elasticsearch7.5.0+kibana-7.5.0+cerebro-0.8.5集群生产环境安装配置及通过elasticsearch-migration工具做新老集群数据迁移
一、服务器准备
目前有两台128G内存服务器,故准备每台启动两个es实例,再加一台虚机,共五个节点,保证down一台服务器两个节点数据不受影响。
二、系统初始化
参见我上一篇kafka系统初始化:https://www.cnblogs.com/mkxfs/p/12030331.html
三、安装elasticsearch7.5.0
1.因zookeeper和kafka需要java启动
首先安装jdk1.8环境
yum install java-1.8.0-openjdk-devel.x86_64 -y
2.官网下载es7.5.0
cd /opt
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.0-linux-x86_64.tar.gz
tar -zxf elasticsearch-7.5.0-linux-x86_64.tar.gz
mv elasticsearch-7.5.0 elasticsearch9300
创建es数据目录
mkdir -p /data/es9300
mkdir -p /data/es9301
3.修改es配置文件
vim /opt/elasticsearch9300/config/elasticsearch.yml
最后添加:
cluster.name: en-es
node.name: node-1
path.data: /data/es9300
path.logs: /opt/elasticsearch9300/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
cluster.routing.allocation.same_shard.host: true
cluster.initial_master_nodes: ["192.168.0.16:9300", "192.168.0.16:9301","192.168.0.17:9300", "192.168.0.17:9301","192.168.0.18:9300"]
discovery.zen.ping.unicast.hosts: ["192.168.0.16:9300", "192.168.0.16:9301","192.168.0.17:9300", "192.168.0.17:9301", "192.168.0.18:9300"]
discovery.zen.minimum_master_nodes: 3
node.max_local_storage_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-credentials: true
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
4.修改jvm堆内存大小
vim /opt/elasticsearch9300/config/jvm.options
-Xms25g
-Xmx25g
5.部署本机第二个节点
cp -r /opt/elasticsearch9300 /opt/elasticsearch9301
vim /opt/elasticsearch9301/config/elasticsearch.yml
最后添加:
cluster.name: en-es
node.name: node-2
path.data: /data/es9301
path.logs: /opt/elasticsearch9301/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9301
cluster.routing.allocation.same_shard.host: true
cluster.initial_master_nodes: ["192.168.0.16:9300", "192.168.0.16:9301","192.168.0.17:9300", "192.168.0.17:9301", "192.168.0.18:9300"]
discovery.zen.ping.unicast.hosts: ["192.168.0.16:9300", "192.168.0.16:9301","192.168.0.17:9300", "192.168.0.17:9301", "192.168.0.18:9300"]
discovery.zen.minimum_master_nodes: 3
node.max_local_storage_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-credentials: true
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
6.继续安装其他三个节点,注意端口号
7.启动elasticsearch服务
因为elasticsearch不允许root用户启动,故添加es账号
groupadd es
useradd es -g es
授权es目录给es用户
chown -R es:es es9300
chown -R es:es es9301
chown -R es:es /data/es9300
chown -R es:es /data/es9301
启动es服务
su - es -c "/opt/elasticsearch9300/bin/elasticsearch -d"
su - es -c "/opt/elasticsearch9301/bin/elasticsearch -d"
查看es日志和端口,没有报错,启动成功即可。
四、安装kibana-7.5.0
1.官网下载kibana-7.5.0
cd /opt
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.5.0-linux-x86_64.tar.gz
tar -zxf kibana-7.5.0-linux-x86_64.tar.gz
2.修改kibana配置文件
vim /opt/kibana-7.5.0-linux-x86_64/config/kibana.yml
server.host: "192.168.0.16"
3.启动kibana
添加kibana日志目录
mkdir /opt/kibana-7.5.0-linux-x86_64/logs
kibana也需要es用户启动
授权kibana目录给es
chown -R es:es kibana-7.5.0-linux-x86_64
启动:
su - es -c "nohup /opt/kibana-7.5.0-linux-x86_64/bin/kibana &>>/opt/kibana-7.5.0-linux-x86_64/logs/kibana.log &"
4.通过浏览器访问kibana
http://192.168.0.16:5601
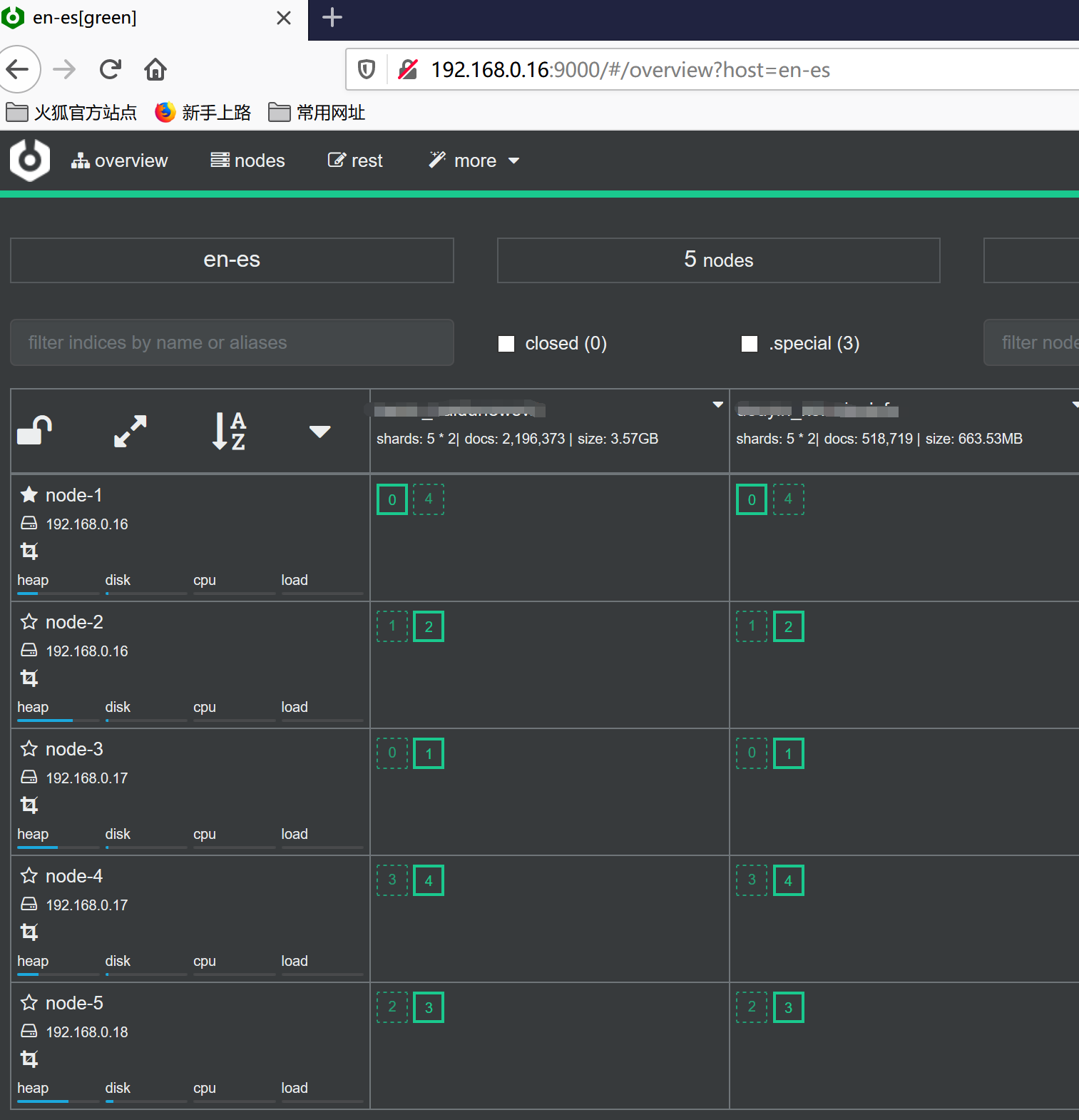
五、安装es监控管理工具cerebro-0.8.5
1.下载cerebro-0.8.5release版
cd /opt
wget https://github.com/lmenezes/cerebro/releases/download/v0.8.5/cerebro-0.8.5.tgz
tar -zxf cerebro-0.8.5.tgz
2.修改cerebro配置
vim /opt/cerebro-0.8.5/conf/application.conf
hosts = [
{
host = "http://192.168.0.16:9200"
name = "en-es"
headers-whitelist = [ "x-proxy-user", "x-proxy-roles", "X-Forwarded-For" ]
}
3.启动cerebro
nohup /opt/cerebro-0.8.5/bin/cerebro -Dhttp.port=9000 -Dhttp.address=192.168.0.16 &>/dev/null &
4.通过浏览器访问
六、通过elasticsearch-migration将老集群数据迁移到新集群上
1.在16上安装elasticsearch-migration
cd /opt
wget https://github.com/medcl/esm-v1/releases/download/v0.4.3/linux64.tar.gz
tar -zxf linux64.tar.gz
mv linux64 elasticsearch-migration
2.停止老集群所有写入操作,开始迁移
/opt/elasticsearch-migration/esm -s http://192.168.0.66:9200 -d http://192.168.0.16:9200 -x indexname -w=5 -b=10 -c 10000 >/dev/null
3.等待迁移完成,一小时大约迁移7000w文档,40G左右,同时最多建议迁移两个索引

elasticsearch7.5.0+kibana-7.5.0+cerebro-0.8.5集群生产环境安装配置及通过elasticsearch-migration工具做新老集群数据迁移的更多相关文章
- vue-cli 3.0 axios 跨域请求代理配置及生产环境 baseUrl 配置
1. 开发环境跨域配置 在 vue.config.js 文件中: module.exports = { runtimeCompiler: true, publicPath: '/', // 设置打包文 ...
- Ubuntu15.10下Hadoop2.6.0伪分布式环境安装配置及Hadoop Streaming的体验
Ubuntu用的是Ubuntu15.10Beta2版本,正式的版本好像要到这个月的22号才发布.参考的资料主要是http://www.powerxing.com/install-hadoop-clus ...
- fedora gtk+ 2.0环境安装配置
1.安装gtk yum install gtk2 gtk2-devel gtk2-devel-docs 2.测试是否安装成功 pkg-config --cflags --libs gtk+-2.0 执 ...
- Android Studio 1.0 苹果电脑安装配置
前言 近日Google终于不负众望,发布了期待已久的Android Studio 1.0正式版.小编自己是Android开发者,之前使用过Eclipse,也试用过Android Studio 0. ...
- Nacos 发布 1.0.0 GA 版本,可大规模投入到生产环境
经过 3 个 RC 版本的社区体验之后,Nacos 正式发布 1.0.0 GA 版本,在架构.功能和 API 设计上进行了全方位的重构和升级. 1.0.0 版本的发布标志着 Nacos 已经可以大规模 ...
- aws ec2 安装Elastic search 7.2.0 kibana 并配置 hanlp 分词插件
文章大纲 Elastic search & kibana & 分词器 安装 版本控制 下载地址 Elastic search安装 kibana 安装 分词器配置 Elastic sea ...
- ELK(elasticsearch+logstash+kibana)入门到熟练-从0开始搭建日志分析系统教程
#此文篇幅较长,涵盖了elk从搭建到运行的知识,看此文档,你需要会点linux,还要看得懂点正则表达式,还有一个聪明的大脑,如果你没有漏掉步骤的话,还搭建不起来elk,你来打我. ELK使用elast ...
- Kibana,Logstash 和 Cerebro 的安装运行
公号:码农充电站pro 主页:https://codeshellme.github.io 1,安装 Kibana Kibana 用于数据可视化,我们可以进入到 Kibana 下载页面下载 Kibana ...
- linux 搭建elk6.8.0集群并破解安装x-pack
一.环境信息以及安装前准备 1.组件介绍 *Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停 ...
随机推荐
- Android View 的添加绘制流程 (二)
概述 上一篇 Android DecorView 与 Activity 绑定原理分析 分析了在调用 setContentView 之后,DecorView 是如何与 activity 关联在一起的,最 ...
- 设计模式之工厂模式(Factory)
转载请标明出处:http://blog.csdn.net/shensky711/article/details/53348412 本文出自: [HansChen的博客] 设计模式系列文章: 设计模式之 ...
- python脚本-简单读取有效python代码量
import os count=[0,0] paths=[] file_count=[0] def sum_code(path): if os.path.isfile(path): one_file( ...
- docker-primary
docker-ce docker网址 https://docs.docker.com/docsarchive/ Docker的安装和启动 官方安装文档链接:https://docs.docker.c ...
- sync.Map(在并发环境中使用的map)
sync.Map 有以下特性: 需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,sync.Map 和 map 不同,不是 ...
- css3学习——一列固定宽度且居中
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 【Python成长之路】词云图制作
[写在前面] 以前看到过一些大神制作的词云图 ,觉得效果很有意思.如果有朋友不了解词云图的效果,可以看下面的几张图(图片都是网上找到的): 网上找了找相关的软件,有些软件制作 还要付费.结果前几天在大 ...
- 一招教你如何修复MySQL slave中继日志损坏问题
[摘要]MySQL的Crash safe slave是指slave crash后,把slave重新拉起来可以继续从Master进行复制,不会出现复制错误也不会出现数据不一致. PS:华为云数据库特惠专 ...
- 简而意赅 HTTP HTTPS SSL TLS 之间有什么不同
HTTP HTTPS SSL TLS 之间有什么不同? SSL是Secure Sockets Layer的缩写.SSL的作用是为网络上的两台机器或设备提供了一个安全的通道. TLS是SSL的一个新的名 ...
- iOS 日志获取和实时浏览器显示日志
https://juejin.im/entry/576252855bbb500063e51c7d iOS 日志获取和实时浏览器显示日志