转:数据标准化/归一化normalization
转自:数据标准化/归一化normalization
这里主要讲连续型特征归一化的常用方法。离散参考[数据预处理:独热编码(One-Hot Encoding)]。
基础知识参考:
数据的标准化(normalization)和归一化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
归一化的目标
1 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
归一化后有两个好处
1. 提升模型的收敛速度
如下图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)
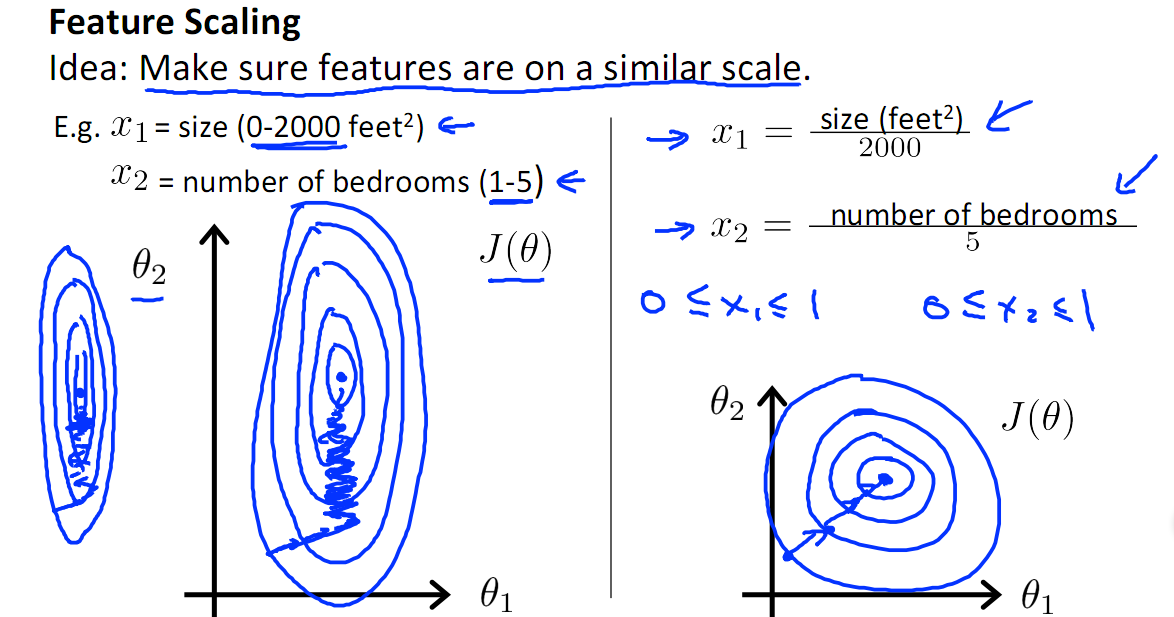
2.提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。

数据需要归一化的机器学习算法
需要归一化的模型:
有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM(距离分界面远的也拉近了,支持向量变多?)。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据dominate。
有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic
regression(因为θ的大小本来就自学习出不同的feature的重要性吧?)。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
不需要归一化的模型:
ICA好像不需要归一化(因为独立成分如果归一化了就不独立了?)。
基于平方损失的最小二乘法OLS不需要归一化。
常见的数据归一化方法
min-max标准化(Min-max normalization)/0-1标准化(0-1 normalization)
也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
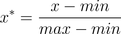
其中max为样本数据的最大值,min为样本数据的最小值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要将数据映射到[-1,1],则将公式换成:
x∗=x−xmeanxmax−xmin
x_mean表示数据的均值。
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:
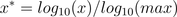
看了下网上很多介绍都是x*=log10(x),其实是有问题的,这个结果并非一定落到[0,1]区间上,应该还要除以log10(max),max为样本数据最大值,并且所有的数据都要大于等于1。
atan函数转换
用反正切函数也可以实现数据的归一化。
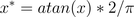
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上,而并非所有数据标准化的结果都映射到[0,1]区间上。
z-score 标准化(zero-mean normalization)
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。
也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
x∗=x−μσ
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
标准化的公式很简单,步骤如下
1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ;
2.进行标准化处理:
zij=(xij-xi)/si
其中:zij为标准化后的变量值;xij为实际变量值。
3.将逆指标前的正负号对调。
标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
def z_score(x, axis):
x = np.array(x).astype(float)
xr = np.rollaxis(x, axis=axis)
xr -= np.mean(x, axis=axis)
xr /= np.std(x, axis=axis)
# print(x)
return x
为什么z-score 标准化后的数据标准差为1?
x-μ只改变均值,标准差不变,所以均值变为0
(x-μ)/σ只会使标准差除以σ倍,所以标准差变为1

Decimal scaling小数定标标准化
这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性A的取值中的最大绝对值。
将属性A的原始值x使用decimal scaling标准化到x'的计算方法是:
x'=x/(10^j)
其中,j是满足条件的最小整数。
例如 假定A的值由-986到917,A的最大绝对值为986,为使用小数定标标准化,我们用每个值除以1000(即,j=3),这样,-986被规范化为-0.986。
注意,标准化会对原始数据做出改变,因此需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。
Logistic/Softmax变换
logistic函数和标准正态函数
新数据=1/(1+e^(-原数据))
这个函数的作用就是使得P(i)在负无穷到0的区间趋向于0,在0到正无穷的区间趋向于1。同样,函数(包括下面的softmax)加入了e的幂函数正是为了两极化:正样本的结果将趋近于1,而负样本的结果趋近于0。这样为多类别分类提供了方便(可以把P(i)看作是样本属于类别i的概率)。


Note:
上半部分图形显示了概率P随着自变量变化而变化的情况,下半部分图形显示了这种变化的速度的变化。可以看得出来,概率P与自变量仍然存在或多或少的线性关系,主要是在头尾两端被连接函数扭曲了,从而实现了[0,1]限制。同时,自变量取值靠近中间的时候,概率P变化比较快,自变量取值靠近两端的时候,概率P基本不再变化。这就跟我们的直观理解相符合了,似乎是某种边际效用递减的特点。
[logistic回归的一些直观理解(1.连接函数 logit probit)]
Softmax函数
是logistic函数的一种泛化,Softmax是一种形如下式的函数:
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是
也就是说,是该元素的指数,与所有元素指数和的比值
为什么要取指数,第一个原因是要模拟 max 的行为,所以要让大的更大。第二个原因是需要一个可导的函数。
通过softmax函数,可以使得P(i)的范围在[0,1]之间。在回归和分类问题中,通常θ是待求参数,通过寻找使得P(i)最大的θi作为最佳参数。
此外Softmax函数同样可用于非线性估计,此时参数θ可根据现实意义使用其他列向量替代。
Softmax函数得到的是一个[0,1]之间的值,且∑Kk=1P(i)=1,这个softmax求出的概率就是真正的概率,换句话说,这个概率等于期望。
[Machine Learning - VI. Logistic Regression逻辑回归 (Week 3)]
模糊量化模式
新数据=1/2+1/2sin[派3.1415/(极大值-极小值)*(X-(极大值-极小值)/2) ] X为原数据
数据标准化/归一化的编程实现
Python库实现和调用
[Scikit-learn:数据预处理Preprocessing data ]
from: http://blog.csdn.net/pipisorry/article/details/52247379
ref:
转:数据标准化/归一化normalization的更多相关文章
- 数据标准化/归一化normalization
http://blog.csdn.net/pipisorry/article/details/52247379 基础知识参考: [均值.方差与协方差矩阵] [矩阵论:向量范数和矩阵范数] 数据的标准化 ...
- NumPy数据的归一化
数据的归一化 首先我们来看看归一化的概念: 数据的标准化(normalization)和归一化 数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.在某些比较和评价 ...
- 数据标准化 Normalization
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能 ...
- Python数据预处理—归一化,标准化,正则化
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常用的 ...
- Batch Normalization的算法本质是在网络每一层的输入前增加一层BN层(也即归一化层),对数据进行归一化处理,然后再进入网络下一层,但是BN并不是简单的对数据进行求归一化,而是引入了两个参数λ和β去进行数据重构
Batch Normalization Batch Normalization是深度学习领域在2015年非常热门的一个算法,许多网络应用该方法进行训练,并且取得了非常好的效果. 众所周知,深度学习是应 ...
- 数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化 导包和数据 import numpy as np from sklearn import preprocessing data = np.loadtxt('data.t ...
- 数据标准化方法及其Python代码实现
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法.标准差法).折线型方法(如三折线法).曲线型方法 ...
- pandas学习(四)--数据的归一化
欢迎加入python学习交流群 667279387 Pandas学习(一)–数据的导入 pandas学习(二)–双色球数据分析 pandas学习(三)–NAB球员薪资分析 pandas学习(四)–数据 ...
- R实战 第九篇:数据标准化
数据标准化处理是数据分析的一项基础工作,不同评价指标往往具有不同的量纲,数据之间的差别可能很大,不进行处理会影响到数据分析的结果.为了消除指标之间的量纲和取值范围差异对数据分析结果的影响,需要对数据进 ...
随机推荐
- 欢迎来怼---作业要求 20171015 beta冲刺贡献分分配规则
一.小组信息 队名:欢迎来怼 小组成员 队长:田继平 成员:李圆圆,葛美义,王伟东,姜珊,邵朔,阚博文 基础分 每人占个人总分的百分之40% leangoo里面的得分 每人占个人总分里 ...
- 定制自己的动画 View 控件(Canvas 使用)
定制自己的动画 View 控件(Canvas 使用) 如果要定义自己的 View 控件,则需要新建一个类继承 android.view.View.然后在 onDraw 中写自己需要实现的方式. 这里定 ...
- 第一次C++作业
电梯调度问题,PTA作业 ... 电梯调度问题 [github]https://github.com/zhanglingxin/elevator-scheduling 在本次代码中我第一次使用C++的 ...
- 软工1816·Alpha冲刺(10/10)
团队信息 队名:爸爸饿了 组长博客:here 作业博客:here 组员情况 组员1(组长):王彬 过去两天完成了哪些任务 协助完成前端各个页面的整合 协助解决前端操作逻辑存在的问题 完成前端的美化,使 ...
- Web站点性能-微观手段
文章:网站性能优化 百度百科:高性能Web站点 文章:构建高性能WEB站点之 吞吐率.吞吐量.TPS.性能测试
- dubbo源码分析1——负载均衡
dubbo中涉及到的负载均衡算法只要有四种:Random LoadBalance(随机均衡算法).RoundRobin LoadBalance(权重轮循均衡算法).LeastAction LoadBa ...
- MiniOS系统
实验一 命令解释程序的编写 一.目的和要求 1. 实验目的 (1)掌握命令解释程序的原理: (2)*掌握简单的DOS调用方法: (3)掌握C语言编程初步. 2.实验要求 编写类似于DOS,UNIX的 ...
- windows平台下nginx+PHP环境安装
因为日常工作在windows下,为方便在window是下进行PHP开发,需要在windows平台下搭建PHP开发环境,web服务器选择nginx,不过windows版本的nginx性能要比Linux/ ...
- 成功解决JSP和Servlet的中文乱码问题
表单提交时出现乱码: 在进行表单提交的时候,经常提交一些中文,自然就避免不了出现中文乱码的情况,对于表单来说有两种提交方式:get和post提交方式.所以请求的时候便有get请求和post请求.以前我 ...
- 【vim】vim常用命令
移动: h 或 向左箭头键(←) #光标向左移劢一个字符 j 或 下箭头键(↓) #光标向下移劢一个字符 k 或 向上箭头键(↑) #光标向上移劢一个字符 l 或 向右箭头键(→) ...