[Python爬虫] 之二:Selenium 调用IEDriverServer打开IE浏览器安装配置
无论是selenium2(WebDriver)还是selenium2Library,如果想要调用ie浏览器,均需以下步骤。
下载IEDriverServer。进入索引页,首先选择版本号,IEDriverServer的版本号和Selenium的版本号一定要一致,因为我选择的是selenium-3.30,所以IEDriverServer也选择的是3.30版本的。打开后的页面如下所示:

解压缩得到IEDriverServer.exe,放在IE浏览器的安装目录且同级目录下,并将其所在目录添加到环境变量

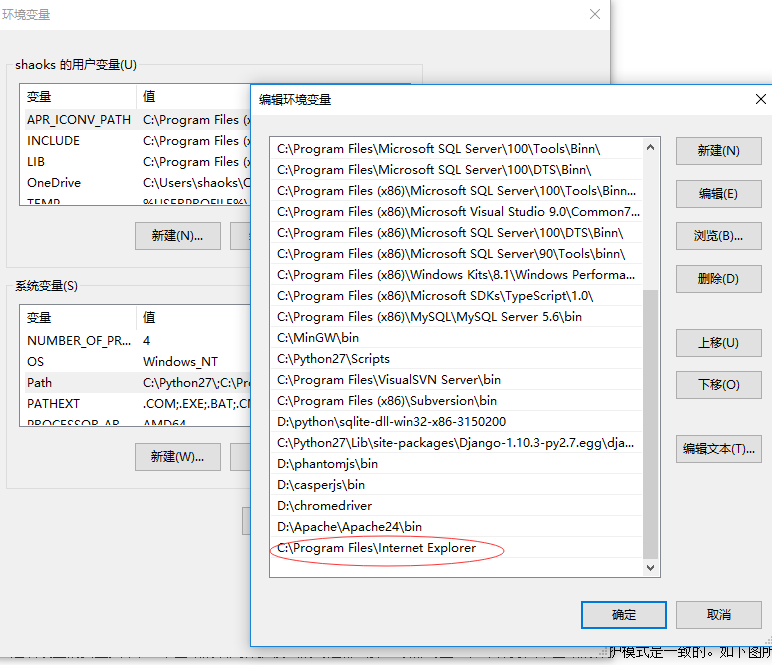
针对windows vista和windows 7上的IE7或者更高的版本,必须在IE选项设置的安全页中,4个区域的启用保护模式的勾选都去掉(或都勾上),即保持四个区域的保护模式是一致的。如下图所示:
针对IE10和更高的版本,必须在IE选项设置中的高级页中,取消增强保护模式。如下图所示:
浏览器的缩放比例必须设置为100%,这样元素定位才不会出现问题,如下图所示:
针对IE11,需要修改注册表。如果是32位的windows,key值为



HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Internet
Explorer\Main\FeatureControl\FEATURE_BFCACHE
,如果是64位的windows,key值为
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Internet
Explorer\Main\FeatureControl\FEATURE_BFCACHE
如果key值不存在,就添加。之后在key内部创建一个iexplorer.exe,DWORD类型,值为0,我的windows是64位的,修改后的注册表如下图所示:

需要注意的是,修改注册表之后要重启机器,之后Selenium就可以正常打开ie浏览器。
如果浏览器还是不正常,要进行如下设置:
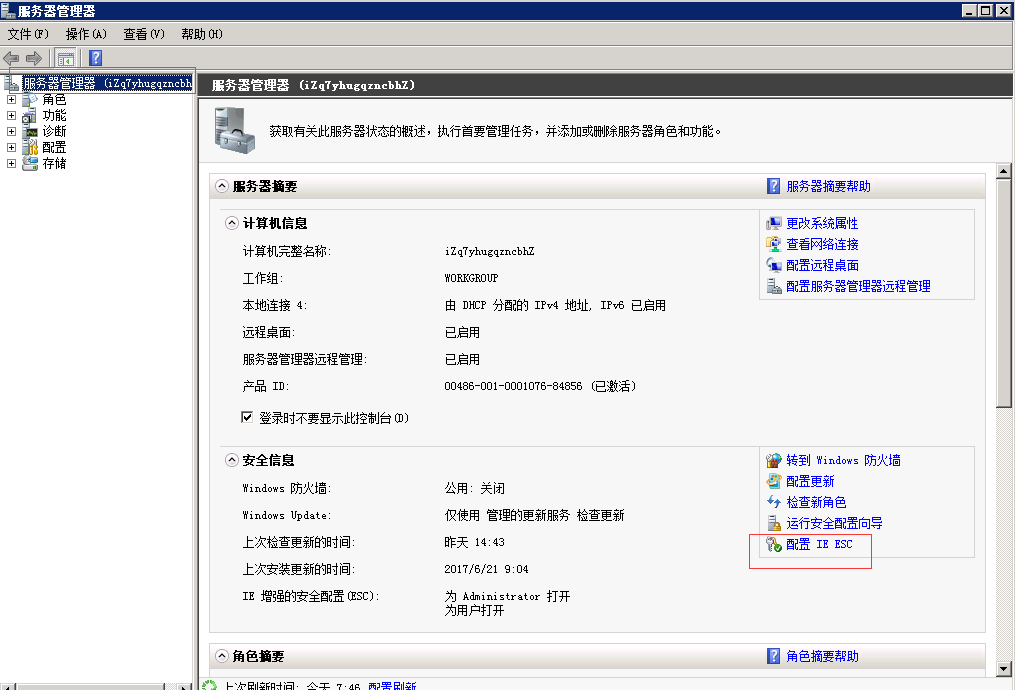

改为:
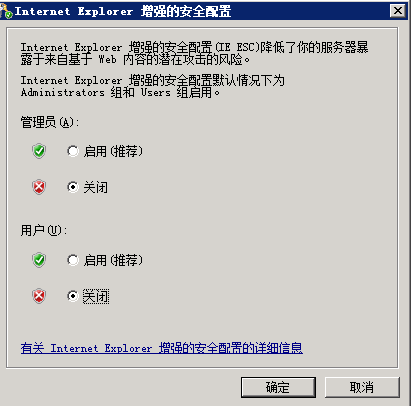
另外需要注意的时,如果进行上述设置后,下面的
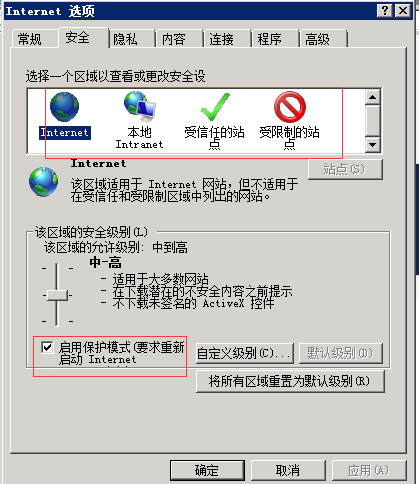
要重新设置一致,要么都选择,要都不选择。
[Python爬虫] 之二:Selenium 调用IEDriverServer打开IE浏览器安装配置的更多相关文章
- Selenium 调用IEDriverServer打开IE浏览器
Selenium 调用IEDriverServer打开IE浏览器 2016年03月30日 09:49:37 标签: selenium 14836 Selenium 调用IEDriverServer打开 ...
- [Python爬虫] 之三:Selenium 调用IEDriverServer 抓取数据
接着上一遍,在用Selenium+phantomjs 抓取数据过程中发现,有时候抓取不到,所以又测试了用Selenium+浏览器驱动的方式:具体代码如下: #coding=utf-8import os ...
- 3、Selenium调用IEDriverServer打开IE浏览器
学习Selenium时若想调用IE浏览器,均需要以下步骤 (1).http://selenium-release.storage.googleapis.com/index.html 下载IEDrive ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
随机推荐
- java总结(二)(运算符)
算数和赋值运算符 1.变量类型溢出时候,会直接取反:出现x>x+1 2.知道a++和++a 3.知道a/0错误 a/0.0无穷大 字符串 1.知道栈区.堆区和方法区 2.知道new String ...
- nodejs pm2配置使用教程
pm2是非常优秀工具,它提供对基于node.js的项目运行托管服务.它基于命令行界面,提供很多特性: 内置的负载均衡器等等,下面我们就一起来看看吧. 一.简介 pm2是一个带有负载均衡功能的应用进程管 ...
- git使用点滴:如何查看commit的内容
在push之前有时候会不放心是不是忘记加某些文件,或者是不是多删了个什么东西,这时候希望能够看看上次commit都做了些什么. 一开始想到的是用Git diff,但是git diff用于当前修改尚未c ...
- 洛谷P1404 平均数 [01分数规划,二分答案]
题目传送门 平均数 题目描述 给一个长度为n的数列,我们需要找出该数列的一个子串,使得子串平均数最大化,并且子串长度>=m. 输入输出格式 输入格式: N+1行, 第一行两个整数n和m 接下来n ...
- 什么是DQL、DML、DDL、DCL
SQL(Structure Query Language)语言是数据库的核心语言. SQL的发展是从1974年开始的,其发展过程如下: 1974年-----由Boyce和Chamberlin提出,当时 ...
- POJ1226 Substrings
后缀数组. 求多个字符串翻转与否中最长公共子串长. 二分答案,反过来多建一倍的字符串,二分时特判一下即可. By:大奕哥 #include<cstring> #include<cst ...
- NOIP2017 D1T2时间复杂度
这道题在考试时看到感觉与第一题放反了位置(因为我还没有看到第一题是结论题) 对于每个语句进行栈的模拟,而如果有语法错误就特判. 对于每一条for语句我们将其与栈顶元素连边,复杂度是1的我们不用考虑,如 ...
- POJ2185 Milking Grid KMP两次(二维KMP)较难
http://poj.org/problem?id=2185 大概算是我学KMP简单题以来最废脑子的KMP题目了 , 当然细节并不是那么多 , 还是码起来很舒服的 , 题目中描写的平铺是那种瓷砖一 ...
- Android开发AlertDialog解析
打开源码,首先映入眼帘的是三个构造方法,但这三个构造方法都是protected类型的, 可见,不允许我们直接实例化AlertDialog. 因此,我们再看别的有没有方法.可以实例化 再仔细一看,发现一 ...
- 修改npm仓库地址
在C:\Users\Administrator文件夹下找到.npmrc 添加registry = http://registry.cnpmjs.org淘宝镜像地址,保存