[CUDA] 00 - GPU Driver Installation & Concurrency Programming
前言
对,这是一个高大上的技术,终于要做老崔当年做过的事情了,生活很传奇。
一、主流 GPU 编程接口
1. CUDA
是英伟达公司推出的,专门针对 N 卡进行 GPU 编程的接口。文档资料很齐全,几乎适用于所有 N 卡。
本专栏讲述的 GPU 编程技术均基于此接口。
2. Open CL
开源的 GPU 编程接口,使用范围最广,几乎适用于所有的显卡。
但相对 CUDA,其掌握较难一些,建议先学 CUDA,在此基础上进行 Open CL 的学习则会非常简单轻松。
3. DirectCompute
微软开发出来的 GPU 编程接口。功能很强大,学习起来也最为简单,但只能用于 Windows 系统,在许多高端服务器都是 UNIX 系统无法使用。
总结,这几种接口各有优劣,需要根据实际情况选用。但它们使用起来方法非常相近,掌握了其中一种再学习其他两种会很容易。
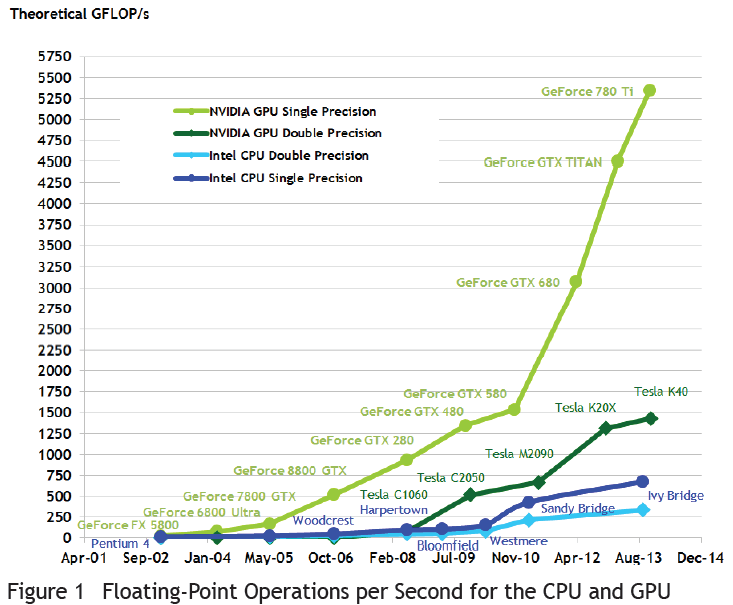
二、并行效率
Ref: https://www.cnblogs.com/muchen/p/6134374.html
三、系统课程
关于GPU并行编程,北美有系统的课程。
CME 213 Introduction to parallel computing using MPI, openMP, and CUDA
Eric Darve, Stanford University
感觉MPI, openMP都被mapReduce干掉了,cuda的部分还有些价值。
加州理工 Computing + Mathematical Sciences,2018年课程【推荐】
四、编译环境
安装过程
驱动安装:Installing Ubuntu 16.04 with CUDA 9.0 and cuDNN 7.3 for deep learning【写的比较详细】
自动脚本:rava-dosa/ubuntu 16.04 nvidia 940 mx.sh
参考博文:How to Setup Ubuntu 16.04 with CUDA, GPU, and other requirements for Deep Learning
安装驱动:Deep Learning GPU Installation on Ubuntu 18.4 【已实践验证】
问题解决
X server issue: How to install NVIDIA.run?
出现返回登陆问题的恢复办法:https://www.jianshu.com/p/34236a9c4a2f
sudo apt-get remove --purge nvidia-*
sudo apt-get install ubuntu-desktop
sudo rm /etc/X11/xorg.conf
echo 'nouveau' | sudo tee -a /etc/modules
#重启系统
sudo reboot
驱动切换
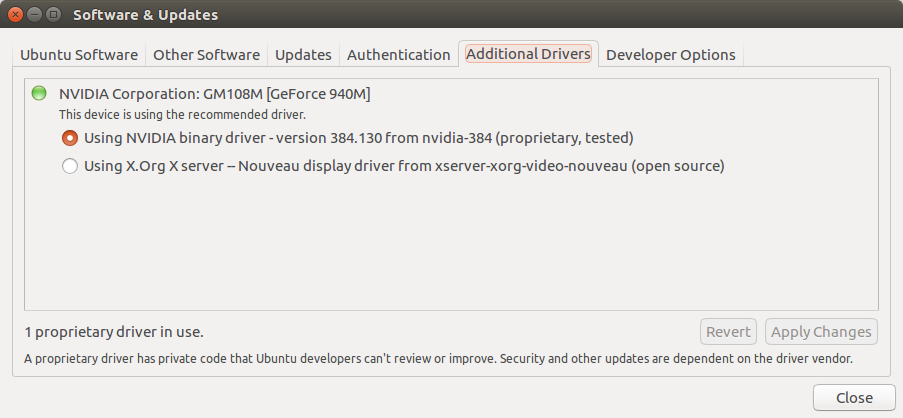
sudo apt-get install nvidia-cuda-toolkit cpu one thread : Time cost: 30.723241 sec, data[100] is -0.207107
gpu full threads : Time cost: 0.107630 sec, data[100] is -0.207107
这是在笔记本的测试,即使cpu四线程全开,也是70倍的加速。
五、机器学习和GPU
当前貌似还没有一套完整的方案,但是不同的算法貌似有不同的库支持相应的GPU加速版本,也就是说,这一领域暂时处于“三国分立”的阶段。
编程套路
没错,一切皆套路
一、GPU Computing: Step by Step
• Setup inputs on the host (CPU-accessible memory)
• Allocate memory for outputs on the host
• Allocate memory for inputs on the GPU
• Allocate memory for outputs on the GPU
• Copy inputs from host to GPU
• Start GPU kernel (function that executed on gpu)
• Copy output from GPU to host
硬件知识
一、N卡发展小故事
Link: jcjohnson/cnn-benchmarks
Ref: Build a super fast deep learning machine for under $1,000
Graphics card/GPU
Perhaps the most important attribute to look at for deep learning is the available RAM on the card. If TensorFlow can’t fit the model and the current batch of training data into the GPU’s RAM it will fail over to the CPU—making the GPU pointless.
至少CPU先稳定,再谈GPU的事儿。
Another key consideration is the architecture of the graphics card. The last few architectures NVIDIA has put out have been called “Kepler,” “Maxwell,” and “Pascal”—in that order. The difference between the architectures really matters for speed; for example, the Pascal Titan X is twice the speed of a Maxwell Titan X according to this benchmark.

GPUs are critical: The Pascal Titan X with cuDNN is 49x to 74x faster than dual Xeon E5-2630 v3 CPUs.
Most of the papers on machine learning use the TITAN X card, which is fantastic but costs at least $1,000, even for an older version. Most people doing machine learning without infinite budget use the NVIDIA GTX 900 series (Maxwell) or the NVIDIA GTX 1000 series (Pascal).
To figure out the architecture of a card, you can look at the spectacularly confusing naming conventions of NVIDIA: the 9XX cards use the Maxwell architecture while the 10XX cards use the Pascal architecture.
But a 980 card is still probably significantly faster than a 1060 due to higher clock speed and more RAM.
You will have to set different flags for NVIDIA cards based on the architecture of the GPU you get. But the most important thing is any 9XX or 10XX card will be an order of magnitude faster than your laptop.
Don’t be paralyzed by the options; if you haven’t worked with a GPU, they will all be much better than what you have now.
I went with the GeForce GTX 1060 3GB for $195, and it runs models about 20 times faster than my MacBook, but it occasionally runs out of memory for some applications, so I probably should have gotten the GeForce GTX 1060 6GB for an additional $60.
二、显卡推荐
Ref: Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning
2017-04-09
General GPU Recommendations
Generally, I would recommend the GTX 1080 Ti, GTX 1080 or GTX 1070.
They are all excellent cards and if you have the money for a GTX 1080 Ti you should go ahead with that.
The GTX 1070 is a bit cheaper and still faster than a regular GTX Titan X (Maxwell).
The GTX 1080 was bit less cost efficient than the GTX 1070 but since the GTX 1080 Ti was introduced the price fell significantly and now the GTX 1080 is able to compete with the GTX 1070.
All these three cards should be preferred over the GTX 980 Ti due to their increased memory of 11GB and 8GB (instead of 6GB).
【GPU显存最好大于6GB】
I personally would go with multiple GTX 1070 or GTX 1080 for research. I rather run a few more experiments which are a bit slower than running just one experiment which is faster.
In NLP the memory constraints are not as tight as in computer vision and so a GTX 1070/GTX 1080 is just fine for me. The tasks I work on and how I run my experiments determines the best choice for me, which is either a GTX 1070 or GTX 1080.
Best GPU overall (by a small margin): Titan Xp
Cost efficient but expensive: GTX 1080 Ti, GTX 1070, GTX 1080
Cost efficient and cheap: GTX 1060 (6GB)
I work with data sets > 250GB: GTX Titan X (Maxwell), NVIDIA Titan X Pascal, or NVIDIA Titan Xp
I have little money: GTX 1060 (6GB)
I have almost no money: GTX 1050 Ti (4GB)
I do Kaggle: GTX 1060 (6GB) for any “normal” competition, or GTX 1080 Ti for “deep learning competitions”
I am a competitive computer vision researcher: NVIDIA Titan Xp; do not upgrade from existing Titan X (Pascal or Maxwell)
I am a researcher: GTX 1080 Ti. In some cases, like natural language processing, a GTX 1070 or GTX 1080 might also be a solid choice — check the memory requirements of your current models
I want to build a GPU cluster: This is really complicated, you can get some ideas here
I started deep learning and I am serious about it: Start with a GTX 1060 (6GB). Depending of what area you choose next (startup, Kaggle, research, applied deep learning) sell your GTX 1060 and buy something more appropriate
I want to try deep learning, but I am not serious about it: GTX 1050 Ti (4 or 2GB)
- NVIDIA GeForce GTX 1070

电源要好,易于显卡扩展。
内存建议16GB。
CPU Intel i5
三、GPU模式切换
From: Tensorflow中使用指定的GPU及GPU显存
(1) 终端执行程序时设置使用的GPU
如果电脑有多个GPU,tensorflow默认全部使用。
如果想只使用部分GPU,可以设置CUDA_VISIBLE_DEVICES。在调用python程序时,可以使用(Link 中 Franck Dernoncourt的回复):
CUDA_VISIBLE_DEVICES=1 python my_script.py

Environment Variable Syntax Results CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen
CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible
CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional
CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked
CUDA_VISIBLE_DEVICES="" No GPU will be visible
(2) python代码中设置使用的GPU
如果要在python代码中设置使用的GPU(如使用pycharm进行调试时),可以使用下面的代码(Link 中 Yaroslav Bulatov的回复):
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
(3) 设置tensorflow使用的显存大小
<3.1> 定量设置显存
默认tensorflow是使用GPU尽可能多的显存。可以通过下面的方式,来设置使用的GPU显存:
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7) // 分配:GPU实际显存*0.7
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
<3.2> 按需设置显存
上面的只能设置固定的大小。如果想按需分配,可以使用allow_growth参数(参考网址:http://blog.csdn.net/cq361106306/article/details/52950081):
gpu_options = tf.GPUOptions(allow_growth=True)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
四、Phone GPU
Android GPU: https://blog.csdn.net/u011723240/article/details/30109763
培训大纲:https://blog.csdn.net/PCb4jR/article/details/78890915
Sobel算子对比,表中是一些测量得到的结果:
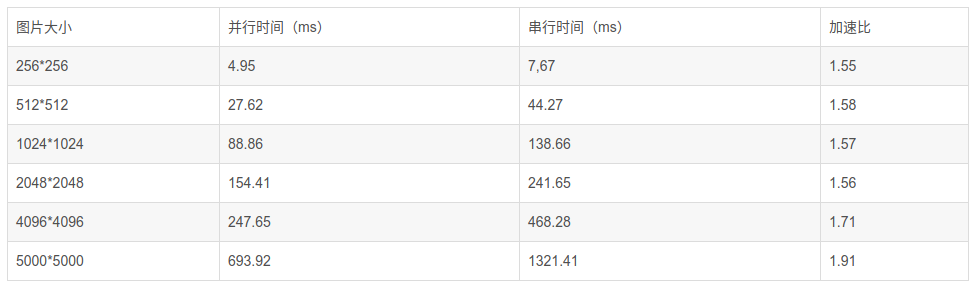
从上述结果可以看出,在上述实验平台上,随着图片大小的增大(数据处理更加复杂),并行化的加速比会更加明显。
End.
[CUDA] 00 - GPU Driver Installation & Concurrency Programming的更多相关文章
- 记:第一次更新服务器CUDA和GPU驱动
因有需求需要改动centos7中的CUDA(更新到10)和GUP 的driver(更新到410)的版本. 事先需要查看原版本的信息,使用nvidia-smi可以查看driver的版本信息(最新的也显示 ...
- [转]如何远程连接运行OpenGL/Cuda 等GPU程序
发现一篇神文,解决了困扰许久的远程桌面OpenGL/GPU 等问题... 原地址在这:http://www.tanglei.name/how-to-run-gpu-programs-using-rem ...
- 安装cuda时 提示toolkit installation failed using unsupported compiler解决方法
在安装cuda的时候,有时候会提示toolkit installation failed using unsupported compiler.这是因为GCC版本不合适所导致的. 解决的方法很简单,直 ...
- Ubuntu18.04: GPU Driver 390.116 + CUDA9.0 + cuDNN7 + tensorflow 和pytorch环境搭建
1.close nouveau 终端输入:sudo gedit /etc/modprobe.d/blacklist.conf 末尾加两行 blacklist nouveau options nouve ...
- Concurrency Programming Guide 并发设计指引(二)
以下翻译是本人通过谷歌工具进行翻译,并进行修正后的结果,希望能对大家有所帮助.如果您发现翻译的不正确不合适的地方,希望您能够发表评论指正,谢谢.转载请注明出处. Concurrency and App ...
- (转)基于CUDA的GPU光线追踪
作者:Asixa 链接:https://zhuanlan.zhihu.com/p/55855479 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 替STL. ...
- 【并行计算-CUDA开发】CUDA编程——GPU架构,由sp,sm,thread,block,grid,warp说起
掌握部分硬件知识,有助于程序员编写更好的CUDA程序,提升CUDA程序性能,本文目的是理清sp,sm,thread,block,grid,warp之间的关系.由于作者能力有限,难免有疏漏,恳请读者批评 ...
- CUDA—使用GPU暴力破解密码
GPU支持大规模的并行加速运算,胜在量上,CPU处理大量的并行运算显得力不从心,它是胜在逻辑上.利用显卡加速的应用越来越多,但如果说GPU即将或最终将替代CPU还有点言过其实,二者最终将优势互补,各尽 ...
- Zadig - USB driver installation made easy
http://zadig.akeo.ie/
随机推荐
- Centos知识
1.看系统的版本: cat /etc/redhat-release 2.看内核版本: uname -r 3.查看系统是32位还是64位 uname - m 4.磁盘: 磁盘分区有主分区.扩展分区和逻辑 ...
- Jmeter发送post请求报错Content type 'application/x-www-form-urlencoded;charset=UTF-8' not supported
常识普及: Content-type,在Request Headers里面,告诉服务器,我们发送的请求信息格式,在JMeter中,信息头存储在信息头管理器中,所以在做接口测试的时候,我们维护Conte ...
- 过滤掉Abp框架不需要记录的日志
该文章是系列文章 基于.NetCore和ABP框架如何让Windows服务执行Quartz定时作业 的其中一篇. 问题 ABP.WindowsService/Demo.MyJob/4.0.0该项目不仅 ...
- java学习之String类
标签(空格分隔): String类 String 的概述 class StringDemo{ public static void main(String[] args){ String s1=&qu ...
- NLP(十九) 双向LSTM情感分类模型
使用IMDB情绪数据来比较CNN和RNN两种方法,预处理与上节相同 from __future__ import print_function import numpy as np import pa ...
- c#中的委托01
delegate 是表示对具有特定参数列表和返回类型的方法的引用的类型. 在实例化委托时,你可以将其实例与任何具有兼容签名和返回类型的方法相关联. 你可以通过委托实例调用方法. 委托用于将方法作为参数 ...
- D-Big Integer_2019牛客暑期多校训练营(第三场)
题意 设A(n) = n个1,问有多少对i,j使得\(A(i^j)\equiv0(modp)\) 题解 \(A(n) = \frac{10^n-1}{9}\) 当9与p互质时\(\frac{10^n- ...
- P3469 [POI2008]BLO-Blockade 割点 tarjan
题意 给定一个无向图,问删掉点i,图中相连的有序对数.(pair<x, y> , x != y);求每个点对应的答案 思路 首先我们可以发现,如果这个点不是割点,那么答案就是n-1,如果是 ...
- 牛客国庆集训派对Day3 B Tree(树形dp + 组合计数)
传送门:https://www.nowcoder.com/acm/contest/203/B 思路及参考:https://blog.csdn.net/u013534123/article/detail ...
- 2015 JSOI冬令营训练 彩色格子 题解
解析 棋盘上黑白格染色.曼哈顿距离偶数:奇偶性相同. 枚举有几种颜色分到白格,组合数计算即可. 注意预处理,时间还是比较宽裕的. 为了不重复计数,考虑枚举严格用了i种颜色,我们再枚举分配j种给白集合. ...