十六, k8s集群资源需求和限制, 以及pod驱逐策略。
容器的资源需求和资源限制
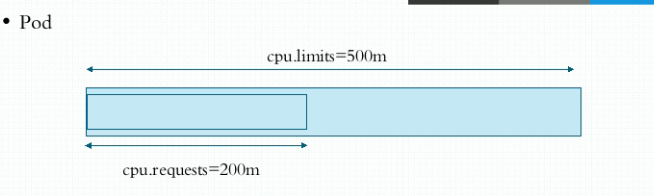
- requests:资源需求,最低保障, 保证被调度的节点上至少有的资源配额
- limits:资源限额,硬限制, 容器可以分配到的最大资源配额
- limits一般大于等于requests
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
labels:
app: myapp
tier: fronted
spec:
containers:
- name: myapp
image: ikubernetes/stress-ng #压测的镜像
command: ["/usr/bin/stress-ng", "-m 1", "-c 1", "--metrics-brief"]
resources: #定义资源限额等
requests:
cpu: "200m"
memory: "128Mi"
limits:
cpu: "500m" #1颗cpu=1000m
memory: "200Mi"
kubectl exec pod-demo -- top
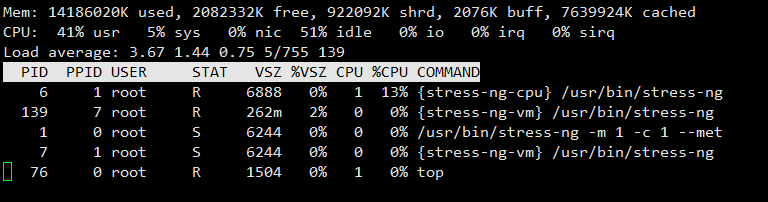
这是一个CPU为4核的节点, 分配给容器500m的CPU, 也就是0.125个CPU, 所以看到的进程CPU占用率约为13%
QoS Classes分类
Guaranteed
确保类型,此类pod具有最高优先级
如果Pod中所有Container的所有Resource的limit和request都相等且不为0,则这个Pod的QoS Class就是Guaranteed。
注意,如果一个容器只指明了limit,而未指明request,则表明request的值等于limit的值。
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
labels:
app: myapp
tier: fronted
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
resources: #定义资源限额等
requests:
cpu: "200m"
memory: "200Mi"
limits:
cpu: "200m" #1颗cpu=1000m
memory: "200Mi"
[root@master scheduler]# kubectl describe pods pod-demo
Name: pod-demo
Namespace: default
Priority: 0
。。。。。。
。。。。。。
QoS Class: Guaranteed #此时已经是Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11s default-scheduler Successfully assigned default/pod-demo to node3
Normal Pulled 9s kubelet, node3 Container image "ikubernetes/myapp:v1" already present on machine
Normal Created 8s kubelet, node3 Created container myapp
Normal Started 8s kubelet, node3 Started container myapp
Burstable
至少有一个容器设置CPU或内存资源的requests属性,此类pod具有中等优先级
Best-Effort
如果Pod中所有容器的所有Resource的request和limit都没有赋值,则这个Pod的QoS Class就是Best-Effort,优先级最低
containers:
name: foo
resources:
name: bar
resources:
kubernetes之node资源紧缺时pod驱逐机制
Qos Class优先级排名
Guaranteed > Burstable > Best-Effort
当节点资源紧缺时,优先级低的pod会最先被节点驱逐,Burstable类型下,已占用量与需求量比值大的先被驱逐(已占用500M的request512M的pod1和已占用512M的request1024M的pod2,先驱逐pod1)
可压缩资源与不可压缩资源
Pod 使用的资源最重要的是 CPU、内存和磁盘 IO,这些资源可以被分为可压缩资源(CPU)和不可压缩资源(内存,磁盘 IO)。
可压缩资源
(CPU)不会导致pod被驱逐因为当 Pod 的 CPU 使用量很多时,系统可以通过重新分配权重来限制 Pod 的 CPU 使用
不可压缩资源
(内存)则会导致pod被驱逐于不可压缩资源来说,如果资源不足,也就无法继续申请资源(内存用完就是用完了),此时 Kubernetes 会从该节点上驱逐一定数量的 Pod,以保证该节点上有充足的资源。
存储资源不足
下面是 kubelet 默认的关于节点存储的驱逐触发条件:
- nodefs.available<10%(容器 volume 使用的文件系统的可用空间,包括文件系统剩余大小和 inode 数量)
- imagefs.available<15%(容器镜像使用的文件系统的可用空间,包括文件系统剩余大小和 inode 数量)
当 imagefs 使用量达到阈值时,kubelet 会尝试删除不使用的镜像来清理磁盘空间。
当 nodefs 使用量达到阈值时,kubelet 就会拒绝在该节点上运行新 Pod,并向 API Server 注册一个 DiskPressure condition。然后 kubelet 会尝试删除死亡的 Pod 和容器来回收磁盘空间,如果此时 nodefs 使用量仍然没有低于阈值,kubelet 就会开始驱逐 Pod。kubelet 驱逐 Pod 的过程中不会参考 Pod 的 QoS,只是根据 Pod 的 nodefs 使用量来进行排名,并选取使用量最多的 Pod 进行驱逐。所以即使 QoS 等级为 Guaranteed 的 Pod 在这个阶段也有可能被驱逐(例如 nodefs 使用量最大)。如果驱逐的是 Daemonset,kubelet 会阻止该 Pod 重启,直到 nodefs 可用量超过阈值。
如果一个 Pod 中有多个容器,kubelet 会根据 Pod 中所有容器的 nodefs 使用量之和来进行排名。即所有容器的
container_fs_usage_bytes指标值之和。
举例
| Pod Name | Pod QoS | nodefs usage |
|---|---|---|
| A | Best Effort | 800M |
| B | Guaranteed | 1.3G |
| C | Burstable | 1.2G |
| D | Burstable | 700M |
| E | Best Effort | 500M |
| F | Guaranteed | 1G |
当 nodefs 的使用量超过阈值时,kubelet 会根据 Pod 的 nodefs 使用量来对 Pod 进行排名,首先驱逐使用量最多的 Pod。排名如下图所示:
| Pod Name | Pod QoS | nodefs usage |
|---|---|---|
| B | Guaranteed | 1.3G |
| C | Burstable | 1.2G |
| F | Guaranteed | 1G |
| A | Best Effort | 800M |
| D | Burstable | 700M |
| E | Best Effort | 500M |
内存资源不足
下面是 kubelet 默认的关于节点内存资源的驱逐触发条件:
- memory.available<100Mi
当内存使用量超过阈值时,kubelet 就会向 API Server 注册一个 MemoryPressure condition,此时 kubelet 不会接受新的 QoS 等级为 Best Effort 的 Pod 在该节点上运行,并按照以下顺序来驱逐 Pod:
- Pod 的内存使用量是否超过了
request指定的值 - 根据 priority 排序,优先级低的 Pod 最先被驱逐
- 比较它们的内存使用量与
request指定的值之差。
按照这个顺序,可以确保 QoS 等级为 Guaranteed 的 Pod 不会在 QoS 等级为 Best Effort 的 Pod 之前被驱逐,但不能保证它不会在 QoS 等级为 Burstable 的 Pod 之前被驱逐。
如果一个 Pod 中有多个容器,kubelet 会根据 Pod 中所有容器相对于 request 的内存使用量与之和来进行排名。即所有容器的 (
container_memory_usage_bytes指标值与container_resource_requests_memory_bytes指标值的差)之和。
举例
| Pod Name | Pod QoS | Memory requested | Memory limits | Memory usage |
|---|---|---|---|---|
| A | Best Effort | 0 | 0 | 700M |
| B | Guaranteed | 2Gi | 2Gi | 1.9G |
| C | Burstable | 1Gi | 2Gi | 1.8G |
| D | Burstable | 1Gi | 2Gi | 800M |
| E | Best Effort | 0 | 0 | 300M |
| F | Guaranteed | 2Gi | 2Gi | 1G |
当节点的内存使用量超过阈值时,kubelet 会根据 Pod 相对于 request 的内存使用量来对 Pod 进行排名。排名如下所示:
| Pod Name | Pod QoS | Memory requested | Memory limits | Memory usage | 内存相对使用量 |
|---|---|---|---|---|---|
| C | Burstable | 1Gi | 2Gi | 1.8G | 800M |
| A | Best Effort | 0 | 0 | 700M | 700M |
| E | Best Effort | 0 | 0 | 300M | 300M |
| B | Guaranteed | 2Gi | 2Gi | 1.9G | -100M |
| D | Burstable | 1Gi | 2Gi | 800M | -200M |
| F | Guaranteed | 2Gi | 2Gi | 1G | -1G |
当内存资源不足时,kubelet 在驱逐 Pod 时只会考虑 requests 和 Pod 的内存使用量,不会考虑 limits。
Node OOM (Out Of Memory)
因为 kubelet 默认每 10 秒抓取一次 cAdvisor 的监控数据,所以有可能在 kubelet 驱逐 Pod 回收内存之前发生内存使用量激增的情况,这时就有可能触发内核 OOM killer。这时删除容器的权利就由kubelet 转交到内核 OOM killer 手里,但 kubelet 仍然会起到一定的决定作用,它会根据 Pod 的 QoS 来设置其 oom_score_adj 值:
| QoS | oom_score_adj |
|---|---|
| Guaranteed | -998 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
| pod-infra-container | -998 |
| kubelet, docker daemon, systemd service | -999 |
如果该节点在 kubelet 通过驱逐 Pod 回收内存之前触发了 OOM 事件,OOM killer 就会采取行动来降低系统的压力,它会根据下面的公式来计算 oom_score 的值:
容器使用的内存占系统内存的百分比 + oom_score_adj = oom_score>
OOM killer 会杀掉 oom_score_adj 值最高的容器,如果有多个容器的 oom_score_adj 值相同,就会杀掉内存使用量最多的容器(其实是因为内存使用量最多的容器的 oom_score 值最高)。关于 OOM 的更多内容请参考:Kubernetes 内存资源限制实战。
假设某节点运行着 4 个 Pod,且每个 Pod 中只有一个容器。每个 QoS 类型为 Burstable 的 Pod 配置的内存 requests 是 4Gi,节点的内存大小为 30Gi。每个 Pod 的 oom_score_adj 值如下所示:
| Pod Name | Pod QoS | oom_score_adj |
|---|---|---|
| A | Best Effort | 1000 |
| B | Guaranteed | -998 |
| C | Burstable | 867(根据上面的公式计算) |
| D | Best Effort | 1000 |
当调用 OOM killer 时,它首先选择 oom_score_adj 值最高的容器(1000),这里有两个容器的 oom_score_adj 值都是 1000,OOM killer 最终会选择内存使用量最多的容器。
总结
- 因为 kubelet 默认
每 10 秒抓取一次cAdvisor 的监控数据,所以可能在资源使用量低于阈值时,kubelet 仍然在驱逐 Pod。 - kubelet 将 Pod 从节点上驱逐之后,Kubernetes 会将该 Pod 重新调度到另一个资源充足的节点上。但有时候 Scheduler 会将该 Pod 重新调度到与之前相同的节点上,比如设置了节点亲和性,或者该 Pod 以 Daemonset 的形式运行。
十六, k8s集群资源需求和限制, 以及pod驱逐策略。的更多相关文章
- Prometheus 监控K8S集群资源监控
Prometheus 监控K8S集群中Pod 目前cAdvisor集成到了kubelet组件内,可以在kubernetes集群中每个启动了kubelet的节点使用cAdvisor提供的metrics接 ...
- 四,k8s集群资源清单定义入门
目录 资源对象 创建资源的方法 清单帮助命令 创建测试清单 资源的三种创建方式 资源对象 workload:Pod, ReplicaSet, Deployment, StatefulSet, Daem ...
- ES系列十六、集群配置和维护管理
一.修改配置文件 1.节点配置 1.vim elasticsearch.yml # ======================== Elasticsearch Configuration ===== ...
- Dubbo实践(十六)集群容错
Dubbo作为一个分布式的服务治理框架,提供了集群部署,路由,软负载均衡及容错机制.下图描述了Dubbo调用过程中的对于集群,负载等的调用关系: 集群 Cluster 将Directory中的多个In ...
- Redis(十六):集群搭建(手动和自动)
一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2):slave->master ...
- 三十六.MHA集群概述 、 部署MHA集群 测试配置
1.准备MHA集群环境 准备6台虚拟机,并按照本节规划配置好IP参数 在这些虚拟机之间实现SSH免密登录 在相应节点上安装好MHA相关的软件包 使用6台RHEL 7虚拟机,如图-1所示.准备集群环 ...
- k8s集群Job负载 支持多个 Pod 可靠的并发执行,如何权衡利弊选择适合的并行计算模式?
k8s的Job负载 支持多个 Pod 可靠的并发执行,如何权衡利弊选择适合的并行计算模式? 简单聊聊你对工作负载Job的理解? Job 支持多个 Pod 可靠的并发执行,如何权衡利弊选择适合的并行计算 ...
- k8s集群搭建(一)
k8s简介 kubernetes,简称K8s,是用8代替8个字符“ubernete”而成的缩写.是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简 ...
- k8s集群启动了上万个容器(一个pod里放上百个容器,起百个pod就模拟出上万个容器)服务器超时,无法操作的解决办法
问题说明: 一个POD里放了百个容器,然后让K8S集群部署上百个POD,得到可运行上万个容器的实验目的. 实验环境:3台DELL裸机服务器,16核+64G,硬盘容量忽略吧,上T了,肯定够. 1.一开始 ...
随机推荐
- 使用super函数----增量重写普通方法和构造方法
使用super函数----增量重写普通方法和构造方法 在子类中如果重写了超类的方法,通常需要在子类方法中调用超类的同名方法,也就是说,重写超类的方法,实际上应该是一种增量的重写方式,子类方法会在超类的 ...
- Android view的一些认识
转载:9102年末,我对Android view的13条认识: (顺手留下GitHub链接,需要获取相关面试等内容的可以自己去找)https://github.com/xiangjiana/Andro ...
- 深入理解channels - kavya Joshi
From: 翻译blog地址 作者:大桥下的蜗牛 这是GopherCon 2017大会上,go开发专家 kavya Joshi 的一篇关于 channel 的演讲,讲的通俗易懂. Understand ...
- python之pandas学习笔记-初识pandas
初识pandas python最擅长的就是数据处理,而pandas则是python用于数据分析的最常用工具之一,所以学python一定要学pandas库的使用. pandas为python提供了高性能 ...
- 【VS开发】获取CPU tick tick 周期
多核处理器时,__rdtsc()的使用-编程珠玑第一章 根据书中提供的代码清单1-5,可以完成对于多核处理器的cpu占用率的控制. 但是在使用GetCPUTickCount计时时,下面的算式会出现一点 ...
- echarts中国地图描绘
<!DOCTYPE html><html lang="zh-CN"><head> <meta charset="utf-8&qu ...
- CentOS 7 利用qemu模拟ARM vexpress A9开发板
听说qemu用于仿真arm很不错,今日就来试了一把.由于刚刚开始,了解的并不多.本文仅仅记录Qemu装载Linux kernel和busybox根文件系统的过程.后续将会深入了解仿真的其他内容. 先上 ...
- 《你必须知道的495个C语言问题》读书笔记之第4-7章:指针
1. Q:为什么我不能对void *指针进行算术运算? A:因为编译器不知道所值对象的大小,而指针的算法运算总是基于所指对象的大小的. 2. Q:C语言可以“按引用传参”吗? A:不可以.严格来说,C ...
- 记录一次 hadoop yarn resourceManager无故切换的故障
某日 收到告警 线上集群rm切换 观察resourcemanager 日志报错如下 这行不明显 再看看其他日志报错 在 app attempt_removed 时候发生了空指针错误 break; ca ...
- 什么是云解析DNS?
产品概述 云解析DNS(Alibaba Cloud DNS)是一种安全.快速.稳定.可扩展的权威DNS服务,云解析DNS为企业和开发者将易于管理识别的域名转换为计算机用于互连通信的数字IP地址,从而将 ...