sqlserver分区表索引
对于提高查询性能非常有效,因此,一般应该考虑应该考虑为分区表建立索引,为分区表建立索引与为普通表建立索引的语法一直,但是,其行为与普通索引有所差异。
默认情况下,分区表中创建的索引使用与分区表相同分区架构和分区列,这样,索引将于表对齐。将表与其索引对齐,可以使管理工作更容易进行,对于滑动窗口方案尤其如此。若要启动分区切换,表的所有索引都必须对齐。
尽管可以从已分区索引的基表中单独实现已分区索引,但通常的做法是 先设计一个已分区表,然后为该表创建索引。执行此操作时,SQL Server 将使用与该表相同的分区方案和分区依据列自动对索引进行分区。因此,索引的分区方式实质上与表的分区方式相同。这将使索引与表“对齐”。如果在创建时指定了不同的分区方案或单独的文件组来存储索引,则 SQL Server 不会将索引与表对齐。
对非唯一的聚集索引进行分区时,如果未在聚集键中明确指定分区依据列,默认情况下 SQL Server 将在聚集索引键列表中添加分区依据列。如果聚集索引是唯一的,则必须明确指定聚集索引键包含分区依据列。
对ylb_users根据group_id进行分区后聚集索引情况如下:
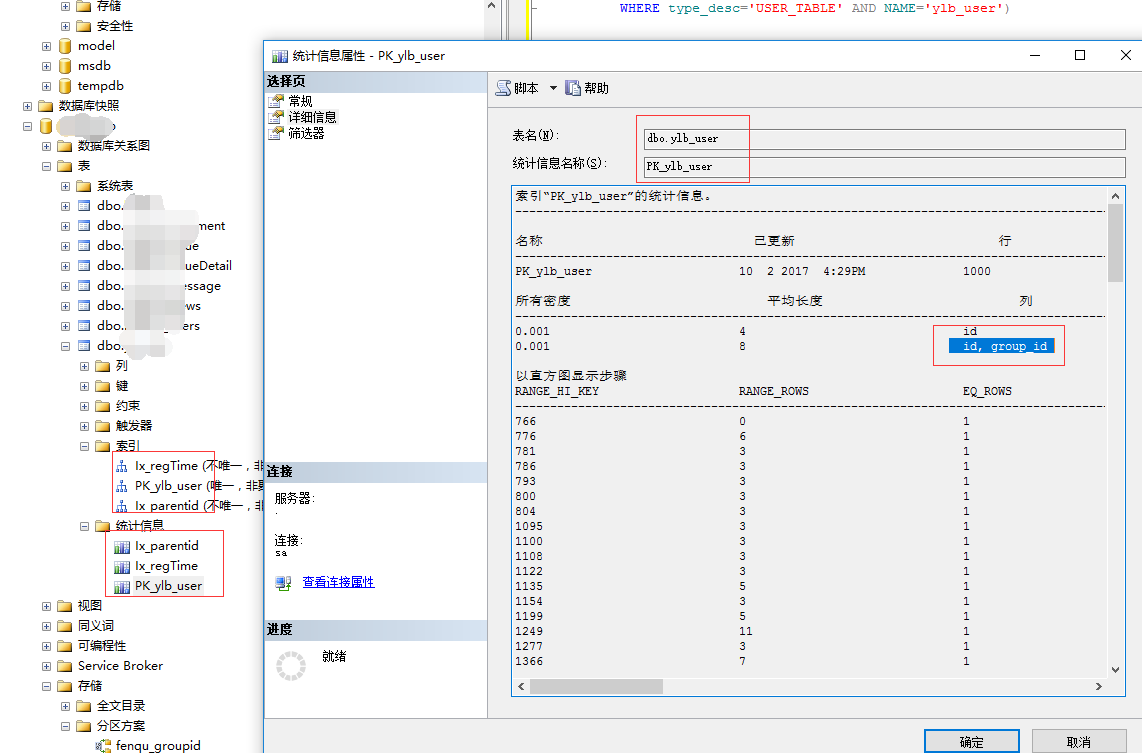
对唯一的非聚集索引进行分区时,索引键必须包含分区依据列。
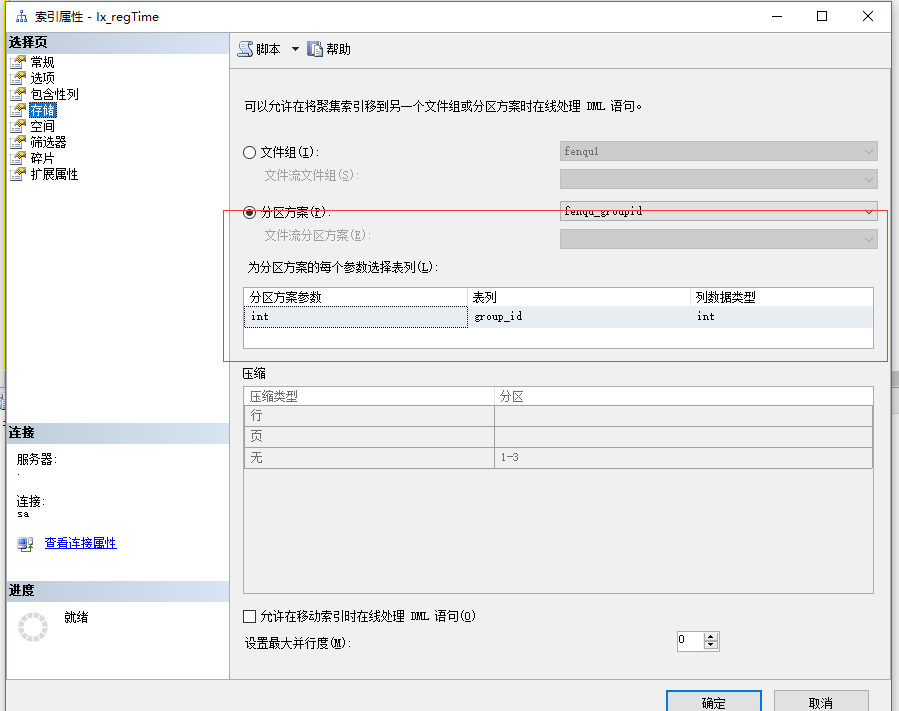
对非唯一的非聚集索引进行分区时,默认情况下 SQL Server 将分区依据列添加为索引的非键(包含性)列,以确保索引与基表对齐。如果索引中已经存在分区依据列,SQL Server 将不会向索引中添加分区依据列,若果索引没有对齐可对索引进行下图操作
sqlserver分区表索引的更多相关文章
- sqlserver分区表实践:对时间分区表自动进行管理
项目问题:有一张日志表,插入和查询为主,每天记录数据为200多万,大小为2G-4G之间.一开始开发人员使用delete语句手动删除,保留7天数据,经常造成阻塞和性能瓶颈.但是如果不删除数据随着表越来越 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- SqlServer分区表概述(转载)
什么是分区表 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在 ...
- sqlserver中索引优化
背景: MRO表中TimeStamp nvarchar(32),但实际上它存储的内容是日期(2015-09-09 11:20:30). 现在我要执行这样一个sql语句: Select t10.* fr ...
- (转)SQLServer分区表操作
原文地址:https://www.cnblogs.com/libingql/p/4087598.html 1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一 ...
- Oracle重新获取统计信息以及SQLSERVER重建索引
Oracle重新获取统计信息 exec dbms_stats.gather_schema_stats(ownname =>'LCoe739999',options => 'GATHER', ...
- SQLSERVER 分区表实战
背景:对NEWISS数据库创建分区表T_SALES的SQL.按照日期来进行分区步骤:1:创建文件组2:创建数据文件3:创建分区函数4:创建分区方案5:创建表及聚集索引6:导入测试数据(此处略),并查询 ...
- SQLserver查看索引使用情况
查索引使用情况: https://www.cnblogs.com/sunliyuan/p/6559354.html select db_name(database_id) as N'TOPK_T ...
随机推荐
- p2p通信原理及实现(转)
1.简介 当今互联网到处存在着一些中间件(MIddleBoxes),如NAT和防火墙,导致两个(不在同一内网)中的客户端无法直接通信.这些问题即便是到了IPV6时代也会存在,因为即使不需要NAT,但还 ...
- 【学习记录】二分查找的C++实现,代码逐步优化
二分查找的思想很简单,它是针对于有序数组的,相当于数组(设为int a[N])排成一颗二叉平衡树(左子节点<=父节点<=右子节点),然后从根节点(对应数组下标a[N/2])开始判断,若值& ...
- 你一定想知道的关于FPGA的那些事
首先,如果您从未接触过FPGA(现场可编程门阵列),或者有过一点基础想要继续深入了解这个行业,在这里,会向您介绍FPGA,并且向您解释FPGA都能解决什么问题,如何解决这些问题,并讨论如何将设计进行优 ...
- python 冒泡排序,二分法
a = 0 lst = [13,5,1,7,2,6,4,5,6] while a < len(lst): # 控制次数 for i in range(len(lst)-1): if lst[i] ...
- POJ 3279 Fliptile(反转 +二进制枚举)
Fliptile Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 13631 Accepted: 5027 Descrip ...
- error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory
编译出现如下错误: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such ...
- 【BZOJ】1833: [ZJOI2010] count 数字计数(数位dp)
题目 传送门:QWQ 分析 蒟蒻不会数位dp,又是现学的 用$ dp[i][j][k] $ 表示表示长度为i开头j的所有数字中k的个数 然后预处理出这个数组,再计算答案 代码 #include < ...
- socket链接循环
server------------------------#!/usr/bin/env python # encoding: utf-8 # Date: 2018/6/5 import socke ...
- [linux] ping服务器脚本
#!/bin/bash IP=1.2.3.4 while true; do echo "**********************************************" ...
- ubuntu下用expect实现密码自动输入
每次笔记本一开机启动,总会连用不着且碍事的触摸板也一块启动.便想写个脚本,让电脑启动时关闭触摸板.(当然,我想更好的办法是,修改系统启动时的加载模块,让触摸板不自动加载,但是目前还不知道用这种方法怎么 ...