【原创】ARMv8 MMU及Linux页表映射
背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 介绍
要想理解好Linux的页表映射,MMU的机制是需要去熟悉的,因此将这两个模块放到一起介绍。
关于ARMv8 MMU的相关内容,主要参考文档:《ARM Cortex-A Series Programmer’s Guide for ARMv8-A》。
2. ARMv8 MMU
2.1 MMU/TLB/Cache概述
MMU:完成的工作就是虚拟地址到物理地址的转换,可以让系统中的多个程序跑在自己独立的虚拟地址空间中,相互不会影响。程序可以对底层的物理内存一无所知,物理地址可以是不连续的,但是不妨碍映射连续的虚拟地址空间。TLB:MMU工作的过程就是查询页表的过程,页表放置在内存中时查询开销太大,因此专门有一小片访问更快的区域用于存放地址转换条目,用于提高查找效率。当页表内容有变化的时候,需要清除TLB,以防止地址映射出错。Cache:处理器和存储器之间的缓存机制,用于提高访问速率,在ARMv8上会存在多级Cache,其中L1 Cache分为指令Cache和数据Cache,在CPU Core的内部,支持虚拟地址寻址;L2 Cache容量更大,同时存储指令和数据,为多个CPU Core共用,这多个CPU Core也就组成了一个Cluster。
下图浅黄色部分描述的就是一个地址转换的过程。
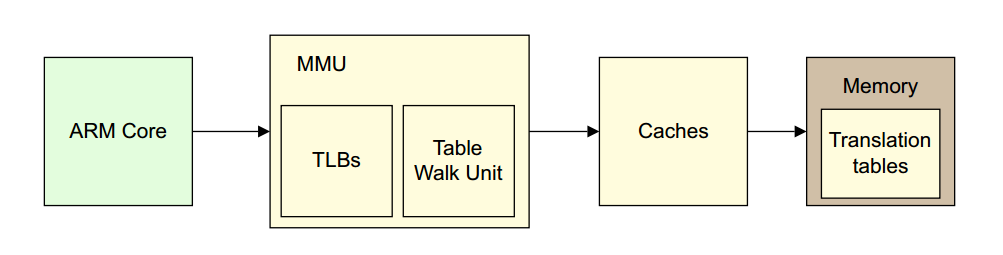
由于上图没有体现出L1和L2 Cache和MMU的关系,所以再来一张图吧:
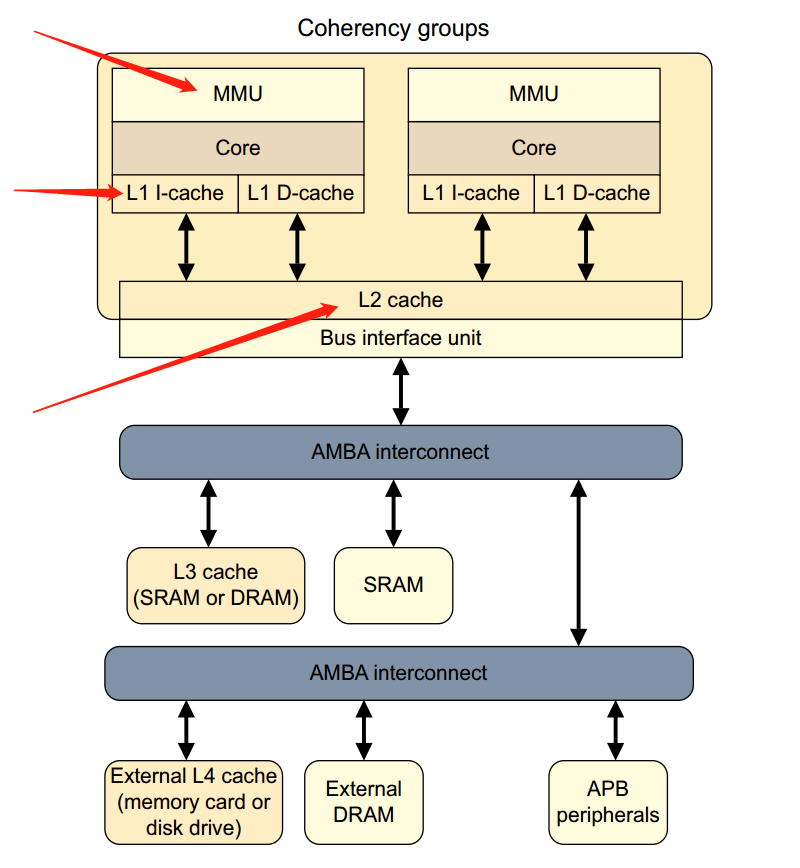
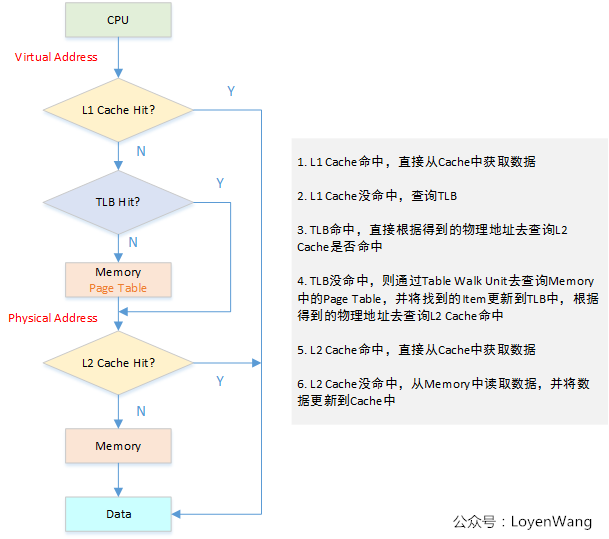
那具体是怎么访问的呢?再来一张图:
2.2 虚拟地址到物理地址的转换
虚拟地址到物理地址的映射通过查表的机制来实现,ARMv8中,Kernel Space的页表基地址存放在TTBR1_EL1寄存器中,User Space页表基地址存放在TTBR0_EL0寄存器中,其中内核地址空间的高位为全1,(0xFFFF0000_00000000 ~ 0xFFFFFFFF_FFFFFFFF),用户地址空间的高位为全0,(0x00000000_00000000 ~ 0x0000FFFF_FFFFFFFF)
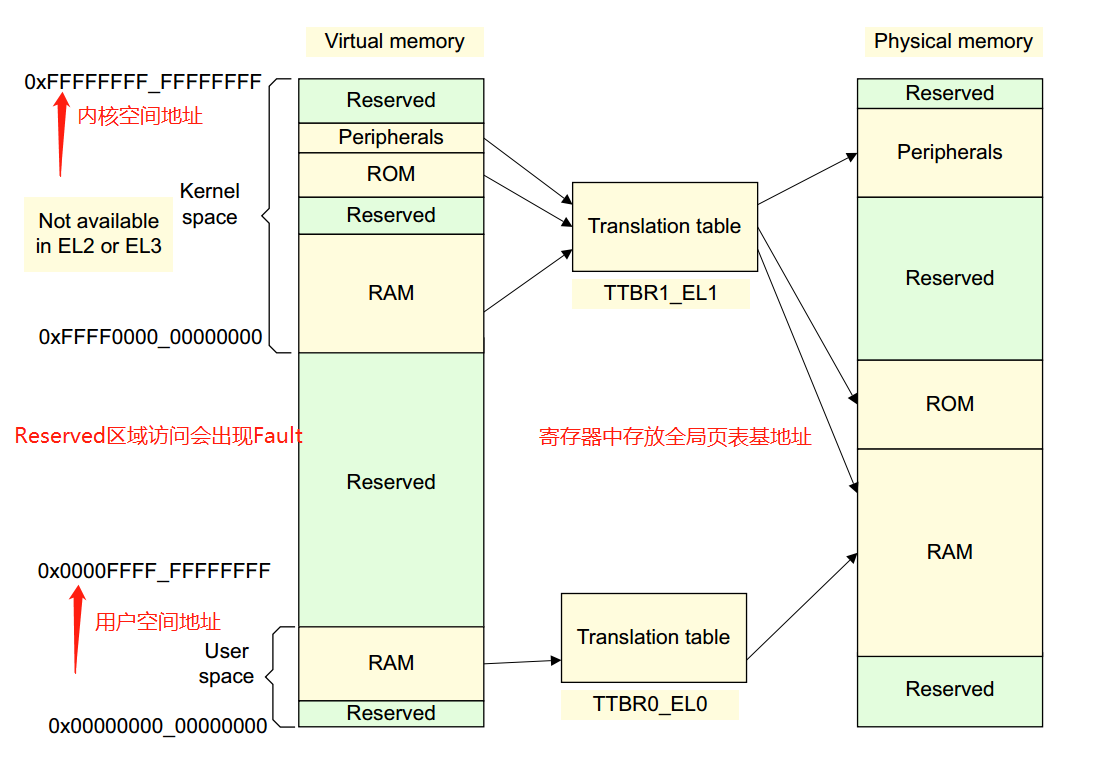
ARMv8中:
虚拟地址支持
64位虚拟地址中,并不是所有位都用上,除了高16位用于区分内核空间和用户空间外,有效位的配置可以是:36, 39, 42, 47。这可决定Linux内核中地址空间的大小。比如我使用的内核中有效位配置为CONFIG_ARM64_VA_BITS=39,用户空间地址范围:0x00000000_00000000 ~ 0x0000007f_ffffffff,大小为512G,内核空间地址范围:0xffffff80_00000000 ~ 0xffffffff_ffffffff,大小为512G。页面大小支持
支持3种页面大小:4KB, 16KB, 64KB。页表支持
支持至少两级页表,至多四级页表,Level 0 ~ Level 3。
结合有效虚拟地址位, 页面大小,页表的级数,可以组合成不同的页表映射方式。
我使用的内核配置为:39位有效位,4KB大小页面,3级页表,所以我会以这个组合来介绍。
在ARMv8的手册中刚好找到了下图,描述了整个translation的过程,简直完美:
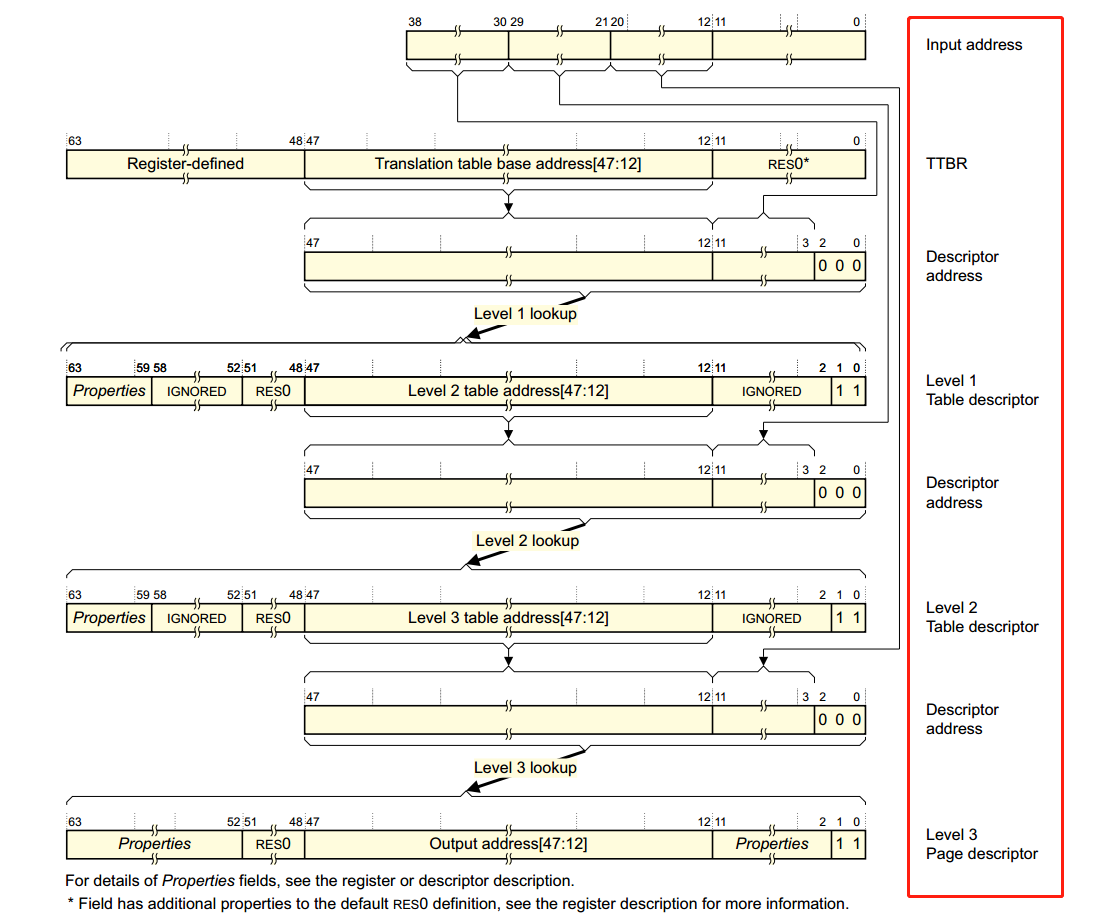
- 虚拟地址[63:39]用于区分内核空间与用户空间,从而选择不同的
TTBRn寄存器来获取Level 1页表基地址; - 虚拟地址[38:30]放置
Level 1页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取Level 2页表基地址; - 虚拟地址[29:21]
Level 2页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取Level 3页表基地址; - 虚拟地址[20:12]
Level 3页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取物理地址的高36位,以4K地址对齐; - 虚拟地址[11:0]放置的是物理地址的偏移,结合获取的物理地址高位,最终得到物理地址。
讲到这里还没有完,是时候看一下Table Descriptor了,也就是页表中存放的内容,有以下四种类型:
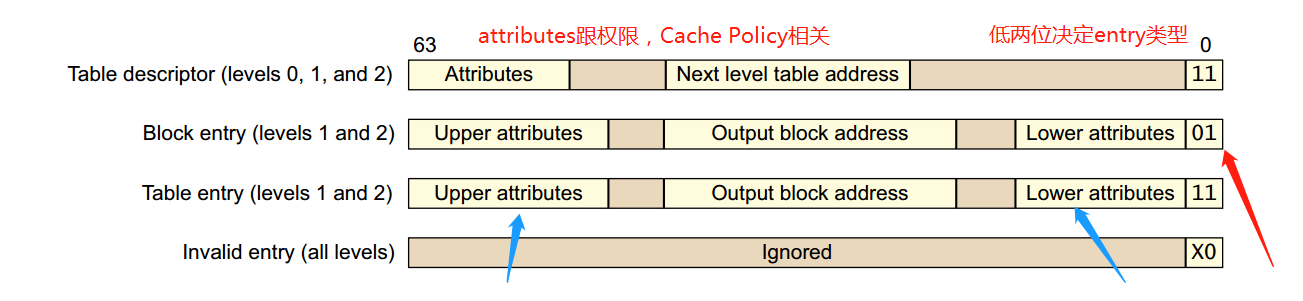
类型有低两位来决定,其中Level 0中的Table Descriptor只能输出Level 1页表的地址,Level 3中的Table Descriptor只能输出block addresses。
看到图中的attributes了吗,这些可以用于memory的权限控制,memory ordering,cache policy的操作等。
在ARMv8中,与页表相关的寄存器有:TCR_EL1, TTBRx_EL1.
3. Linux页表映射
3.1 Linux页表基本操作
看过《深入理解Linux内核》的同学应该很熟悉下边这张图片,Linux的分页模式(图中以X86为例,页表基地址由CR3寄存器指定):
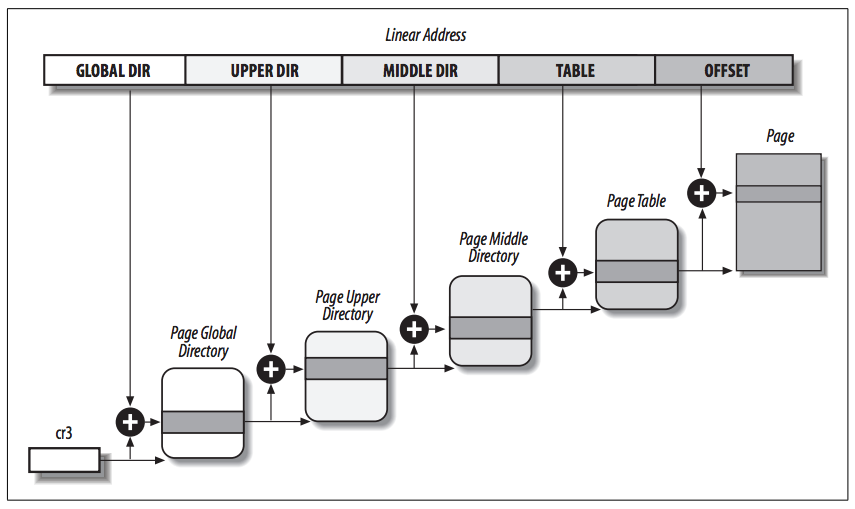
在Linux内核中支持4级页表的模型,同时适用于32位和64位系统。
那么ARMv8与Linux内核是怎么结合的呢?以我实际使用的设置(39位有效位,4KB大小页面,3级页表)为例,如下图所示:
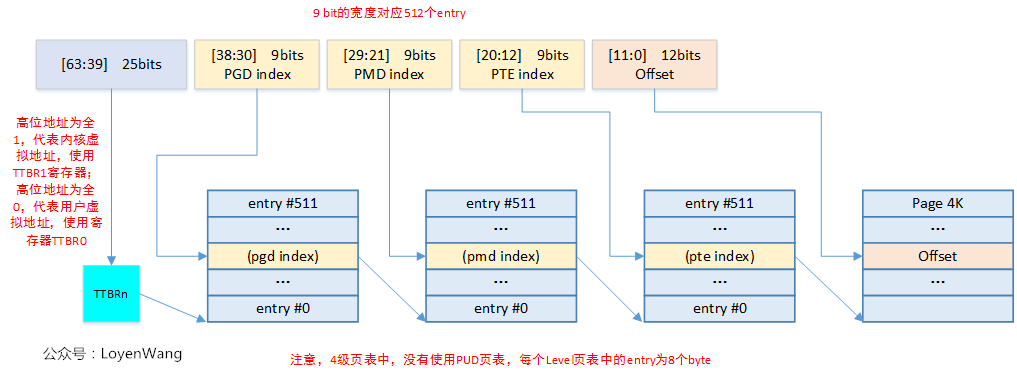
基本上内核中关于页表的操作都会围绕着上图进行操作,似乎脱离了代码有点不太合适,那么就来一波fucking source code解析吧,主要讲讲各类page table相关的API。
代码路径:
arch/arm64/include/asm/pgtable-types.h:定义pgd_t, pud_t, pmd_t, pte_t等类型;
arch/arm64/include/asm/pgtable-prot.h:针对页表中entry中的权限内容设置;
arch/arm64/include/asm/pgtable-hwdef.h:主要包括虚拟地址中PGD/PMD/PUD等的划分,这个与虚拟地址的有效位及分页大小有关,此外还包括硬件页表的定义, TCR寄存器中的设置等;
arch/arm64/include/asm/pgtable.h:页表设置相关;
在这些代码中可以看到,
- 当
CONFIG_PGTABLE_LEVELS=4时:pgd-->pud-->pmd-->pte; - 当
CONFIG_PGTABLE_LEVELS=3时,没有PUD页表:pgd(pud)-->pmd-->pte; - 当
CONFIG_PGTABLE_LEVELS=2时,没有PUD和PMD页表:pgd(pud, pmd)-->pte
常用的宏定义
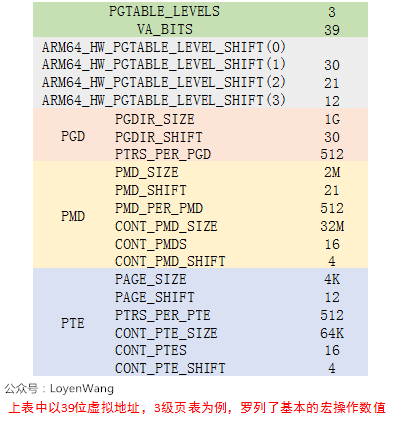
页表处理
/*描述各级页表中的页表项*/
typedef struct { pteval_t pte; } pte_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
/* 将页表项类型转换成无符号类型 */
#define pte_val(x) ((x).pte)
#define pmd_val(x) ((x).pmd)
#define pud_val(x) ((x).pud)
#define pgd_val(x) ((x).pgd)
/* 将无符号类型转换成页表项类型 */
#define __pte(x) ((pte_t) { (x) } )
#define __pmd(x) ((pmd_t) { (x) } )
#define __pud(x) ((pud_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
/* 获取页表项的索引值 */
#define pgd_index(addr) (((addr) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1))
#define pud_index(addr) (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1))
#define pmd_index(addr) (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1))
#define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
/* 获取页表中entry的偏移值 */
#define pgd_offset(mm, addr) (pgd_offset_raw((mm)->pgd, (addr)))
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
#define pud_offset_phys(dir, addr) (pgd_page_paddr(*(dir)) + pud_index(addr) * sizeof(pud_t))
#define pud_offset(dir, addr) ((pud_t *)__va(pud_offset_phys((dir), (addr))))
#define pmd_offset_phys(dir, addr) (pud_page_paddr(*(dir)) + pmd_index(addr) * sizeof(pmd_t))
#define pmd_offset(dir, addr) ((pmd_t *)__va(pmd_offset_phys((dir), (addr))))
#define pte_offset_phys(dir,addr) (pmd_page_paddr(READ_ONCE(*(dir))) + pte_index(addr) * sizeof(pte_t))
#define pte_offset_kernel(dir,addr) ((pte_t *)__va(pte_offset_phys((dir), (addr))))
3.2 head.S中的页表映射
3.2.1 idmap_pg_dir和swapper_pg_dir临时页表
是时候来个实例分析了,看看页表的创建过程,代码路径:arch/arm64/kernel/head.S。
内核启动过程中,在真正的物理内存尚未添加进系统,以及页表还未初始化之前,为了保证系统能正常运行,需要建立两个临时全局页表:idmap_pg_dir和swapper_pg_dir:
其中两个全局页表的定义在arch/arm64/kernel/vmlinux.lds.S中,放置在BSS段之后:
. = ALIGN(PAGE_SIZE);
idmap_pg_dir = .;
. += IDMAP_DIR_SIZE;
swapper_pg_dir = .;
. += SWAPPER_DIR_SIZE;
/* 定义了连续的几个页,分别存放PGD,PMD,PTE等,连续在一起,这个也是head.S中填充的 */
#define SWAPPER_DIR_SIZE (SWAPPER_PGTABLE_LEVELS * PAGE_SIZE)
#define IDMAP_DIR_SIZE (IDMAP_PGTABLE_LEVELS * PAGE_SIZE)
idmap_pg_dir
从名字可以看出,identify map,也就是物理地址和虚拟地址是相等的。为什么需要这么一个映射呢?我们都知道在MMU打开之前,CPU访问的都是物理地址,那么当MMU打开后访问的就是虚拟地址了,这段页表的映射就是从CPU到打开MMU之前的这段代码物理地址的映射,防止开启MMU后,无法获取页表。可以从System.map文件中查看这些代码:
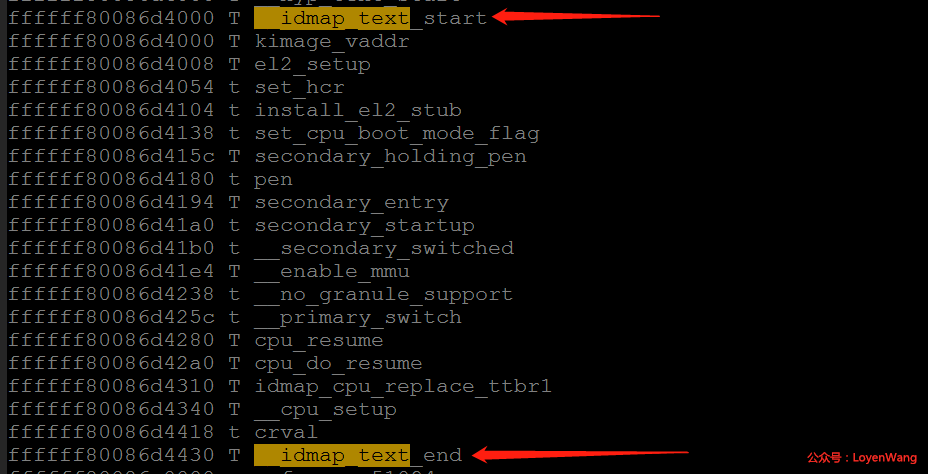
swapper_pg_dir
Linux内核编译后,kernel image是需要进行映射的,包括text,data等各种段。
3.2.2 页表创建
在head.S中,创建页表相关的有三个宏:
create_pgd_entry
/*
* Macro to populate the PGD (and possibily PUD) for the corresponding
* block entry in the next level (tbl) for the given virtual address.
*
* Preserves: tbl, next, virt
* Corrupts: tmp1, tmp2
*/
.macro create_pgd_entry, tbl, virt, tmp1, tmp2
create_table_entry \tbl, \virt, PGDIR_SHIFT, PTRS_PER_PGD, \tmp1, \tmp2
#if SWAPPER_PGTABLE_LEVELS > 3
create_table_entry \tbl, \virt, PUD_SHIFT, PTRS_PER_PUD, \tmp1, \tmp2
#endif
#if SWAPPER_PGTABLE_LEVELS > 2
create_table_entry \tbl, \virt, SWAPPER_TABLE_SHIFT, PTRS_PER_PTE, \tmp1, \tmp2
#endif
.endm
上述函数主要是调用create_table_entry,由于SWAPPER_PGTABLES配置为3,因此相当于创建了pgd和pmd两级页表,此处需要注意一点,create_table_entry函数执行后,tbl参数会自动加上PAGE_SIZE,也就是说pgd和pmd两级页表是物理连续的。
create_block_map
/*
* Macro to populate block entries in the page table for the start..end
* virtual range (inclusive).
*
* Preserves: tbl, flags
* Corrupts: phys, start, end, pstate
*/
.macro create_block_map, tbl, flags, phys, start, end
lsr \phys, \phys, #SWAPPER_BLOCK_SHIFT
lsr \start, \start, #SWAPPER_BLOCK_SHIFT
and \start, \start, #PTRS_PER_PTE - 1 // table index
orr \phys, \flags, \phys, lsl #SWAPPER_BLOCK_SHIFT // table entry
lsr \end, \end, #SWAPPER_BLOCK_SHIFT
and \end, \end, #PTRS_PER_PTE - 1 // table end index
9999: str \phys, [\tbl, \start, lsl #3] // store the entry
add \start, \start, #1 // next entry
add \phys, \phys, #SWAPPER_BLOCK_SIZE // next block
cmp \start, \end
b.ls 9999b
.endm
上述函数主要是往block中填充pte entry,真正创建虚拟地址到物理地址的映射,映射区域:start ~ end。
create_table_entry
/*
* Macro to create a table entry to the next page.
*
* tbl: page table address
* virt: virtual address
* shift: #imm page table shift
* ptrs: #imm pointers per table page
*
* Preserves: virt
* Corrupts: tmp1, tmp2
* Returns: tbl -> next level table page address
*/
.macro create_table_entry, tbl, virt, shift, ptrs, tmp1, tmp2
lsr \tmp1, \virt, #\shift
and \tmp1, \tmp1, #\ptrs - 1 // table index
add \tmp2, \tbl, #PAGE_SIZE
orr \tmp2, \tmp2, #PMD_TYPE_TABLE // address of next table and entry type
str \tmp2, [\tbl, \tmp1, lsl #3]
add \tbl, \tbl, #PAGE_SIZE // next level table page
.endm
上述函数创建页表项,并且返回下一个Level的页表地址。
上述三个孤立的函数并不直观,所以,图来了:
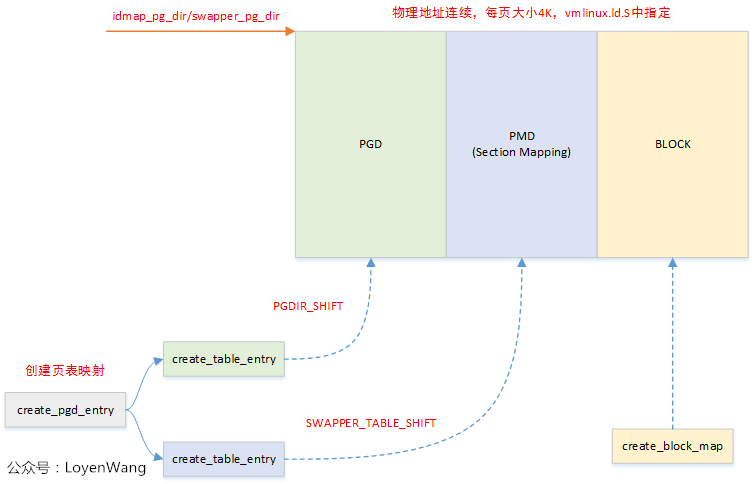
总体来说,页表的创建过程相对来说还是比较易懂的,掌握好几级页表及各级页表index所占的位域,此外熟悉各个Level页表中entry的格式,理解起来就会顺畅很多了。
一抠细节深似海,点到为止,防止一叶障目不见泰山,收工!

【原创】ARMv8 MMU及Linux页表映射的更多相关文章
- 通过crash了解linux页表
目的: 通过一个c语言实例,了解linux页表的组织结果和mmu的工作原理. 通过页表找到一个物理地址, 对比物理地址与虚拟地址的内容是否一致. 运行环境: $ uname -r3.15.6-200. ...
- [置顶] 【原创分享】嵌入式linux应用之内核移植定制篇-前篇(linux-3.8.12 mini2440)--20130824
移植的话其实很早就做过了,不过那时用的友善定制的老版本2.6.32 驱动什么的全部弄好了,仅仅用默认配置而已.基本不用改动什么,很简单. 内核更新其实非常的快,今天我就用个3.8.12来移植. 当然, ...
- Linux kernel 内存 - 页表映射(SHIFT,SIZE,MASK)和转换(32位,64位)
0. Intro 如下是在32位下的情况,32位下,只有三级页表:PGD,PMD,PTE 在64位情况下,会有四级页表:PGD,PUD,PMD,PTE 但是原理基本上是一样的,本文主要是想记录一下页表 ...
- x86平台上的Windows页表映射机制
首先,在x86架构的处理器上,一个正常页面大小为4KB,非PAE模式下,CR3持有页目录页面的物理地址,PDE和PTE格式相同大小为4字节.此时每个页表页面包含1024个PTE,可以映射1024个页面 ...
- [转载]linux内存映射mmap原理分析【转】
转自:http://www.cnblogs.com/wanpengcoder/articles/5306688.html 转自:http://blog.csdn.net/yusiguyuan/arti ...
- linux 逆向映射机制浅析
2017-05-20 聚会回来一如既往的看了会羽毛球比赛,然后想到前几天和朋友讨论的逆向映射的问题,还是简要总结下,免得以后再忘记了!可是当我添加时间……这就有点尴尬了……520还在写技术博客…… 闲 ...
- linux 内存映射-ioremap和mmap函数
最近开始学习Linux驱动程序,将内存映射和ioremap,mmap函数相关资料进行了整理 一,内存映射 对于提供了MMU(存储管理器,辅助操作系统进行内存管理,提供虚实地址转换等硬件支持)的处理器 ...
- 快速配置 Samba 将 Linux 目录映射为 Windows 驱动器,用于跨平台编程
一.局域网内的 Linux 服务器上操作步骤: 1.安装samba(CentOS Linux): yum install samba system-config-samba samba-client ...
- Linux内存映射(mmap)系列(1)
看到同事的代码中出现了mmap.所以自己私下学习学习,研究研究..... http://www.cnblogs.com/lknlfy/archive/2012/04/27/2473804.html ( ...
随机推荐
- SQLyog12最新版破解
1.SQLyog-12.2.4-0.x64Trial.exe,直接去官网下载. 2.修改注册表项 开始-运行-regedit ,进入注册表 HKEY_CURRENT_USER\Software\ ...
- PHP对接口执行效率慢的优化
PHP对接口执行效率慢的优化 PHP对接口执行效率慢的优化 造成执行效率低的原因可以由很多方面找原因 从代码层面,代码质量低,执行效率也会有很大影响的. 从硬件方面,服务器配置低,服务器配置是基础,这 ...
- 转 java - 如何判断单链表有环
转自 https://blog.csdn.net/u010983881/article/details/78896293 1.穷举遍历 首先从头节点开始,依次遍历单链表的每一个节点.每遍历到一个新节点 ...
- 统计学习方法6—logistic回归和最大熵模型
目录 logistic回归和最大熵模型 1. logistic回归模型 1.1 logistic分布 1.2 二项logistic回归模型 1.3 模型参数估计 2. 最大熵模型 2.1 最大熵原理 ...
- Java中Timer和TimerTask来实现计时器循环触发
package xian; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.Fi ...
- 夯实Java基础(五)——==与equals()
1.前言 我们在学习Java的时候,看到==.equals()就认为比较简单,随便看了一眼就过了,其实你并没有深入去了解二者的区别.这个问题在面试的时候出现的频率比较高,而且据统计有85%的人理直气壮 ...
- Lua语言学习
1,语法 语句不用分号结尾 function ... end if .. else .. end 2, io库, string库, table库, OS库, 算术库, debug库 3, dofile ...
- Docker 更新版本
Docker 更新版本 原来版本 1.10 更新后的版本 19.03.1 更新 Docker 版本需要注意的问题: 注意系统是否支持新版本的储存驱动. 19.03.01 版本默认使用的储存驱动是 ov ...
- sql语句优化:尽量使用索引避免全表扫描
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 程序员修神之路--用NOSql给高并发系统加速(送书)
随着互联网大潮的到来,越来越多网站,应用系统需要海量数据的支撑,高并发.低延迟.高可用.高扩展等要求在传统的关系型数据库中已经得不到满足,或者说关系型数据库应对这些需求已经显得力不从心了.关系型数据库 ...