k8s弹性伸缩概念以及测试用例
k8s弹性伸缩概念以及测试用例
本文原文出处:https://juejin.im/post/5c82367ff265da2d85330d4f
弹性伸缩式k8s中的一大亮点功能,当负载大的时候,你可以对应用进行扩容,提升pod的副本数来应对大量的流量,当负载小的时候可以对应用进行缩容,以避免资源浪费。也可以让应用自动的进行扩容和缩容,这一功能有用。例如当微博出现了一个话题时,这个时候人们都去访问,此时他的服务器将无法处理大量的流量访问,这个时候就需要扩容,而当这个话题不在新鲜时,人们的访问流量也就是降下来了,那么就需要对服务器进行缩容处理,来自动适应流量需求。
scale命令:扩容或缩容 Deployment、ReplicaSet、Replication Controller或 Job 中Pod数量
# 语法
kubectl scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME)
# 将名为foo中的pod副本数设置为3。
kubectl scale --replicas=3 rs/foo
kubectl scale deploy/nginx --replicas=30
# 将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3
kubectl scale --replicas=3 -f foo.yaml
# 如果当前副本数为2,则将其扩展至3。
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# 设置多个RC中Pod副本数量
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
k8s提供了scale和autoscale来进行扩容和缩容。

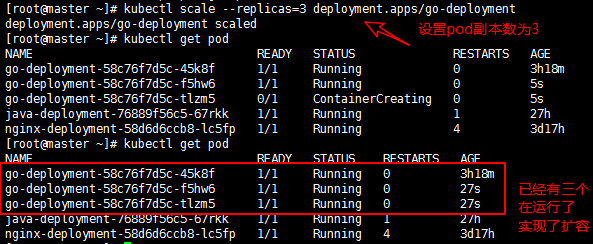
现在对go-deployment进行扩容,结果如图
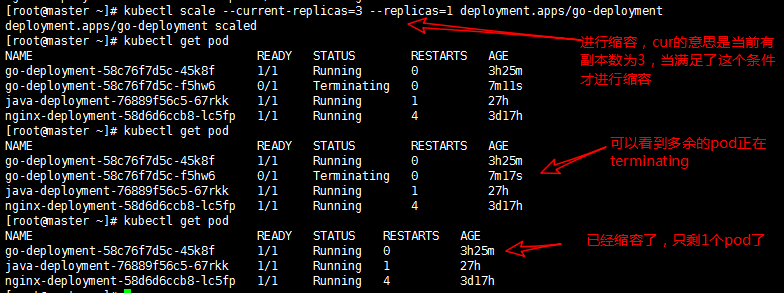
当访问量减少了就进行缩容
现在我不想手动的进行扩容和缩容了,我想实现让它当访问流量大的时候自动扩容,当访问流量小的时候自动缩容。这个时候autoscale出现了,利用他我们就可以实现自动扩容和缩容。
# 语法
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]
# 使用 Deployment “foo”设定,使用默认的自动伸缩策略,指定目标CPU使用率,使其Pod数量在2到10之间
kubectl autoscale deployment foo --min=2 --max=10
# 使用RC“foo”设定,使其Pod的数量介于1和5之间,CPU使用率维持在80%
kubectl autoscale rc foo --max=5 --cpu-percent=80
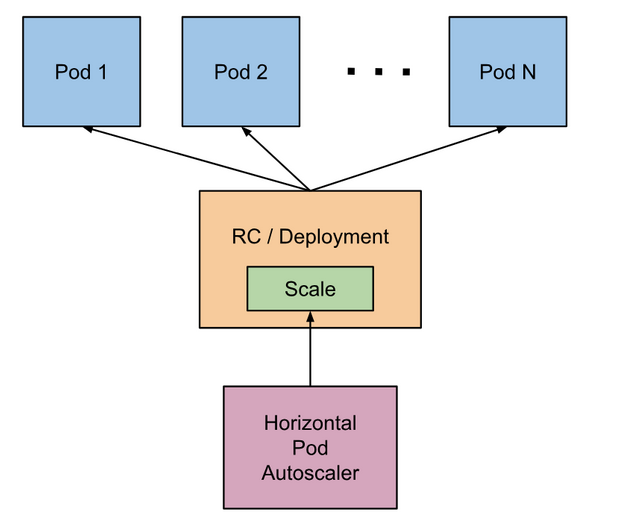
到目前为止,k8s一共提供了2个不同维度的AutoScaler。如下图:

k8s把弹性伸缩分为两类:
- 资源维度:保障集群资源池大小满足整体规划,当集群内的资源不足以支撑产出新的pod时,就会触发边界进行扩容
- 应用维度:保障应用的负载处在预期的容量规划内
对应两种伸缩策略:
- 水平伸缩
- 集群维度:自动调整资源池规模(新增/删除Worker节点)
- Pod维度:自动调整Pod的副本集数量
- 垂直伸缩
- 集群维度:不支持
- Pod维度:自动调整应用的资源分配(增大/减少pod的cpu、内存占用)
其中最为成熟也是最为常用的伸缩策略就是HPA(水平Pod伸缩),所以下面以它为例来重点分析,官方文档在此:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
缩容扩容的基本流程为三大步骤:
1.采集监控指标
2.聚合监控指标,判断是否需要执行缩扩容
3.执行缩容扩容操作
HPA水平缩容扩容架构图
HPA的监控指标
根据官方文档的描述,HPA是使用巡检(Control Loop)的机制来采集Pod资源使用情况的,默认采集间隔为15s,可以通过Controller Manager(Master节点上的一个进程)的--horizontal-pod-autoscaler-sync-period参数来手动控制。
目前HPA默认采集指标的实现是Heapster,它主要采集CPU的使用率;beta版本也支持自定义的监控指标采集,但尚不稳定,不推荐使用
因此可以简单认为,HPA就是通过CPU的使用率作为监控指标的。
聚合算法
采集到CPU指标后,k8s通过下面的公式来判断需要扩容多少个pod
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
ceil表示向上取整,举个实际例子,假设某个服务运行了4个Pod,当前的CPU使用率为50%,预期的CPU使用率为25%,那么满足预期的实际Pod数量就是4 * (50% / 25%) = 8个,即需要将Pod容量扩大一倍,增加4个Pod来满足需求。
当然上述的指标并不是绝对精确的,首先,k8s会尽可能的让指标往期望值靠近,而不是完全相等,其次HPA设置了一个容忍度(tolerance)的概念,允许指标在一定范围内偏离期望值,默认是0.1,这就意味着如果你设置调度策略为CPU预期使用率 = 50%,实际的调度策略会是小于45%或者大于55%进行缩扩容,HPA会尽力把指标控制在这个范围内(容忍度可以通过--horizontal-pod-autoscaler-tolerance来调整)
需要注意的是:
- 一是k8s做出决策的间隔,它不会连续地执行扩缩容动作,而是存在一定的cd,目前扩容动作的cd为3分钟,缩容则为5分钟
- 二是k8s针对扩容做了一个最大限制,每次扩容的pod数量不会大于当前副本数量的2倍。
k8s弹性伸缩概念以及测试用例的更多相关文章
- k8s 弹性伸缩
k8s弹性伸缩,需要附加插件heapster 1.安装heapster监控 1:上传并导入镜像,打标签 ls *.tar.gz for n in `ls *.tar.gz`;do docker loa ...
- DOCKER 学习笔记9 Kubernetes (K8s) 弹性伸缩容器 下
前言 从上一篇看来,我们已经对于Kubernetes ,通过minikube 建立集群,而后使用kubectl 进行交互,对Deployment 部署以及服务的暴露等.这节,将学习弹性的将服务部署到多 ...
- Kubernetes 弹性伸缩全场景解析 (一)- 概念延伸与组件布局
传统弹性伸缩的困境 弹性伸缩是Kubernetes中被大家关注的一大亮点,在讨论相关的组件和实现方案之前.首先想先给大家扩充下弹性伸缩的边界与定义,传统意义上来讲,弹性伸缩主要解决的问题是容量规划与实 ...
- Kubernetes 弹性伸缩全场景解析 (一):概念延伸与组件布局
传统弹性伸缩的困境 弹性伸缩是 Kubernetes 中被大家关注的一大亮点,在讨论相关的组件和实现方案之前.首先想先给大家扩充下弹性伸缩的边界与定义,传统意义上来讲,弹性伸缩主要解决的问题是容量规划 ...
- Kubernetes 弹性伸缩全场景解读(二)- HPA 的原理与演进
前言 在上一篇文章 Kubernetes 弹性伸缩全场景解析 (一):概念延伸与组件布局中,我们介绍了在 Kubernetes 在处理弹性伸缩时的设计理念以及相关组件的布局,在今天这篇文章中,会为大家 ...
- Kubernetes 弹性伸缩全场景解读(五) - 定时伸缩组件发布与开源
作者| 阿里云容器技术专家刘中巍(莫源) 导读:Kubernetes弹性伸缩系列文章为读者一一解析了各个弹性伸缩组件的相关原理和用法.本篇文章中,阿里云容器技术专家莫源将为你带来定时伸缩组件 kub ...
- Serverless 与容器决战在即?有了弹性伸缩就不一样了
作者 | 阿里云容器技术专家 莫源 本文整理自莫源于 8 月 31 日 K8s & cloudnative meetup 深圳场的演讲内容.****关注"阿里巴巴云原生" ...
- Kubernetes(K8s)基础概念 —— 凿壁偷光
Kubernetes(K8s)基础概念 -- 凿壁偷光 K8s是什么:全称 kubernetes (k12345678s) 作用:用于自动部署,扩展和管理"容器化应用程序"的 ...
- 基于Raft构建弹性伸缩的存储系统的一些实践
基于Raft构建弹性伸缩的存储系统的一些实践 原创 2016-07-18 黄东旭 聊聊架构 最近几年来,越来越多的文章介绍了 Raft 或者 Paxos 这样的分布式一致性算法,但主要集中在算法细节和 ...
随机推荐
- SpringSecurity——默认过滤器链
介绍Spring Security默认的过滤器链,介绍顺序按照过滤器在过滤器链中的顺序排序 1.WebAsyncManagerIntegrationFilter 将Security上下文与Spring ...
- 前世今生:Hive、Shark、spark SQL
Hive (http://en.wikipedia.org/wiki/Apache_Hive )(非严格的原文顺序翻译) Apache Hive是一个构建在Hadoop上的数据仓库框架,它提供数据的 ...
- AutoItLibrary测试Windows GUI
AutoItLibrary库关键字 AutoItLibrary 的对象操作大体上有几大主要部分,Window 操作.Control 操作.Mouse 操作.Process操作.Run 操作.Reg 操 ...
- 在已开启Chrome窗口上调试
代码 @Test void testNow() { /* First: Add the chrome.exe to the PATH. * Then: open the cmd and input t ...
- windos批处理启动redis与哨兵
为各个启动单独建立脚本后用总的bat调用 创建脚本,redis6379.bat脚本内容:@echo offtitle redis-serverset ENV_HOME6379="G:\Red ...
- Struts 简单UI标签
<!-- 服务器标签 : 最终别解析为html标签--> <s:form action="/user_login" method="post" ...
- WPF使用cefsharp 下载地址
源码下载: https://github.com/cefsharp/CefSharp dll类库包下载nuget: https://www.nuget.org/packages/CefSharp.Wp ...
- vue-cli3的安装使用
一.安装vue-cli3 1.全局安装vue-cli 使用命令 cnpm install -g @vue/cli . npm install -g @vue/cli.yarn global add ...
- 在web项目中获取ApplicationContext上下文的3种主要方式及适用情况
最近在做web项目,需要写一些工具方法,涉及到通过Java代码来获取spring中配置的bean,并对该bean进行操作的情形.而最关键的一步就是获取ApplicationContext,过程中纠结和 ...
- 解决vmware fusion + centos 7安装vmtools时提示The path "" is not a valid path to the xxx kernel headers.
近日使用VMware fushion 8 + centos 7.0时,无法使用共享功能,所以必须安装vmtools.但是安装过程中有2个错误需要解决. 1.gcc错误 Searching for GC ...