python爬取 “得到” App 电子书信息
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 静觅 崔庆才
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
mitmdump 爬取 “得到” App 电子书信息
“得到” App 是罗辑思维出品的一款碎片时间学习的 App,App 内有很多学习资源。不过 “得到” App 没有对应的网页版,所以信息必须要通过 App 才可以获取。这次我们通过抓取其 App 来练习 mitmdump 的用法。
爬取目标
我们的爬取目标是 App 内电子书版块的电子书信息,并将信息保存到 MongoDB,如图所示。
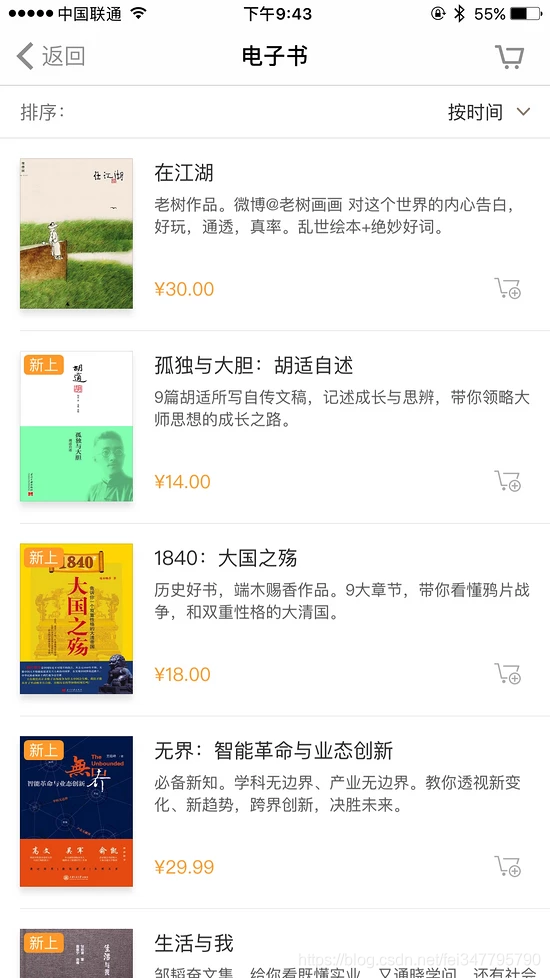
我们要把图书的名称、简介、封面、价格爬取下来,不过这次爬取的侧重点还是了解 mitmdump 工具的用法,所以暂不涉及自动化爬取,App 的操作还是手动进行。mitmdump 负责捕捉响应并将数据提取保存。
2. 准备工作
请确保已经正确安装好了 mitmproxy 和 mitmdump,手机和 PC 处于同一个局域网下,同时配置好了 mitmproxy 的 CA 证书,安装好 MongoDB 并运行其服务,安装 PyMongo 库,具体的配置可以参考第 1 章的说明。
3. 抓取分析
首先探寻一下当前页面的 URL 和返回内容,我们编写一个脚本如下所示:
def response(flow):
print(flow.request.url)
print(flow.response.text)
这里只输出了请求的 URL 和响应的 Body 内容,也就是请求链接和响应内容这两个最关键的部分。脚本保存名称为 script.py。
接下来运行 mitmdump,命令如下所示:
mitmdump -s script.py
打开 “得到” App 的电子书页面,便可以看到 PC 端控制台有相应输出。接着滑动页面加载更多电子书,控制台新出现的输出内容就是 App 发出的新的加载请求,包含了下一页的电子书内容。控制台输出结果示例如图 所示。 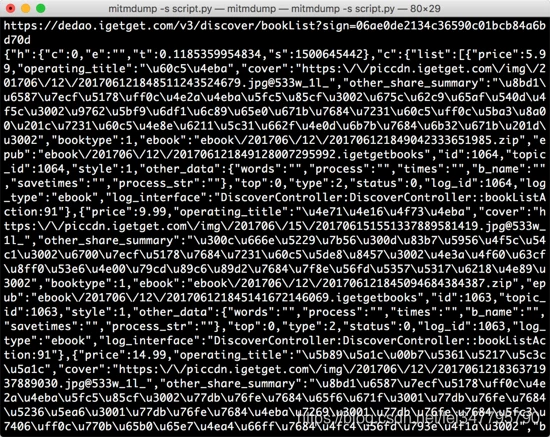
可以看到 URL 为 https://dedao.igetget.com/v3/discover/bookList 的接口,其后面还加了一个 sign 参数。通过 URL 的名称,可以确定这就是获取电子书列表的接口。在 URL 的下方输出的是响应内容,是一个 JSON 格式的字符串,我们将它格式化,如图 所示。
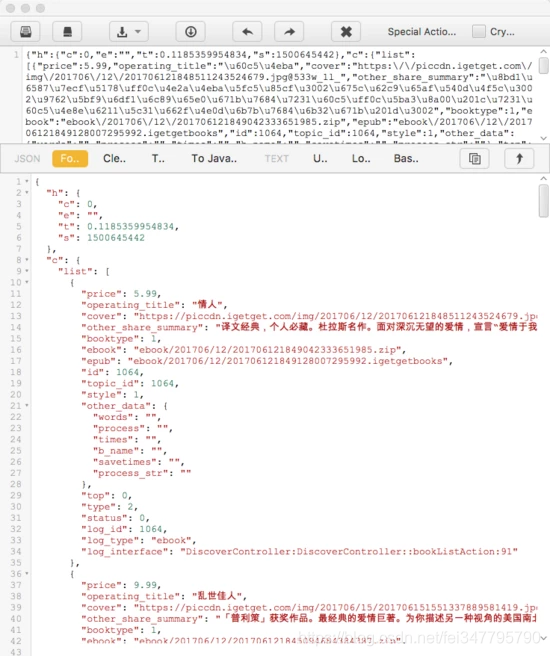
格式化后的内容包含一个 c 字段、一个 list 字段,list 的每个元素都包含价格、标题、描述等内容。第一个返回结果是电子书《情人》,而此时 App 的内容也是这本电子书,描述的内容和价格也是完全匹配的,App 页面如图所示。
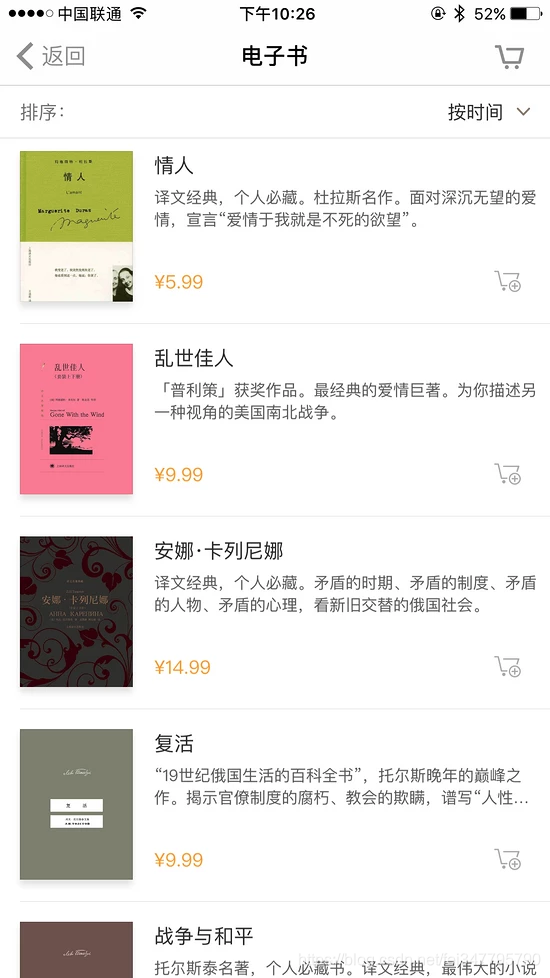
这就说明当前接口就是获取电子书信息的接口,我们只需要从这个接口来获取内容就好了。然后解析返回结果,将结果保存到数据库。
4. 数据抓取
接下来我们需要对接口做过滤限制,抓取如上分析的接口,再提取结果中的对应字段。
这里,我们修改脚本如下所示:
import json
from mitmproxy import ctx def response(flow):
url = 'https://dedao.igetget.com/v3/discover/bookList'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
ctx.log.info(str(book))
重新滑动电子书页面,在 PC 端控制台观察输出,如图所示。
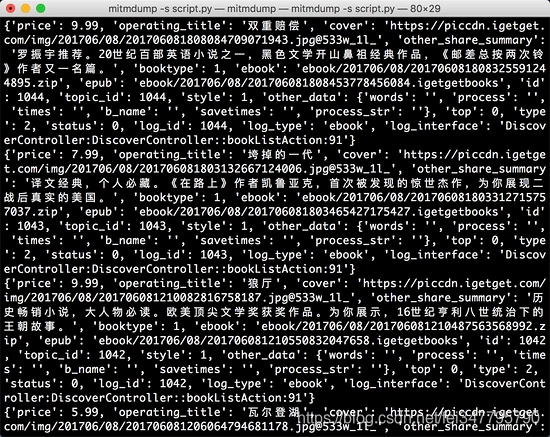
控制台输出
现在输出了图书的全部信息,一本图书信息对应一条 JSON 格式的数据。
5. 提取保存
接下来我们需要提取信息,再把信息保存到数据库中。方便起见,我们选择 MongoDB 数据库。
脚本还可以增加提取信息和保存信息的部分,修改代码如下所示:
import json
import pymongo
from mitmproxy import ctx client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books'] def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/discover/bookList'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
重新滑动页面,控制台便会输出信息,如图所示。
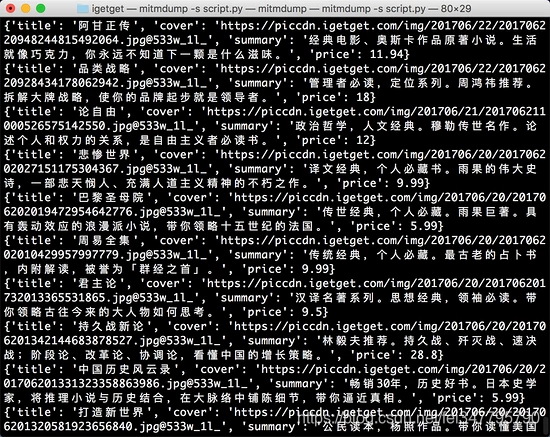
现在输出的每一条内容都是经过提取之后的内容,包含了电子书的标题、封面、描述、价格信息。
最开始我们声明了 MongoDB 的数据库连接,提取出信息之后调用该对象的 insert() 方法将数据插入到数据库即可。
滑动几页,发现所有图书信息都被保存到 MongoDB 中,如图所示。
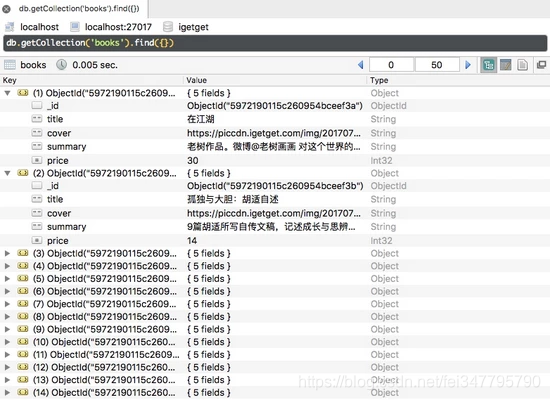
目前为止,我们利用一个非常简单的脚本把 “得到” App 的电子书信息保存下来。
代码部分
import json
import pymongo
from mitmproxy import ctx
client = pymongo.MongoClient('localhost')
db = client['igetget']
collection = db['books']
def response(flow):
global collection
url = 'https://dedao.igetget.com/v3/discover/bookList'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
books = data.get('c').get('list')
for book in books:
data = {
'title': book.get('operating_title'),
'cover': book.get('cover'),
'summary': book.get('other_share_summary'),
'price': book.get('price')
}
ctx.log.info(str(data))
collection.insert(data)
python爬取 “得到” App 电子书信息的更多相关文章
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- Python爬取房天下二手房信息
一.相关知识 BeautifulSoup4使用 python将信息写入csv import csv with open("11.csv","w") as csv ...
- python爬取北京政府信件信息01
python爬取,找到目标地址,开始研究网页代码格式,于是就开始根据之前学的知识进行爬取,出师不利啊,一开始爬取就出现了个问题,这是之前是没有遇到过的,明明地址没问题,就是显示网页不存在,于是就在百度 ...
- Python 爬取赶集网租房信息
代码已久,有可能需要调整 #coding:utf-8 from bs4 import BeautifulSoup #有这个bs4不用正则也可以定位要爬取的内容了 from urlparse impor ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
- Python爬取简书主页信息
主要学习如何通过抓包工具分析简书的Ajax加载,有时间再写一个Multithread proxy spider提升效率. 1. 关键点: 使用单线程爬取,未登录,爬取简书主页Ajax加载的内容.主要有 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- Python 爬取外文期刊论文信息(机械 仪表工业)
NSTL国家科技图书文献中心 2017 机械 仪表工业 所有期刊论文信息 代码比较随意,不要介意 第一步,爬取所有期刊链接 #coding=utf-8 import time from se ...
随机推荐
- IT兄弟连 HTML5教程 CSS3揭秘 CSS常见的样式属性和值4
6 鼠标光标属性 在网页中默认的鼠标指针只有两种,一种是最普通的箭头,另一种是当移动到链接上时出现的“小手”.但现在越来越多的网页都使用了CSS鼠标指针技术,当将鼠标移动到链接上时,可以看到多种不同 ...
- Springboot关于tomcat容器配置、三大组件配置、拦截器配置
原文地址:http://www.javayihao.top/detail/172 1.tomcat配置 Springboot默认使用的就是嵌入式servlet容器即tomcat,对于web项目,如果使 ...
- 在Asp.Net Core中配置使用MarkDown富文本编辑器实现图片上传和截图上传(开源代码.net core3.0)
我们的富文本编辑器不能没有图片上传尤其是截图上传,下面我来教大家怎么实现MarkDown富文本编辑器截图上传和图片上传. 1.配置编辑器到html页 <div id="test-edi ...
- 如何使用压缩的方式将Windows下的zip压缩包上传到Linux系统
我们可以使用在Windows下压缩文件夹,然后到Linux系统下解压缩的方式,完成整个上传工作. 第一步:在Windows系统下,将整个文件夹压缩成zip后缀的压缩包 方法一:
- MySQL数据库(二)事务
MySQL的存储引擎InnoDB支持事务,MyISAM不支持事物 数据库事务的四大特性(ACID) 原子性(atomic) 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客 ...
- Python机器学习笔记——One Class SVM
前言 最近老板有一个需求,做单样本检测,也就是说只有一个类别的数据集与标签,因为在工厂设备中,控制系统的任务是判断是是否有意外情况出现,例如产品质量过低,机器产生奇怪的震动或者机器零件脱落等.相对来说 ...
- 201871010123-吴丽丽《面向对象程序设计(Java)》第十三周学习总结
201871010123-吴丽丽<面向对象程序设计(Java)>第十三周学习总结 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ ...
- Leetcode103_Binary-tree-zigzag-level-order-traversal
原题: https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal/ 思路,如果无从下手,先要了解二叉树的广度优 ...
- 《3D_Deep_Learning_for_Robot_Perception.pdf》
https://github.com/PrincetonVision/marvin
- 微信小程序开发——websocket测试
服务端 在windows下执行 node server.js 也可参照我的前一篇部署https var httpServ = require('http') var WebSocketServer ...