spark2.1.0的源码编译
本文介绍spark2.1.0的源码编译
1.编译环境:
Jdk1.8或以上
Hadoop2.7.3
Scala2.10.4
必要条件:
Maven 3.3.9或以上(重要)
点这里下载
http://mirror.bit.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
修改/conf/setting.xml
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
2. 下载http://spark.apache.org
2.1Download

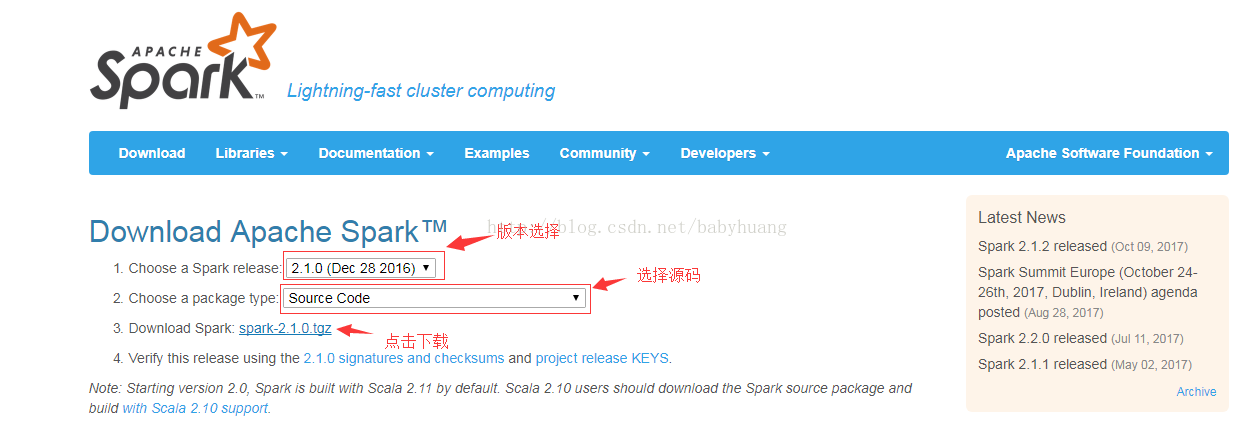
2.2. 解压
tar -zxvf spark-2.1.0.tgz
3. 进入主目录,修改编译文件,进行编译
修改spark-2.1.0/dev目录下的make-distribution.sh ,注释掉原来的指定版本,可以节省时间
vi make-distribution.sh
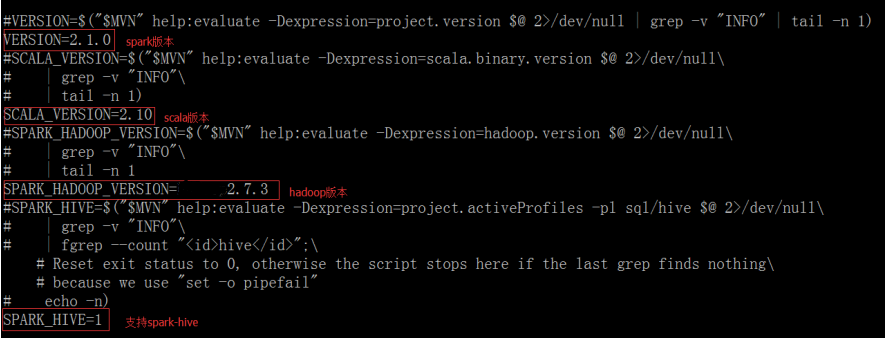
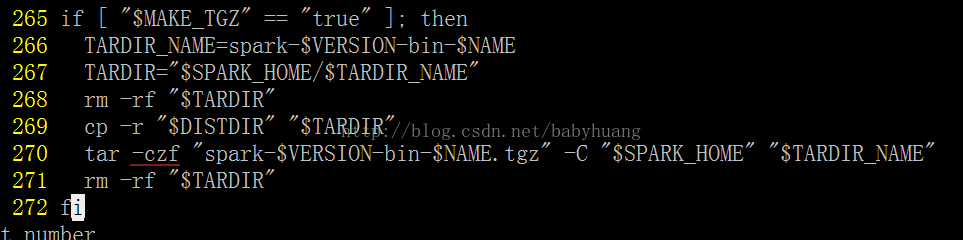
温馨提示:
该文件中如图所示,czf前少个“-”,需要自己修改
注意:
如果你用的hadoop版本是cdh的,那么需要修改spark根目录pom.xml文件,添加cdh的依赖
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
添加在<repositorys></repositorys>里
3.1设置内存
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
3.2编译
./dev/make-distribution.sh \
--name 2.7.3 \
--tgz \
-Pyarn \
-Phadoop-2.7 \ -Dhadoop.version=2.7.3 \
-Phive -Phive-thriftserver \
-DskipTests clean package
接下来就静静地等待吧,第一次编译时间可能很长,几小时或十几小时,取决于网速,因为要下载很多包
命令解释:
--name 2.7.3 ***指定编译出来的spark名字,name=
--tgz ***压缩成tgz格式
-Pyarn \ ***支持yarn平台
-Phadoop-2.7 \ -Dhadoop.version=2.7.3 \ ***指定hadoop版本为2.7.3
-Phive -Phive-thriftserver \ ***支持hive
-DskipTests clean package ***跳过测试包
好了,spark的编译到此就结束了
下面分享一下编译遇到的一些问题
错误1:
Failed to execute goal on project spark-launcher_2.11:
Could not resolve dependencies for project org.apache.spark:spark-launcher_2.11:jar:2.1.0:
Failure to find org.apache.hadoop:hadoop-client:jar:hadoop2.7.3 in https://repo1.maven.org/maven2 was cached in the local repository,
resolution will not be reattempted until the update interval of central has elapsed or updates are forced -> [Help 1]
解决:遇该错误,原因可能是编译命令中有参数写错。。。。(希望你没遇到 )
)
错误2:
+ tar czf 'spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3.tgz' -C /zhenglh/new-spark-build/spark-2.1.0 'spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3'
tar (child): Cannot connect to spark-[info] Compile success at Nov 28, 2017 11: resolve failed
编译的结果没打包:
spark-[info] Compile success at Nov 28, 2017 11:27:10 AM [20.248s]-bin-2.7.3
这个错误可能第一次编译的人都会遇到
解决:见温馨提示
spark2.1.0的源码编译的更多相关文章
- 英蓓特Mars board的android4.0.3源码编译过程
英蓓特Mars board的android4.0.3源码编译过程 作者:StephenZhu(大桥++) 2013年8月22日 若要转载,请注明出处 一.编译环境搭建及要点: 1. 虚拟机软件virt ...
- Spark2.1.0之源码分析——事件总线
阅读提示:阅读本文前,最好先阅读<Spark2.1.0之源码分析——事件总线>.<Spark2.1.0事件总线分析——ListenerBus的继承体系>及<Spark2. ...
- 非寻常方式学习ApacheTomcat架构及10.0.12源码编译
概述 开启博客分享已近三个月,感谢所有花时间精力和小编一路学习和成长的伙伴们,有你们的支持,我们继续再接再厉 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Tomcat官 ...
- 解决Tomcat10.0.12源码编译问题进而剖析其优秀分层设计架构
概述 Tomcat.Jetty.Undertow这几个都是非常有名实现Servlet规范的应用服务器,Tomcat本身也是业界上非常优秀的中间件,简单可将Tomcat看成是一个Http服务器+Serv ...
- Spark-2.0.2源码编译
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6813925210731840013/ Spark官网下载地址: http://spark.apache.org/d ...
- android 5.0 (lollipop)源码编译环境搭建(Mac OS X)
硬件环境:MacBook Pro Retina, 13-inch, Late 2013 处理器 2.4 GHz Intel Core i5 内存 8 GB 1600 MHz DDR3 硬盘60G以 ...
- hadoop2.0 eclipse 源码编译
在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/archive/2013/07/05/3172889.html hadoop cdh4编 ...
- anroid 6.0.1_r77源码编译
一.源码下载(基本类似4.4.4_r1) 二.必须使用openjdk1.7 sudo add-apt-repository ppa:openjdk-r/ppa sudo apt-get update ...
- kafka 0.11.0.3 源码编译
首先下载 kafka 0.11.0.3 版本 源码: http://mirrors.hust.edu.cn/apache/kafka/0.11.0.3/ 下载源码 首先安装 gradle,不再说明 1 ...
随机推荐
- vue基于 element ui 的按钮点击节流
vue的按钮点击节流 场景: 1.在实际使用中,当我们填写表单,点击按钮提交的时候,当接口没返回之前,迅速的点击几次,就会造成多次提交. 2.获取验证码,不频繁的获取. 3.弹幕不能频繁的发 基于这几 ...
- 使用querySelector添加移除style和class
document.querySelector(selector).style.styleName = 样式 对dom节点添加一个样式 document.querySelector(".nam ...
- Luogu5401 CTS2019珍珠(生成函数+容斥原理+NTT)
显然相当于求有不超过n-2m种颜色出现奇数次的方案数.由于相当于是对各种颜色选定出现次数后有序排列,可以考虑EGF. 容易构造出EGF(ex-e-x)/2=Σx2k+1/(2k+1)!,即表示该颜色只 ...
- 如何让类数组也使用数组的方法比如:forEach()
思路: 让类数组绑定数组的方法<div>1</div><div>2</div>方法一: let div = document.getElementsBy ...
- 【Zookeeper】本地ZK的搭建
很久没有写了..最近看书的笔记都记在有道云上面..框架的使用觉得还是有必要写一下 1.下载 官网:https://www.apache.org/dyn/closer.cgi 清华镜像:https:// ...
- Java--8--新特性--Stream API
Stream API 提供了一种高效且易于使用的处理数据的方式,(java.util.stream.*) 他可以对数组,集合等做一些操作,最终产生一个新的流,原数据是不会发生改变的. “集合”讲的是数 ...
- 【20191118会议】针对华为云CCE 问题总结
针对华为云CCE问题总结 如何购买CCE集群 可以分为测试环境和生产环境,针对使用范围进行购买集群. 测试环境 可以进行公用 生产环境建议使用单独集群 尤其针对部门大 耦合性不高 ,生产环境 建议使用 ...
- [Abp vNext微服务实践] - 框架分析
一.简介 abp vNext新框架的热度一直都很高,于是最近上手将vNext的微服务Demo做了一番研究.我的体验是,vNext的微服务架构确实比较成熟,但是十分难以上手,对于没有微服务开发经验的.n ...
- unity协程要点
使用协程做计时功能应注意 1.协程中用到的组件,变量等被置空前,应该将协程置空 2.置空协程之前应停止协程 3.为了确保同一个协程同时只运行一次,可在协程开始前添加安全代码:判断改协程是否存在,存在则 ...
- MyBatis_[tp_50]_动态sql_bind绑定 与原生sql对比
笔记要点出错分析与总结 更推荐,原生的sql写法,bind方法不灵活! Test中: e.setLastName("%e%"); 直接在这里写上模糊查询的语句,更加省时 配置中: ...