Redis实现分布式文件夹锁

缘起
最近做一个项目,类似某度云盘,另外附加定制功能,本人负责云盘相关功能实现,这个项目跟云盘不同的是,以项目为分配权限的单位,同一个项目及子目录所有有权限的用户可以同时操作所有文件,这样就很容易出现并发操作,而且表结构设计的时候,定下来文件和文件夹都有个path字段,存储的是所在父级文件夹路径,这样检索方便,重命名和移动比较麻烦。
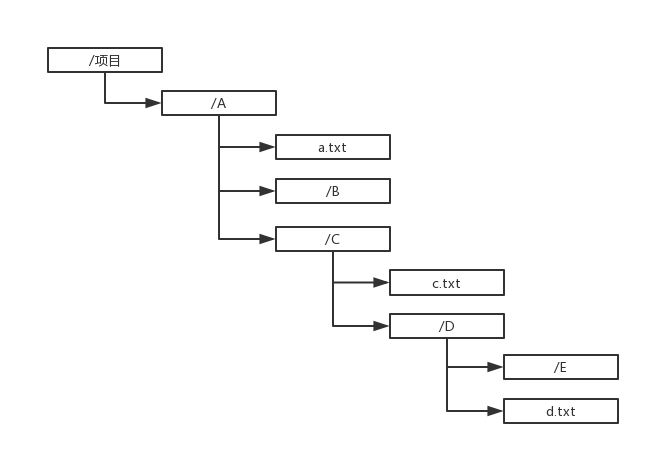
如下,例如甲同学正在移动项目下C文件夹,而此时乙同学也在操作项目下D下的d.txt文件,这样就会出现问题,所以需要分布式锁控制,甲在操作C文件夹的时候,C文件夹所有子文件和包含C文件夹的父文件夹都被锁住,如图将会被锁定的文件夹和子文件有:A、C、c.txt、D、E、d.txt,其中a.txt和B未被锁定,这个是移动的情况,如下表格列出其他情况.
| 操作对象 | 操作 | 新建 | 上传 | 移动文件夹 | 移动文件 | 复制文件夹 | 复制文件 | 重命名文件夹 | 重命名文件 | 删除文件夹 | 删除文件 | 回收站清除 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| /A | 新建 | √ | √ | × | √ | × | √ | × | √ | × | √ | / |
| /A | 上传 | √ | √ | × | √ | × | √ | × | √ | × | √ | / |
| /A->/B | 移动文件夹 | A×B× | A×B× | A×B× | A×B× | A√B√ | A√B√ | A×B× | A×B√ | A×B× | A×B√ | / |
| a.txt->/B | 移动文件 | B√ | B√ | B× | B√ | B× | a√B× | a×B× | a×B√ | B× | a×B√ | / |
| /A->/B | 复制文件夹 | B√ | B√ | B× | B√ | B√ | B√ | B× | B√ | B× | B√ | / |
| a.txt->/B | 复制文件 | B√ | B√ | B× | B√ | B√ | B√ | B× | B√ | B× | B√ | / |
| /A | 重命名文件夹 | A× | A× | A× | A× | A√ | A√ | A× | A× | A× | A× | / |
| a.txt | 重命名文件 | / | / | × | × | × | × | √ | × | × | × | / |
| /A | 删除文件夹 | × | × | × | × | × | × | × | × | × | × | / |
| a.txt | 删除文件 | × | × | × | × | × | × | × | × | × | × | / |
| /A,a.txt | 回收站清除 | / | / | / | / | / | / | / | / | / | / | A×a× |
符号解释:√:可以操作,×:不可以操作,/:互相不影响
整体解释:例如第一行,意思是:对于A这个文件夹,当第一个人进行新建操作的时候,其他人同时进行新建、上传、移动文件、复制文件、重命名文件、删除文件是允许的,移动文件夹、复制文件夹、重命名文件夹、删除文件夹是不允许的,回收站清除和新建操作是互不影响的。
思考和调研
分布式锁常见的三种实现方式:数据库、zookeeper/etcd(临时有序节点)、redis(setnx/lua脚本),各有千秋。
数据库实现分布式锁
实现
原理简单易实现,创建一张lock表,存储锁定的资源、上锁对象、获取锁的资源、获取锁时间等,获取锁时查询该资源是否存在记录,存在且未过失效时间则获取锁失败,不存在则插入一条数据并且获取锁成功;释放锁则更简单,删除锁数据即可。
缺点
- 释放锁删除数据时,会出现死锁情况
优点
- 实现简单
zookeeper/etcd实现分布式锁
redis实现分布式锁
详见Redis总结
分布式文件夹锁实现过程
基于开文处所列情况,要覆盖所有复杂情况很难,但是实现基本的文件夹锁是必须的,故选择了redis+lua脚本,具体代码如下
java获取锁工具类
/**
* redis工具类
*/
public class RedisLockUtils {
static final Long SUCCESS = 1L;
static final String LOCKED_HASH = "cs:lockedHashKey";
static final String GET_LOCK_LUA_RESOURCE = "/lua/getFileLock.lua";
static final String RELEASE_LOCK_LUA_RESOURCE = "/lua/releaseFileLock.lua";
static final Logger LOG = LoggerFactory.getLogger(RedisLockUtils.class);
/**
* 获取文件夹锁
* @param redisTemplate
* @param lockProjectId
* @param lockKey
* @param requestValue
* @param expireTime 单位:秒
* @return
*/
public static boolean getFileLock(RedisTemplate redisTemplate, Long lockProjectId, String lockKey, String requestValue, Integer expireTime) {
LOG.info("start run lua script,{{}} start request lock",lockKey);
long start = System.currentTimeMillis();
DefaultRedisScript<String> luaScript =new DefaultRedisScript<>();
luaScript.setLocation(new ClassPathResource(GET_LOCK_LUA_RESOURCE));
luaScript.setResultType(String.class);
Object result = redisTemplate.execute(
luaScript,
Arrays.asList(lockKey, LOCKED_HASH + lockProjectId),
requestValue,
String.valueOf(expireTime),
String.valueOf(System.currentTimeMillis())
);
boolean getLockStatus = SUCCESS.equals(result);
LOG.info("{{}} cost time {} ms,request lock result:{}",lockKey,(System.currentTimeMillis()-start), getLockStatus);
return getLockStatus;
}
/**
* 释放文件夹锁
* @param redisTemplate
* @param lockProjectId
* @param lockKey
* @param requestValue
* @return
*/
public static boolean releaseFileLock(RedisTemplate redisTemplate, Long lockProjectId, String lockKey, String requestValue) {
DefaultRedisScript<String> luaScript =new DefaultRedisScript<>();
luaScript.setLocation(new ClassPathResource(RELEASE_LOCK_LUA_RESOURCE));
luaScript.setResultType(String.class);
Object result = redisTemplate.execute(
luaScript,
Arrays.asList(lockKey, LOCKED_HASH + lockProjectId),
requestValue
);
boolean releaseLockStatus = SUCCESS.equals(result);
LOG.info("{{}}release lock result:{}", lockKey, releaseLockStatus);
return releaseLockStatus;
}
}
lua脚本
获取文件夹锁
入参说明
requestKey为请求锁的路径,requestValue为请求锁的value,应为请求锁时生成的UUID,确保解锁人只能为上锁人,lockedKeys为存放所有锁的哈希表的key,这里用常量加项目id的方式,确保一个项目的所有锁存在一个哈希表里面,expireTime为锁的过期时间,nowTime为当前时间,由于lua脚本里面获取当前时间消耗性能且获取的是redis服务器上的当前时间,可能不准确。
思路说明
首先,通过GET key判断是否有人正在操作这个文件夹,若有人在操作则直接返回0(获取锁失败),否则获取存放该项目锁的哈希表里面的所有key,遍历所有key,通过lua脚本的string.find函数对比该key和请求的key是否存在包含或被包含关系,若存在包含关系且未失效,则返回0(获取锁失败),否则则可获取锁,设置key和过期时间及存入哈希表(哈希表内存放请求锁的key和请求时间),最后返回1(获取锁成功)。
例如请求上图中项目下的C文件夹的锁,请求路径为:项目/A/C,当另一个人想操作D文件夹,请求路径为:项目/A/C/D,此时查询到存储这个项目所有锁定key的哈希表,里面包含项目/A/C这个key,这两个key通过lua函数string.find发现项目/A/C/D包含项目/A/C,且未到过期时间,则获取锁失败,否则获取锁成功。
local requestKey=KEYS[1]
local lockedKeys=KEYS[2]
local requestValue=ARGV[1]
local expireTime=ARGV[2]
local nowTime=ARGV[3]
if redis.call('get',requestKey)
then
return 0
end
local lockedHash = redis.call('hkeys',lockedKeys)
for i=1, #lockedHash do
if string.find(requestKey,lockedHash[i]) or string.find(lockedHash[i],requestKey)
then
local lockTime = redis.call('hget',lockedKeys,lockedHash[i])
if (nowTime-lockTime) >= expireTime * 1000
then
redis.call('hdel',lockedKeys,lockedHash[i])
else
return 0
end
end
end
redis.call('set',requestKey,requestValue)
redis.call('expire',requestKey,expireTime)
redis.call('hset',lockedKeys,requestKey,nowTime)
return 1
释放文件夹锁
入参说明
requestKey为请求锁的路径,requestValue为请求锁的value,应为请求锁时生成的UUID,确保解锁人只能为上锁人,lockedKeys为存放所有锁的哈希表的key,这里用常量加项目id的方式,确保一个项目的所有锁存在一个哈希表里面。
local requestKey=KEYS[1]
local lockedKeys=KEYS[2]
local requestValue=ARGV[1]
if redis.call('get', requestKey) == requestValue
then
redis.call('hdel', lockedKeys,requestKey)
return redis.call('del',requestKey)
else
return 0
end
优点
- 灵活,锁定的范围可以随
requestKey变化而变化 - 性能不错,经测试除了第一次lua脚本未缓存耗时较长,第二次之后则在10ms左右可得到请求结果
缺点
- 可靠性依赖redis
- 不是可重入锁
- 维护成本较高,需熟知redis的5种数据结构及lua脚本
总结
通过单元自测和测试环境测试基本可以确保多数情况下的多用户并发操作文件只有一人能进行有效操作,保证了数据的安全性。经过这次实践,对分布式锁有了更深入的了解。
更多信息可以关注我的个人博客:逸竹小站
也欢迎关注我的公众号:yizhuxiaozhan,二维码:

Redis实现分布式文件夹锁的更多相关文章
- linux下面查找文件夹名称
其中如果查找redis开头的文件夹,可以输入 find / -name redis* -d
- 用Redis构建分布式锁-RedLock(真分布)
在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但是这些库实现的方式差别很大,而且很多简单的实现其实只需采用稍微增 ...
- redis/分布式文件存储系统/数据库 存储session,解决负载均衡集群中session不一致问题
先来说下session和cookie的异同 session和cookie不仅仅是一个存放在服务器端,一个存放在客户端那么笼统 session虽然存放在服务器端,但是也需要和客户端相互匹配,试想一个浏览 ...
- Redis实现分布式锁
http://redis.io/topics/distlock 在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但 ...
- Redis构建分布式锁
1.前言 为什么要构建锁呢?因为构建合适的锁可以在高并发下能够保持数据的一致性,即客户端在执行连贯的命令时上锁的数据不会被别的客户端的更改而发生错误.同时还能够保证命令执行的成功率. 看到这里你不禁要 ...
- redis咋么实现分布式锁,redis分布式锁的实现方式,redis做分布式锁 积极正义的少年
前言 分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介 ...
- Redis实现分布式锁的正确姿势
分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介绍Re ...
- 基于Redis的分布式锁真的安全吗?
说明: 我前段时间写了一篇用consul实现分布式锁,感觉理解的也不是很好,直到我看到了这2篇写分布式锁的讨论,真的是很佩服作者严谨的态度, 把这种分布式锁研究的这么透彻,作者这种技术态度真的值得我好 ...
- 【转】Redis学习笔记(四)如何用Redis实现分布式锁(1)—— 单机版
原文地址:http://bridgeforyou.cn/2018/09/01/Redis-Dsitributed-Lock-1/ 为什么要使用分布式锁 这个问题,可以分为两个问题来回答: 为什么要使用 ...
随机推荐
- window下tomcat的下载安装和环境配置
一.下载安装tomcat 去官网:http://tomcat.apache.org/ 下载自己所需要的版本,解压在没有中文的文件夹路径下. 直接打开压缩包下面,进入bin目录,双击startup.b ...
- 集合数组与String的互转
1.集合转成数组: 转之前集合里面存的什么类型的数据,就new什么类(特别:存的是基本数据的封装类,就要new他的封装类) 例如: 1.1集合: ArrayList<Character> ...
- Redis 的底层数据结构(SDS和链表)
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件.可能几乎所有的线上项目都会使用到 Redis,无论你是做缓存.或是用作消息中间件,用起来很简单方便 ...
- SpringBoot整合Elasticsearch详细步骤以及代码示例(附源码)
准备工作 环境准备 JAVA版本 java version "1.8.0_121" Java(TM) SE Runtime Environment (build 1.8.0_121 ...
- 宝锋UV-5R说明书下载
宝锋UV-5R说明书 百度网盘下载地址: 链接: https://pan.baidu.com/s/1QJXEJ2YyO7ovMAQG7Uur4A 提取码: j8d2 BI8EJM 73 ...
- python接口自动化测试七:获取登录的Cookies
python接口自动化测试七:获取登录的Cookies,并关联到下一个请求 获取登录的cookies:loginCookies = r.cookies 把获取到的cookies传入请求:cooki ...
- 控制执行流程之break和continue
1.在任何迭代语句的主体部分,都可以用break和continue来控制程序执行流程. 2.注意: break:用于强行退出循环, 不执行循环中剩余的语句:continue:停止当前的循环,执行下一次 ...
- Java NIO之理解I/O模型(二)
前言 上一篇文章讲解了I/O模型的一些基本概念,包括同步与异步,阻塞与非阻塞,同步IO与异步IO,阻塞IO与非阻塞IO.这次一起来了解一下现有的几种IO模型,以及高效IO的两种设计模式,也都是属于IO ...
- [VB.NET Tips]Select Case语句拾遗
正常的Select 语句如下: Dim status As Integer = 5 Select Case status Case 0 Console.WriteLine("状态是:0&qu ...
- hadoop集群zookeeper迁移
1. zookeeper作用 ZooKeepr在Hadoop中的应用主要有: 1.1 HDFS中NameNode的HA和YARN中ResourceManager的HA. 1.2 存储RMStateSt ...