断点: * Execu ...
- EasyUI之toolTip
<a class="easyui-tooltip" title="提示框" href="http://www.baidu.com"&g ...