ElasticSearch + Canal 开发千万级的实时搜索系统【转】
公司是做社交相关产品的,社交类产品对搜索功能需求要求就比较高,需要根据用户城市、用户ID昵称等进行搜索。
项目原先的搜索接口采用SQL查询的方式实现,数据库表采用了按城市分表的方式。但随着业务的发展,搜索接口调用频次越来越高,搜索接口压力越来越大,搜索数据库经常崩溃,从而导致搜索功能经常不能使用。
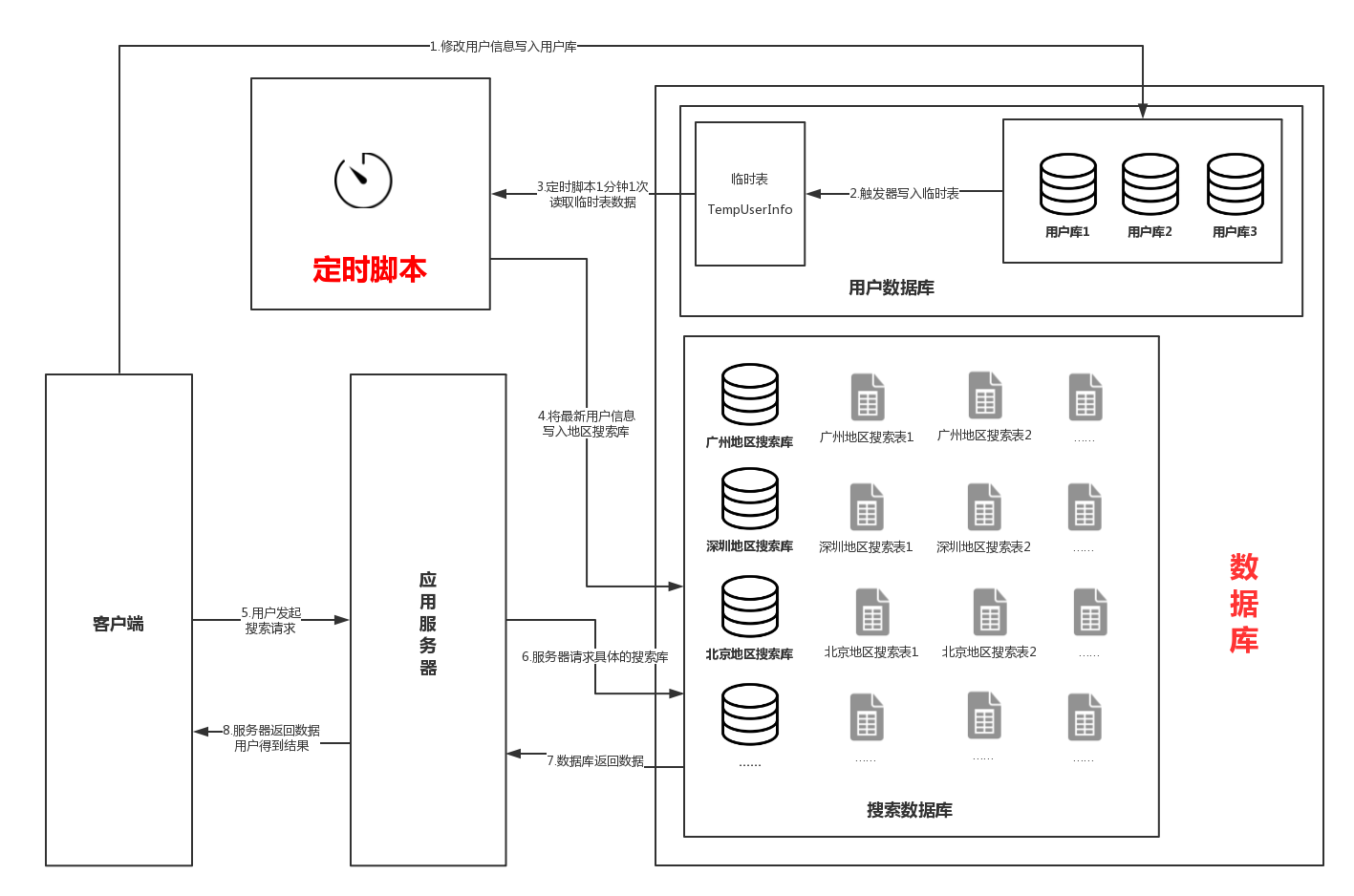
从上面的系统架构图可以看出,当用户修改资料时,接口会修改用户库信息,接着触发器会将改变的用户信息写入临时表。定时脚本每隔1分钟扫描一次临时表,将变更的数据写入到搜索库中。当用户再次请求搜索接口时,就可以搜索到最新的数据。
从技术层面分析,原搜索系统的设计有以下缺点:
- 搜索信息不实时。当用户修改信息时,需要等待1分钟的时间才能将最新的用户信息同步到搜索数据库中。
- ID、昵称搜索速度慢。按照地区分表的数据库设计是为了减轻数据库压力,保证大部分按照地区搜索的请求能正常响应。但是如果用户按照ID或昵称搜索,那么我们就需要对成千上万个地区表全都搜索一次,这时间复杂度可想而知。很多时候按照昵称和ID搜索速度太慢,需要10多秒才能响应。
- 系统稳定性、拓展性以及处理能力差。这可以归结为技术老旧,无法满足业务需求。随着搜索量的提升,对数据库的压力将会越来越大,而MySQL数据库天然不适合用来应对海量的请求。现在已经有更加成熟的ElasticSearch可以用来做搜索方面的业务。
- 触发器不便于管理。触发器这种东西不好维护,并且扩展性很差,一旦修改的请求变多,很可能导致整个数据库崩溃(用户库崩溃是很严重的)。
我们总结一下新搜索系统需要解决的几个问题:
- 海量请求。几百万的请求毫无压力,上千万上亿也要可以扛得住。
- 实时搜索。指的是当一个用户修改了其数据之后,另一个用户能实时地搜索到改用户。
海量请求。要扛得起海量的搜索请求,可以使用ElasticSearch来实现,它是在Lucene的基础上进行封装的一个开源项目,它将Lucene复杂的原理以及API封装起来,对外提供了一个易用的API接口。ElasticSearch现在已经广泛地被许多公司使用,其中包括:爱奇艺、百姓网、58到家等公司。
实时搜索。阿里有一个开源项目Canal,就是用来解决这个问题的,Canal项目利用了MySQL数据库主从同步的原理,将Canal Server模拟成一台需要同步的从库,从而让主库将binlog日志流发送到Canal Server接口。Canal项目对binlog日志的解析进行了封装,我们可以直接得到解析后的数据,而不需要理会binlog的日志格式。而且Canal项目整合了zookeeper,整体实现了高可用,可伸缩性强,是一个不错的解决方案。
经过一段时间的技术预研,我们设计了整个搜索技术架构:
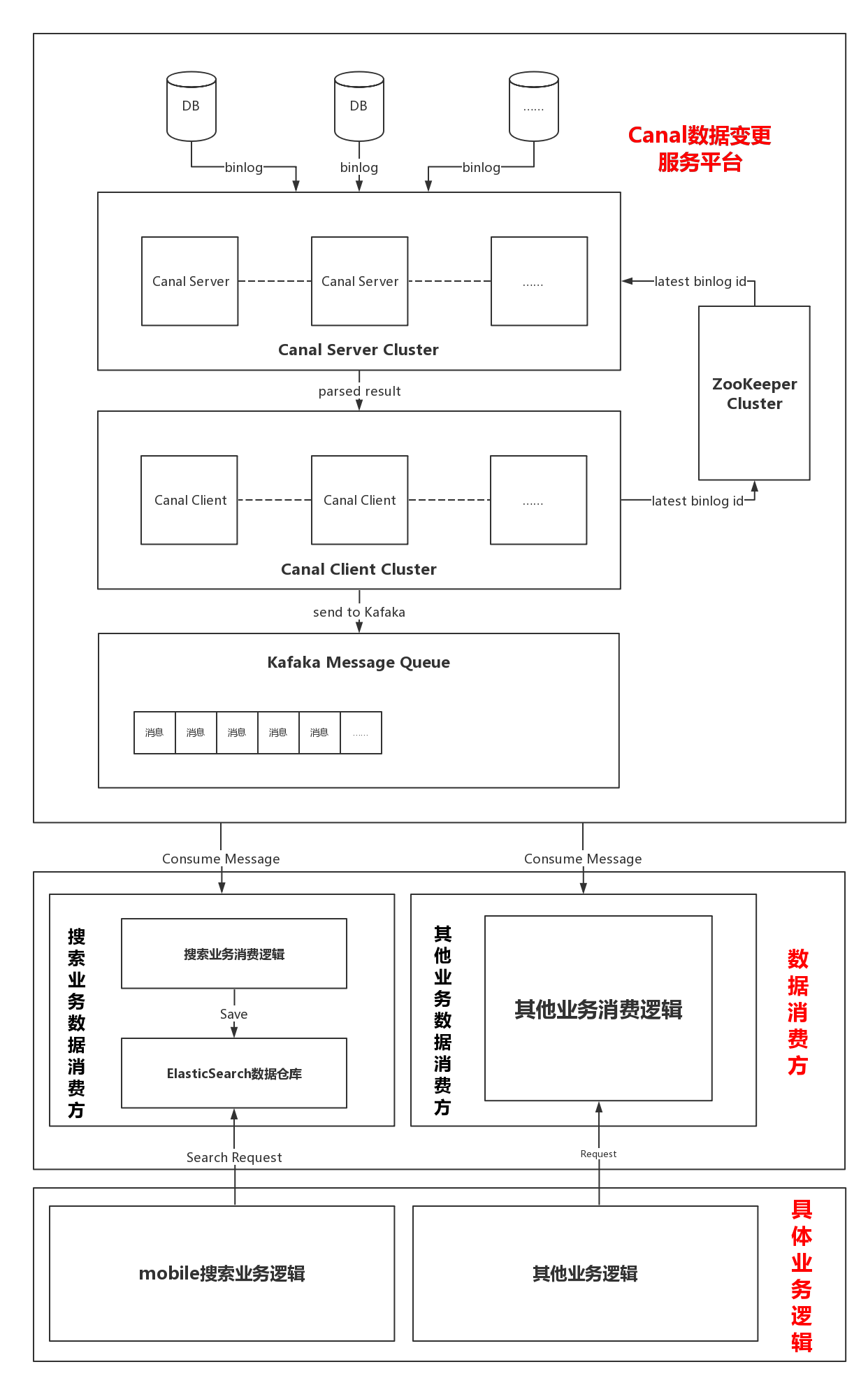
从架构图可以看出整个系统分为两大部分:
- Canal数据变更服务平台。这部分负责解析MySQL的binlog日志,并将其解析后的数据封装成特定的对象放到Kafka中。
- Kafka数据消费方。这部分负责消费存放在Kafka中的消息,当消费方拿到具体的用户表变更消息时,将最新的用户信息存放到ES数据仓库中。
Canal技术变更基础平台
因为考虑到未来可能有其他项目需要监控数据库某些表的变化,因此我们将Canal获取MySQL数据变更部分做成一个公用的平台。当有其他业务需要增加监控的表时,我们可以直接修改配置文件,重启服务器即可完成添加,极大地提高了开发效率。
在这一部分中,主要分为两大部分:Canal Server 和 Canal Client。
Canal Server端。Canal Server伪装成MySQL的一个从库,使主库发送binlog日志给 Canal Server,Canal Server 收到binlog消息之后进行解析,解析完成后将消息直接发送给Canal Client。在Canal Server端可以设置配置文件进行具体scheme(数据库)和table(数据库表)的筛选,从而实现动态地增加对数据库表的监视。
Canal Client端。Canal Client端接收到Canal Server的消息后直接将消息存到Kafka指定Partition中,并将最新的binlogid发送给zookeeper集群保存。
Kafka消息消费端
Canal技术变更平台在获取到对应的数据库变更消息后会将其放到指定的Kafka分片里,具体的业务项目需要到指定的Kafka片区里消费对应的数据变更消息,之后根据具体的业务需求进行处理。
因为Canal变化是根据表为最小单位进行地,因此我在实现方面定义了一个以表为处理单位的MsgDealer接口:
public interface MsgDealer {
void deal(CanalMsgVo canalMsgVo);
}搜索库涉及对5个表的监视,因此我实现了5个对应的处理类:
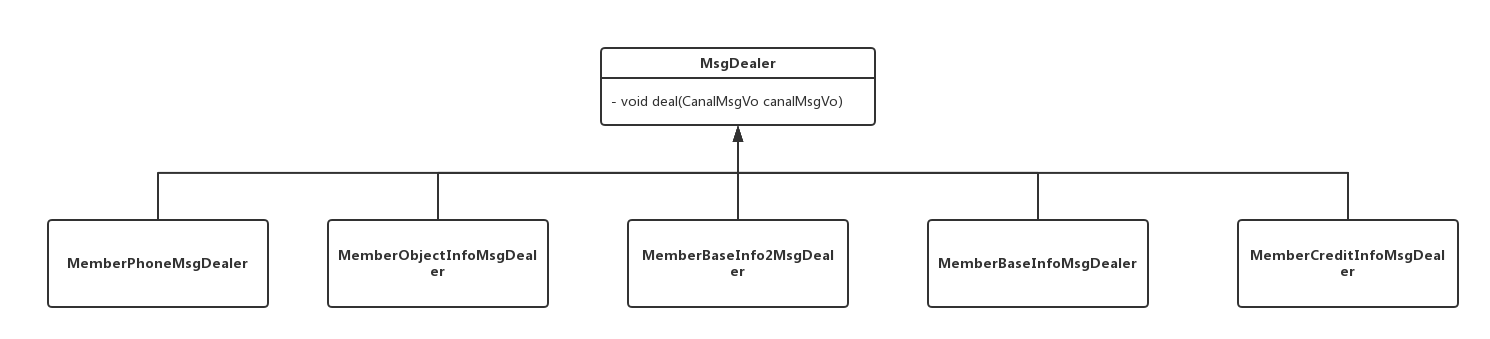
针对不同表的数据变化,自动调用不同的实现类进行处理。
ElasticSearch + Canal 开发千万级的实时搜索系统【转】的更多相关文章
- ElasticSearch + Canal 开发千万级的实时搜索系统
公司是做社交相关产品的,社交类产品对搜索功能需求要求就比较高,需要根据用户城市.用户ID昵称等进行搜索. 项目原先的搜索接口采用SQL查询的方式实现,数据库表采用了按城市分表的方式.但随着业务的发展, ...
- Twitter实时搜索系统EarlyBird
twitter要存档tweet采用lucene做全量指数,新发型是实时索引推文.检索实时(10在几秒钟内指数).实时索引和检索系统,称为EarlyBird. 感觉写更清晰,简洁,这个信息是真实的,只有 ...
- Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,elasticsearch安装配置及中文分词
http://fuxiaopang.gitbooks.io/learnelasticsearch/content/ (中文) 在Elasticsearch中,文档术语一种类型(type),各种各样的 ...
- 剖析Elasticsearch集群系列之三:近实时搜索、深层分页问题和搜索相关性权衡之道
转载:http://www.infoq.com/cn/articles/anatomy-of-an-elasticsearch-cluster-part03 近实时搜索 虽然Elasticsearch ...
- ElasticSearch做实时OLAP框架~实时搜索、统计和OLAP需求,甚至可以作为NOSQL来使用(转)
使用ElasticSearch作为大数据平台的实时OLAP框架 – lxw的大数据田地 http://lxw1234.com/archives/2015/12/588.htm 一直想找一个用于大数据平 ...
- 第十二章 Net 5.0 快速开发框架 YC.Boilerplate --千万级数据处理解决方案
在线文档:http://doc.yc-l.com/#/README 在线演示地址:http://yc.yc-l.com/#/login 源码github:https://github.com/linb ...
- Elasticsearch构建全文搜索系统
目录 前言 一.安装 1.安装elasticsearch 2.启动集群cluster 3.安装管理界面elasticsearch-head 4.安装分词插件elasticsearch-analysis ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 手机QQ公众号亿级消息实时群发架构
编者按:高可用架构分享及传播在架构领域具有典型意义的文章,本文由孙子荀分享.转载请注明来自高可用架构公众号 ArchNotes. 孙子荀,2009 年在华为从事内核和分布式系统的开发工作:2011 ...
随机推荐
- java-mybaits-00601-查询缓存-一级缓存、二级缓存
1.什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存. 一级缓存是SqlSession级别的缓存. 在操作数据库时需要构造 sql ...
- mysql监控优化(一)连接数和缓存
一.mysql的连接数 MYSQL数据库安装完成后,默认最大连接数是100,一般流量稍微大一点的论坛或网站这个连接数是远远不够的,连接数少的话,在大并发下连接数会不够用,会有很多线程在等待其他连接释放 ...
- Go实现查找目录下(包括子目录)替换文件内容
[功能] 按指定的目录查找出文件,如果有子目录,子目录也将进行搜索,将其中的文件内容进行替换. [缺陷] 1. 没有过滤出文本文件 2. 当文件过大时,效率不高 [代码] package main i ...
- WebBrowser自动填充打开文件对话框
WebBrowser自动填充打开文件对话框 在使用WebBrowser编写自动表单填写软件的时候,不知道大家是否遇到国填写文件选择表单的情况.遇到这种情况的时候,无法直接队Html元素赋值,必须模 ...
- java环境变量及Eclipse自动编译问题
环境变量,是在操作系统中一个具有特定名字的对象,它包含了一个或者多个应用程序所将使用到的信息.例如Windows和DOS操作系统中的path环境变量,当要求系统运行一个程序而没有告诉它程序所在的完整路 ...
- topcoder SRM712 Div1 LR
题目: Problem Statement We have a cyclic array A of length n. For each valid i, element i-1 the l ...
- ls命令输出的文件颜色
ls的输出颜色不止3种,有以下几种,白色:表示普通文件蓝色:表示目录绿色:表示可执行文件红色:表示压缩文件浅蓝色:链接文件红色闪烁:表示链接的文件有问题 黄色:表示设备文件 灰色:表示其他文件 这是l ...
- weblogic 清除缓存
清理缓存步骤如下: 1.前置条件:停止服务 2.找到下面3个目录,然后将里面的文件删除即可: ……/user_projects/domains/base_domain/servers/AdminSer ...
- Poi读取Excle报错 java.util.zip.ZipException: invalid stored block lengths
一:Poi读取Excle报错 java.util.zip.ZipException: invalid stored block lengths 系统中需要导出excle签收单,excle模板是预设好 ...
- Top-Down笔记 #01# 计算机网络概述
因特网 网络核心 分组交换网中的时延.丢包和吞吐量 协议层次及其服务模型 面对攻击的网络 计算机网络和因特网的历史 小结(自己写的...) [什么是因特网?] 具体构成描述 1.与因特网相连的设备被称 ...