[Python爬虫] 之二:Selenium 调用IEDriverServer打开IE浏览器安装配置
无论是selenium2(WebDriver)还是selenium2Library,如果想要调用ie浏览器,均需以下步骤。
下载IEDriverServer。进入索引页,首先选择版本号,IEDriverServer的版本号和Selenium的版本号一定要一致,因为我选择的是selenium-3.30,所以IEDriverServer也选择的是3.30版本的。打开后的页面如下所示:

解压缩得到IEDriverServer.exe,放在IE浏览器的安装目录且同级目录下,并将其所在目录添加到环境变量

针对windows vista和windows 7上的IE7或者更高的版本,必须在IE选项设置的安全页中,4个区域的启用保护模式的勾选都去掉(或都勾上),即保持四个区域的保护模式是一致的。如下图所示:
针对IE10和更高的版本,必须在IE选项设置中的高级页中,取消增强保护模式。如下图所示:
浏览器的缩放比例必须设置为100%,这样元素定位才不会出现问题,如下图所示:
针对IE11,需要修改注册表。如果是32位的windows,key值为



HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Internet
Explorer\Main\FeatureControl\FEATURE_BFCACHE
,如果是64位的windows,key值为
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Internet
Explorer\Main\FeatureControl\FEATURE_BFCACHE
如果key值不存在,就添加。之后在key内部创建一个iexplorer.exe,DWORD类型,值为0,我的windows是64位的,修改后的注册表如下图所示:

需要注意的是,修改注册表之后要重启机器,之后Selenium就可以正常打开ie浏览器。
如果浏览器还是不正常,要进行如下设置:
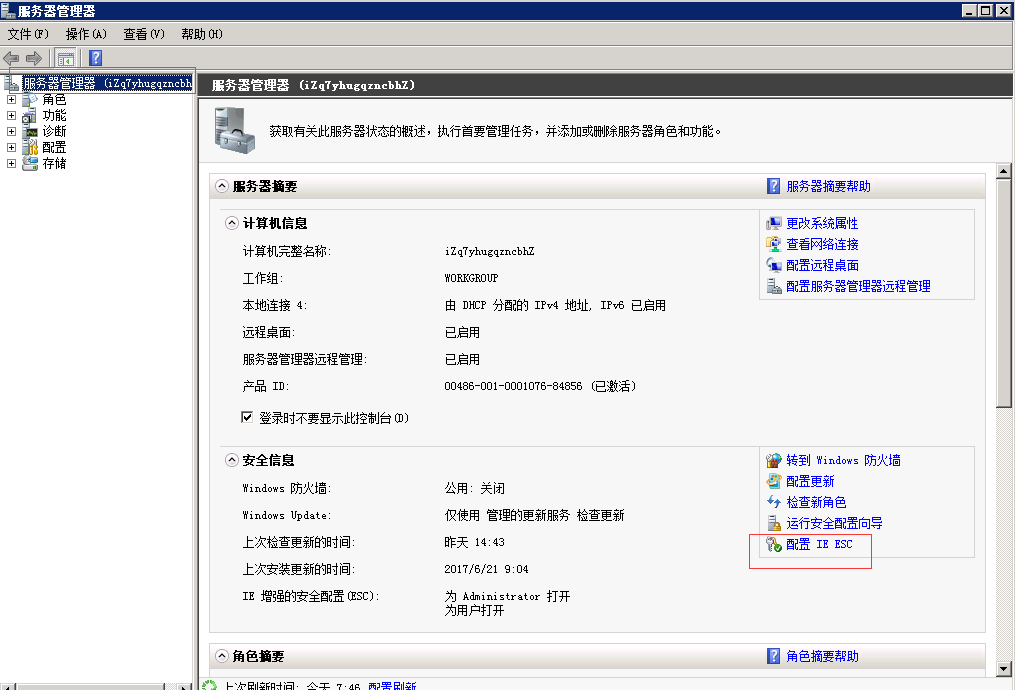

改为:
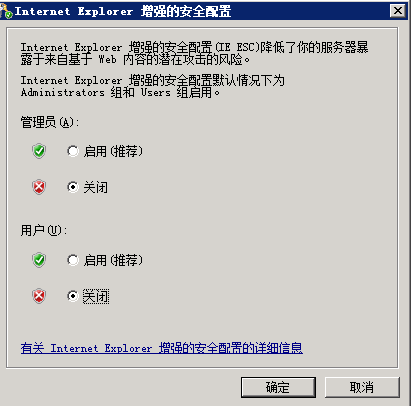
另外需要注意的时,如果进行上述设置后,下面的
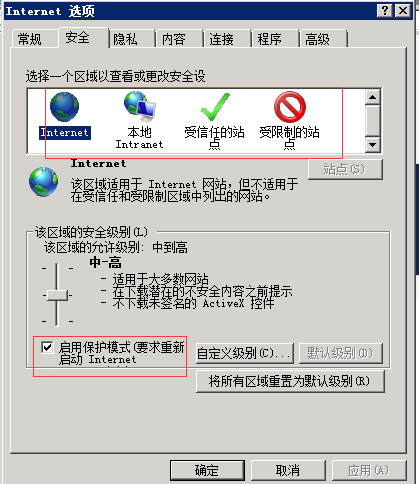
要重新设置一致,要么都选择,要都不选择。
[Python爬虫] 之二:Selenium 调用IEDriverServer打开IE浏览器安装配置的更多相关文章
- Selenium 调用IEDriverServer打开IE浏览器
Selenium 调用IEDriverServer打开IE浏览器 2016年03月30日 09:49:37 标签: selenium 14836 Selenium 调用IEDriverServer打开 ...
- [Python爬虫] 之三:Selenium 调用IEDriverServer 抓取数据
接着上一遍,在用Selenium+phantomjs 抓取数据过程中发现,有时候抓取不到,所以又测试了用Selenium+浏览器驱动的方式:具体代码如下: #coding=utf-8import os ...
- 3、Selenium调用IEDriverServer打开IE浏览器
学习Selenium时若想调用IE浏览器,均需要以下步骤 (1).http://selenium-release.storage.googleapis.com/index.html 下载IEDrive ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
随机推荐
- 使用fastadmin系统自带的图片上传plupload
首先,form表单需要具有如下代码 <form class="form-horizontal" role="form" method="POST ...
- python中对list去重的多种方法
今天遇到一个问题,用了 itertools.groupby 这个函数.不过这个东西最终还是没用上. 问题就是对一个list中的新闻id进行去重,去重之后要保证顺序不变. 直观方法 最简单的思路就是: ...
- 【BZOJ 3482】 3482: [COCI2013]hiperprostor (dij+凸包)
3482: [COCI2013]hiperprostor Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 277 Solved: 81 Descrip ...
- 【BZOJ 3307】 3307: 雨天的尾巴 (线段树+树链剖分)
3307: 雨天的尾巴 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 458 Solved: 210 Description N个点,形成一个树状结 ...
- Ubuntu 12.04下spark1.0.0 集群搭建(原创)
spark1.0.0新版本的于2014-05-30正式发布啦,新的spark版本带来了很多新的特性,提供了更好的API支持,spark1.0.0增加了Spark SQL组件,增强了标准库(ML.str ...
- SpringBoot 搭建简单聊天室
SpringBoot 搭建简单聊天室(queue 点对点) 1.引用 SpringBoot 搭建 WebSocket 链接 https://www.cnblogs.com/yi1036943655/p ...
- bzoj 1598: [Usaco2008 Mar]牛跑步 -- 第k短路,A*
1598: [Usaco2008 Mar]牛跑步 Time Limit: 10 Sec Memory Limit: 162 MB Description BESSIE准备用从牛棚跑到池塘的方法来锻炼 ...
- Linux下对拍程序
在程序对应文件夹下存为.sh文件 在终端命令中进入相应文件夹,用 sh XXX.sh 调用 while true; do ./datamaker>tmp.in ./baoli<tmp.in ...
- BSGS算法+逆元 POJ 2417 Discrete Logging
POJ 2417 Discrete Logging Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 4860 Accept ...
- 树形DP+(分组背包||二叉树,一般树,森林之间的转换)codevs 1378 选课
codevs 1378 选课 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description 学校实行学分制.每门的必修课都有固定的学分 ...