Ubuntu 16.04上搭建CDH5.16.1集群
本文参考自:《Ubuntu16.04上搭建CDH5.14集群》
1.准备三台(CDH默认配置为三台)安装Ubuntu 16.04.4 LTS系统的服务器,假设ip地址分布为
192.168.100.19
192.168.100.20
192.168.100.21
(如果是虚拟机,建议内存配置为8G或以上,否则会导致各种启动运行失败。)
2.所有的操作都在root下进行,所以首先需要设置ssh可以使用root登录(如果已经是root登录则跳过)
①设置root的登录密码
sudo passwd root
②切换到root用户
sudo su root
③设置登录账户可以使用root
vi /etc/ssh/sshd_config
#PermitRootLogin prohibit-password #屏蔽这一行
PermitRootLogin yes #增加这一行
④更新软件列表并检查是否联网状态
apt-get update
3.关闭防火墙
ufw disable
4.设置三台机器的hostname和hosts
①设置hostname:
vi /etc/hostname
192.168.100.19对应设置为hadoop-master
192.168.100.20对应设置为hadoop-slave1
192.168.100.21对应设置为hadoop-slave2
②修改hosts
vi /etc/hosts
127.0.0.1 localhost
#127.0.1.1 test1 #屏蔽这一行 #新增下面三行
192.168.100.19 hadoop-master
192.168.100.20 hadoop-slave1
192.168.100.21 hadoop-slave2
③使用ping命令,查看以上设置是否正确
ping hadoop-master
ping hadoop-slave1
ping hadoop-slave2
④重启后用root登录
5.让三台服务器之间互相可以使用root无需输入密码进行ssh登录。
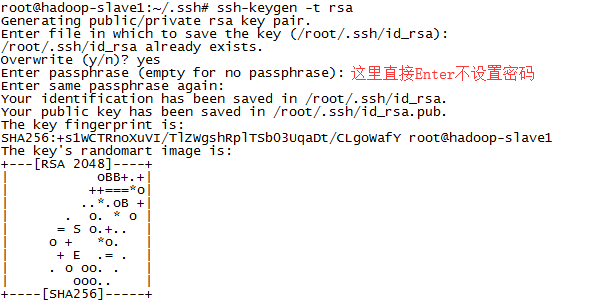
①生成公钥(不要设置密码)
ssh-keygen -t rsa
截图如下:
②将本机的公钥复制到另外两台服务器上。(过程需要输入目标服务器的root登录密码)
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop-master #在slave1和slave2上执行
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop-slave1 #在master和slave2上执行
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop-slave2 #在master和slave1上执行
③测试是否成功
ssh hadoop-master #无密码远程登录hadoop-master,使用exit退出
ssh hadoop-slave1 #无密码远程登录hadoop-slave1,使用exit退出
ssh hadoop-slave2 #无密码远程登录hadoop-slave2,使用exit退出
④如果出现下面的报错
ssh:connect to host hadoop-slave1 port 22: Connection refused
ssh: connect to host hadoop-slave1 port 22: Connection timed out
检查root的密码是否正确,可以使用ssh localhost检查一下是否可以登录到本机,如果不行则证明root密码有问题,转到上面第2个步骤重新设置root密码。
检查/etc/hosts文件中ip和hostname是否正确
检查防火墙是否关闭
6.安装JAVA运行环境
①正常显示版本号则跳过下面步骤
java -version
②如果显示如下,则表示还没有安装JAVA

③具体JDK的安装可以参考
7.安装JAVA的MySQL软件包
apt-get install libmysql-java
8.只在hadoop-master中安装MySQL(过程需要输入MySQL的登录密码)
①安装MySQL
apt-get install mysql-server mysql-client
②测试是否安装成功
mysql -uroot -p
③创建对应的库以及用户
create database hive DEFAULT CHARSET utf8;
create database rman DEFAULT CHARSET utf8;
create database oozie DEFAULT CHARSET utf8;
create database hue DEFAULT CHARSET utf8; grant all on hive.* TO 'hive'@'%' IDENTIFIED BY '';
grant all on rman.* TO 'rman'@'%' IDENTIFIED BY '';
grant all on oozie.* TO 'oozie'@'%' IDENTIFIED BY '';
grant all on hue.* TO 'hue'@'%' IDENTIFIED BY '';
④成功后退出MySQL
quit
9.只在hadoop-master下载CDH相关文件(由于版本的更新,版本号会不断递增),并进行设置
①在浏览器中输入 http://archive.cloudera.com/cm5/cm/5/ 查看到ubuntu对应最新版本

②在浏览器中输入 http://archive.cloudera.com/cdh5/parcels/latest 查看到ubuntu对应最新版本

③将上面的四个文件都下载下来
wget -c http://archive.cloudera.com/cm5/cm/5/cloudera-manager-xenial-cm5.16.1_amd64.tar.gz
wget -c http://archive.cloudera.com/cdh5/parcels/latest/CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel
wget -c http://archive.cloudera.com/cdh5/parcels/latest/CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha1
wget -c http://archive.cloudera.com/cdh5/parcels/latest/manifest.json
④将CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha1文件重命名为CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha
mv CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha1 CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha
⑤在/opt中建立对应的文件夹结构(cm-5.16.1为当前版本号)
| --/opt
|--/cloudera
|--/parcels
|--/parcel-repo
|--/cm-5.16.1
cd /opt
mkdir cm-5.16.
mkdir cloudera
cd cloudera
mkdir parcels
mkdir parcel-repo
⑥将CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel、CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha和manifest.json三个文件拷贝到/opt/cloudera/parcel-repo中
cp CDH-5.16.-.cdh5.16.1.p0.3-xenial.parcel CDH-5.16.-.cdh5.16.1.p0.3-xenial.parcel.sha manifest.json /opt/cloudera/parcel-repo
⑦解压cloudera-manager-xenial-cm5.16.1_amd64.tar.gz到/opt中
tar -zxf cloudera-manager-xenial-cm5..1_amd64.tar.gz -C /opt
⑧链接mysql连接库到cm
ln -s /usr/share/java/mysql-connector-java.jar /opt/cm-5.16./share/cmf/lib/mysql-connector-java.jar
⑨配置cm5的数据库
cd /opt/cm-5.16./share/cmf/schema
./scm_prepare_database.sh mysql -uroot -p你的MySQL密码 scm scm scm --force
⑩修改配置文件
vi /opt/cm-5.16./etc/cloudera-scm-agent/config.ini
# Hostname of the CM server.
server_host=hadoop-master #修改为主机名
⑪将cm-5.16.1复制到另外两个节点
scp -r /opt/cm-5.16. hadoop-slave1:/opt/
scp -r /opt/cm-5.16. hadoop-slave2:/opt/
10.在所有节点启动Server和Agent(务必先执行后面所有红色操作重启系统!!!再启动进程,避免出现错误再处理的反复折腾)
①启动进程
cd /opt/cm-5.16./etc/init.d
./cloudera-scm-server start
./cloudera-scm-agent start
②如果报错 install: invalid user ‘cloudera-scm’,则增加一个用户
useradd --system --home=/opt/cm-5.16.1/run/cloudera-scm-server --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
③如果还报错 Starting cloudera-scm-server: * Couldn't start cloudera-scm-server
则看log详细报错信息进行对应处理
cd /opt/cm-5.16./log/cloudera-scm-server
cat cloudera-scm-server.out #server报错
cd /opt/cm-5.16.1/log/cloudera-scm-agen
cat cloudera-scm-agent.out #agent报错
比如agent的错误提示 /usr/bin/env: ‘python2.7’: No such file or directory 表示需要安装python2.7
apt-get install python2.7
11.稍等一下(时间比较长,耐心等待),在浏览器中输入 http://192.168.100.19:7180/cmf/login,并输入用户名和密码(默认都是admin)
12.同意End User License Terms and Conditions
13.选择试用版
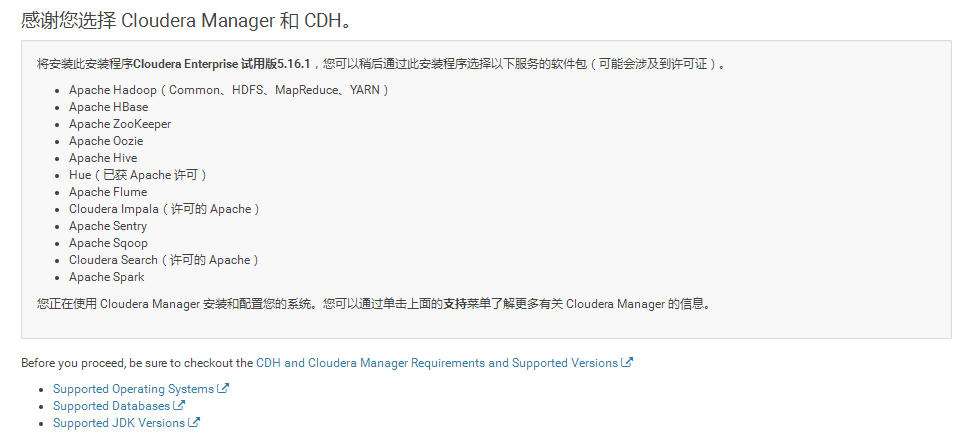
14.感谢选择CM和CDH
15.选择所有主机安装CDH集群

16.选择集群安装的方法和版本,其它选择默认的None

17.等待三个节点安装完毕(一开始会是红色,慢慢安装完成后变绿色)

18.监测集群中三个节点的状态

这里需要设置vm.swappiness=10(设置完成后需要重启才生效,可以进行后面处理后再进行重启)
vi /etc/sysctl.conf
vm.swappiness=10 #在文件最后增加一行
cat /proc/sys/vm/swappiness #查看当前值
19.根据需要安装对应的组件或者全部安装
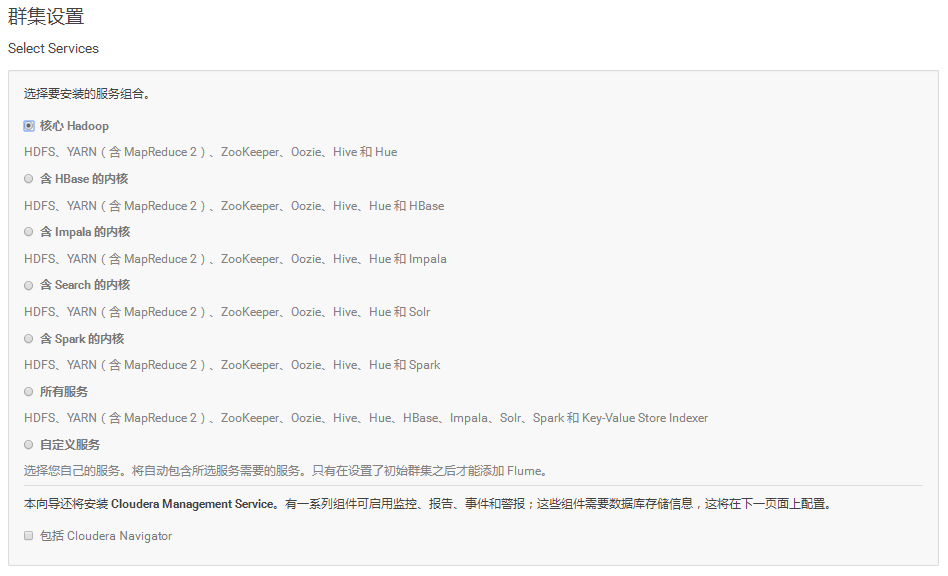
20.按需选择DataNode的节点和其它配置

21.依次输入表名、用户名和密码(和8③中保持一致),测试连接一切正常。
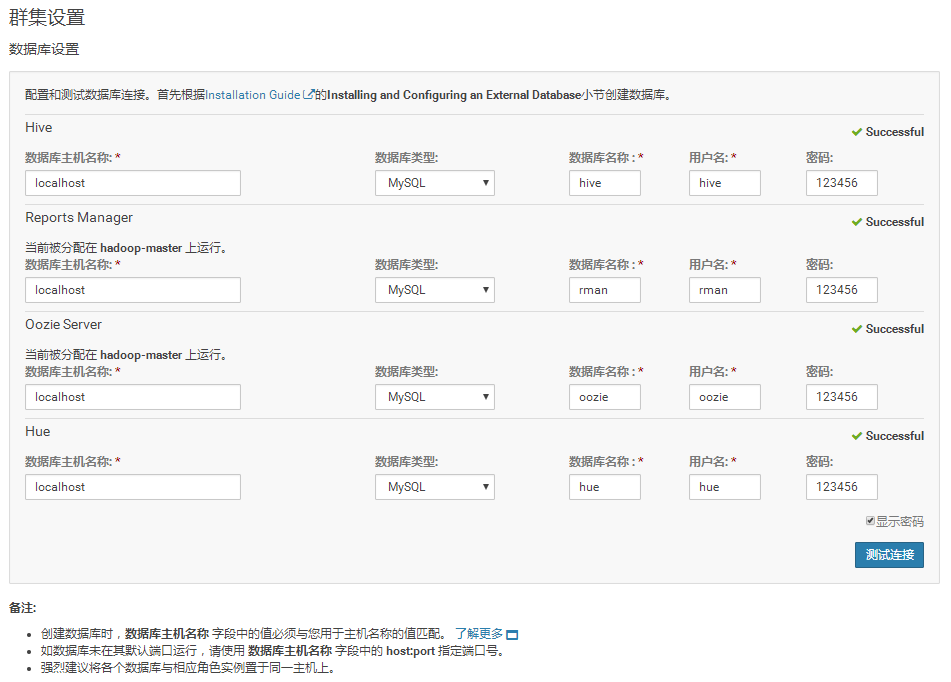
①错误1 : No database server found running on host hadoop-master.

解决办法:将hadoop-master修改为localhost
②错误2:Unexpected error.Unable to verify database connection.

解决办法:进入log里面查找原因
cd /opt/cm-5.16./log/cloudera-scm-server
tail cloudera-scm-server.log -n
③找到第一个Error:缺少了对应的mysqlclient库
Error loading MySQLdb module: libmysqlclient.so.20: cannot open shared object file: No such file or directory
对应的解决办法:
apt-cache search libmysql
apt-get install libmysql++-dev
④找到第二个Error:缺少对应的python库
Error: libxslt.so.1: cannot open shared object file: No such file or directory
对应的解决办法:缺少python的库
apt-get install python-libxslt1
22.集群配置的复核界面,保持默认值或者根据具体需求进行配置
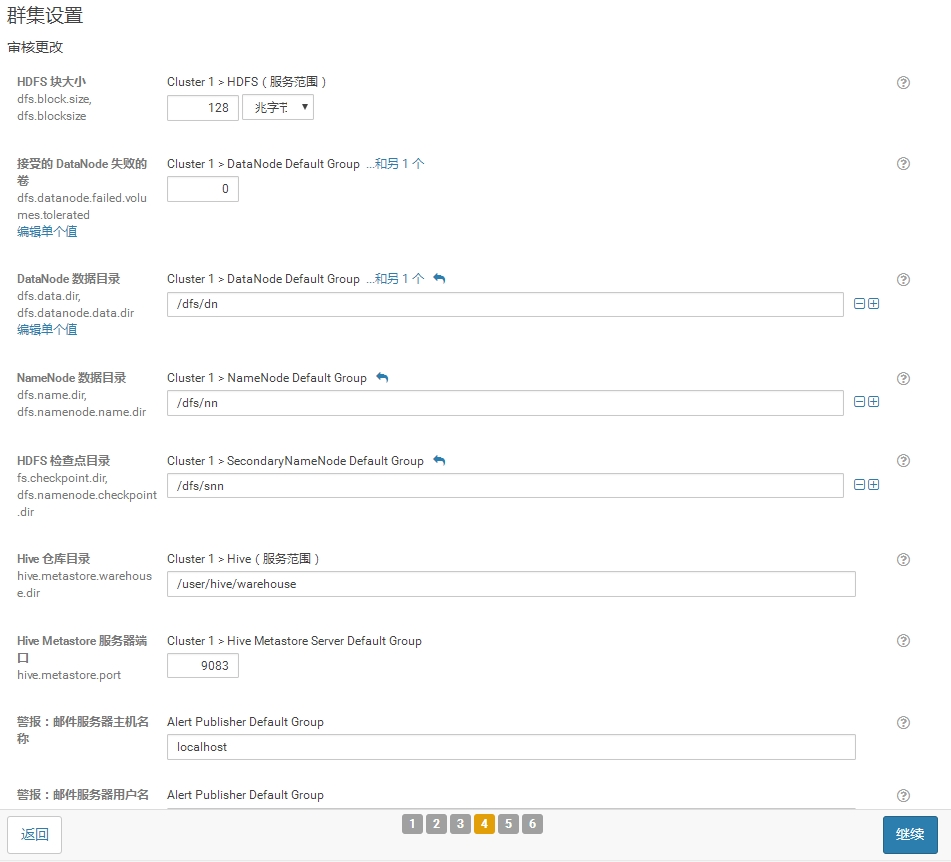
23.开始运行集群配置
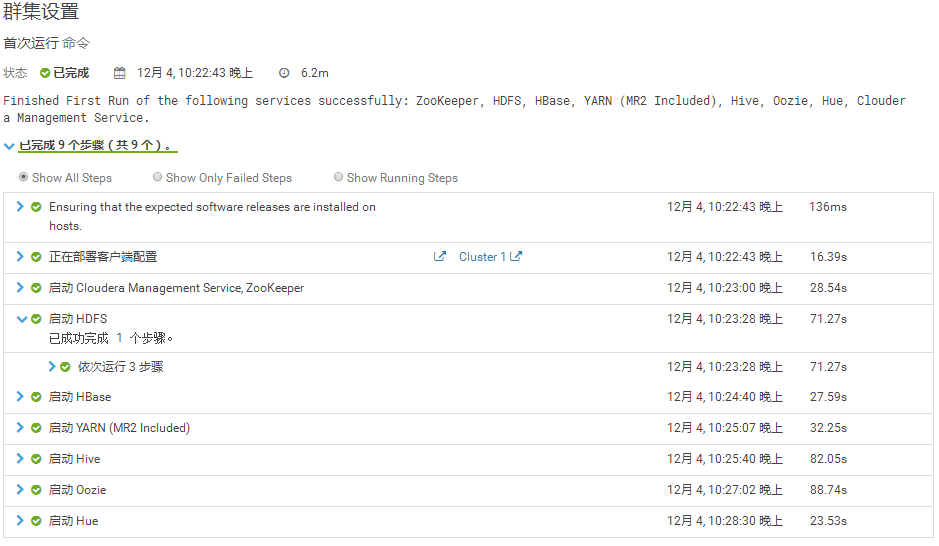
报错:Error: JAVA_HOME is not set and could not be found.
解决办法:所有三个节点都重新设置JAVA的快链位置(下面的例子将/usr/local/java快捷方式到/usr/java)
mkdir /usr/java
ln -s /usr/local/java /usr/java/default
24.恭喜完成!

25.如果有安装了Hive和Hue服务的话,可以使用http://192.168.100.19:8888进行访问。

以上。
Ubuntu 16.04上搭建CDH5.16.1集群的更多相关文章
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- Ubuntu16.04.1上搭建分布式的Redis集群
为什么要集群: 通常为了,提高网站的响应速度,总是把一些经常用到的数据放到内存中,而不是放到数据库中,Redis是一个很好的Cache工具,当然了还有Memcached,这里只讲Redis.在我们的电 ...
- Ubuntu16.04.1上搭建分布式的Redis集群,并使用C#操作
为什么要集群: 通常为了,提高网站的响应速度,总是把一些经常用到的数据放到内存中,而不是放到数据库中,Redis是一个很好的Cache工具,当然了还有Memcached,这里只讲Redis.在我们的电 ...
- Ubuntu 16.04下使用docker部署ceph集群
ceph集群docker部署 通过docker可以快速部署小规模Ceph集群的流程,可用于开发测试. 以下的安装流程是通过linux shell来执行的:假设你只有一台机器,装了linux(如Ubun ...
- Linux上搭建Hadoop2.6.3集群以及WIN7通过Eclipse开发MapReduce的demo
近期为了分析国内航空旅游业常见安全漏洞,想到了用大数据来分析,其实数据也不大,只是生产项目没有使用Hadoop,因此这里实际使用一次. 先看一下通过hadoop分析后的结果吧,最终通过hadoop分析 ...
- 使用kubeadm在CentOS上搭建Kubernetes1.14.3集群
练习环境说明:参考1 参考2 主机名称 IP地址 部署软件 备注 M-kube12 192.168.10.12 master+etcd+docker+keepalived+haproxy master ...
- CentOS6.4上搭建hadoop-2.4.0集群
公司Commerce Cloud平台上提供申请主机的服务.昨天试了下,申请了3台机器,搭了个hadoop环境.以下是机器的一些配置: emi-centos-6.4-x86_64medium | 6GB ...
- 在 Linux 服务器上搭建和配置 Hadoop 集群
实验条件:3台centos服务器,jdk版本1.8.0,Hadoop 版本2.8.0 注:hadoop安装和搭建过程中都是在用户lb的home目录下,master的主机名为host98,slave的主 ...
- Ubuntu 18.04上搭建FTP服务器
1.准备工作需要安装并运行的Ubuntu Server 18.04系统.当然还需要一个具有sudo权限的账号. 2.安装VSFTPVSFTP程序位于标准存储库中,因此可以使用单个命令删除安装.打开终端 ...
随机推荐
- 目标检测(四)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun SPPnet.Fast R-CNN等目标检测算法已经大幅降低了目标检测网络的运行时间. ...
- Unable to convert MySQL date/time value to System.DateTime问题解决方案
原因:可能是该字段(date/datetime)的值默认缺省值为:0000-00-00/0000-00-00 00:00:00,这样的数据读出来转换成System.DateTime时就会有问题: 解决 ...
- linux出现tmp空间满的情况解决
cd命令tab补全的时候报错: cd /ro-bash: cannot create temp file for here-document: No space left on device-bash ...
- 原生ajax函数封装
原生ajax函数 function ajax(json){ json=json || {}; if(!json.url){ return; } json.data=json.data || {}; j ...
- CookieUitl
import javax.servlet.http.Cookie;import javax.servlet.http.HttpServletRequest;import javax.servlet.h ...
- Python类中的__init__() 和 self 的解析
原文地址https://www.cnblogs.com/ant-colonies/p/6718388.html 1.Python中self的含义 self,英文单词意思很明显,表示自己,本身. 此处有 ...
- [ Python ] KMP Algorithms
def pmt(s): """ :param s: the string to get its partial match table :return: partial ...
- 基于注解的Spring事务配置
spring采用@Transactional注解进行事务申明,@Transactional既可以在方法上申明,也可以在类上申明,方法申明优先于类申明. 1.pom配置 包括spring核心包引入以及s ...
- FangDD Java编程规范
我们采用<Oracle/Sun原生的Java编程规范>和<Google Java编程规范> Google Java编程风格指南 January 20, 2014 作者:Haws ...
- List 循环删除 指定元素的 方法
使用Iterator进行循环,在删除指定元素.如果使用for 或 foreach 在删除指定下标是,list.size 会相应的缩短且下标前移,导致相邻满足条件的元素未删除 Iterator<S ...