数据挖掘--OPTICS
OPTICS是基于DBSCAN算法的缺陷提出来的一个算法。
核心思想:为每个数据对象计算出一个顺序值(ordering)。这些值代表了数据对象的基于密度的族结构,位于同一个族的数据对象具有相近的顺序值。根据这些顺序值将全体数据对象用一个图示的方式排列出来,根据排列的结果就可以得到不同层次的族。
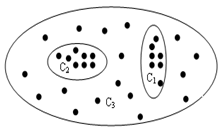
考察DBSCAN,可以发现,对一个恒定的MinPts值来说,取值较小时得到的聚类结果完全包含在根据较大的取值所获得的聚类结果中。
如图,当取值较小时,得到的聚类结果是C1和C2,当取值较大时,得到的聚类结果是C3。
可以看到,C1和C2是包含在C3中的。换句话说,C1、C2、C3间具有层次关系,C3可以看作是C1和C2的父亲,而C1和C2可以看作是C3的孩子。
因此,在生成族的时候,最好能够将位于不同层次上的族同时构建出来,而不是根据某个特定的值仅仅构建其中的一层。
为了同时构建不同层次上的族,数据对象应当以特定的顺序来处理。这个顺序称为族序(cluster-ordering),它决定了对象扩展时的次序。
为了使较低层次上的族(这些族的数据密度较大)能够首先构建完成,在进行对象扩展时,应该优先选择那些根据最小的取值而密度可达的对象。
基于这个思想,每个数据对象需要存储两个值,一个是核心距离(core-distance),另一个是可达距离(reach-distance)。
核心距离:给定一个数据对象集合D,两个参数和MinPts,一个对象O,如果O是一个核心对象,则O的核心距离(core-dist)是使得O能成为核心对象的最小半径值(该值小于等于)。如果O不是核心对象,则O的核心距离没有定义。
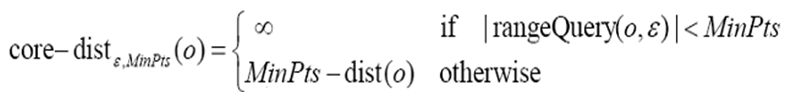
其中|rangeQuery(O, )|<MinPts表示在O的-邻域的数据对象的个数小于MinPts个,说明在这种情况下O不是一个核心对象。
反之,当O是一个核心对象时,MinPts-dist(O)表示的就是使得O的-邻域能够包含MinPts个数据对象的最小半径值。
例如,给定MinPts=5, 则表示的半径就是对象O的核心距离
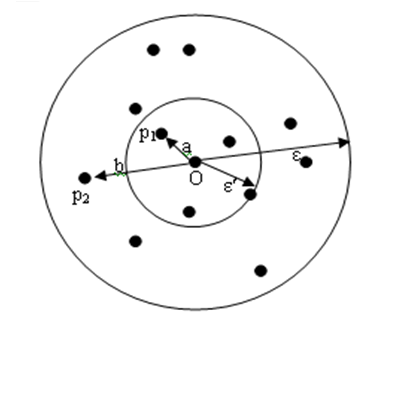
可达距离:给定一个数据对象集合D,两个参数和MinPts,一个对象O,如果O是一个核心对象,则O与另一个对象p间的可达距离(reachbility-distance)是O的核心距离和O与p的欧几里得距离之间的较大值。如果O不是一个核心对象,O与p之间的可达距离没有定义。
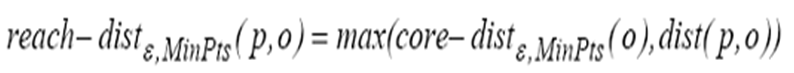
由于p1和O之间的距离a小于对象O的核心距离,即dist(p1, O) < core-dist(O),所以p1和O之间的可达距离就是对象O的核心距离。即reach-dist(p1, O) = core-dist(O)= 。
由于p2和O之间的欧几里得距离b大于对象O的核心距离,即dist(p2, O) > core-dist(O),所以p2和O之间的可达距离就是p2和O之间的欧几里得距离。即reach-dist(p2, O) = dist(p2, O)。
OPTICS算法的工作过程
- 第一个阶段计算每个对象的核心距离和可达距离,生成族序;
- 采用和DBSCAN算法类似的工作过程。同样从任意一个数据对象p开始,如果p是一个核心对象,则根据输入的两个参数和MinPts,提取所有从p直接密度可达的数据对象,计算它们的核心距离和可达距离,并将它们放入待处理队列Q中。
- 接下来,算法从Q中选取一个具有最小可达距离值的对象q进行进一步的扩展。同样,首先检查q是否是核心对象,如果是,则根据输入参数和MinPts,提取所有从q直接密度可达的数据对象,计算它们的核心距离和可达距离,并将它们放入待处理队列Q中。如果q不是核心对象,则什么都不做。
- 需要注意的是,对q进行扩展时,还需要对队列Q中的数据对象的可达距离进行更新,保证其存储的是到最近的核心对象的距离。算法一直进行到所有的数据对象都被处理过为止。
- 第二个阶段进行聚类,在聚类的过程中,只需要用到第一阶段所生成的对象之间的族序信息,不再需要其它的信息。
- 根据第一阶段所生成的族序和特定的i(0i )值,生成相应的族。具体过程是:根据族序逐个处理每一个对象。
- 对任一对象p,首先看p的可达距离是否大于i。如果是,则说明在p之前所处理过的对象,没有一个对象到p是可达的。(这是因为,如果某个对象到p可达的话,p的可达距离不可能大于i)。因此,如果p的可达距离大于i的话,需要进一步考察p的核心距离。
- 如果p的核心距离小于i,则说明p是一个核心对象,这时创建一个新族
- 否则,将p标记为噪声。
- 如果p的可达距离小于等于i的话,则直接将p标记为当前族。
数据挖掘--OPTICS的更多相关文章
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 跟我一起数据挖掘(23)——C4.5
C4.5简介 C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法.它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类.C4.5的目 ...
- ITTC数据挖掘平台介绍(四) 框架改进和新功能
本数据挖掘框架在这几个月的时间内,有了进一步的功能增强 一. 超大网络的画布显示虚拟化 如前几节所述,框架采用了三级层次实现,分别是数据,抽象Node和绘图的DataPoint,结构如下: ...
- ITTC数据挖掘平台介绍(五) 数据导入导出向导和报告生成
一. 前言 经过了一个多月的努力,软件系统又添加了不少新功能.这些功能包括非常实用的数据导入导出,对触摸进行优化的画布和画笔工具,以及对一些智能分析的报告生成模块等.进一步加强了平台系统级的功能. 马 ...
- ITTC数据挖掘系统(六)批量任务,数据查看器和自由文档
这一次带来了一系列新特新,同时我们将会从商业智能的角度讨论软件的需求 一. 批量任务向导 一个常用的需求是完成处理多个任务,可能是同一个需求以不同的参数完成多次,这类似批量分析某一问题:或者是不同的需 ...
- ITTC数据挖掘平台介绍(七)强化的数据库, 虚拟化,脚本编辑器
一. 前言 好久没有更新博客了,最近一直在忙着找工作,目前差不多尘埃落定.特别期待而且准备的都很少能成功,反而是没怎么在意的最终反而能拿到,真是神一样的人生. 言归正传,一直以来,数据挖掘系统的数据类 ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
随机推荐
- [Go] gocron源码阅读-go语言web框架Macaron
gocron源码中使用的是马卡龙框架,下面这个就是安装这个框架,和一般的MVC框架很像go get gopkg.in/macaron.v1git clone https://github.com/go ...
- Windows 10系统迁移
快速复制硬盘可以调整目标盘分区大小(适用于不同容量的硬盘克隆) 调整完目标盘的系统分区大小后将恢复分区拖到系统分区后面对齐,恢复分区后面既可留出未分配容量用作Linux系统安装. 克隆完成后对uefi ...
- 关于linux shell的一点知识
$ . a.sh 接受脚本中环境变量,如声明 b=2 &!进程号 内置环境变量
- Windows10下Git环境变量配置
一.确定Git正确安装并能使用 右键项目目录,检查Git版本: 输入: git --version 二. 配置环境变量 右键我的电脑 --> 属性 点击高级系统设置 --> 环境变量 - ...
- jacoco统计自动化代码覆盖率
jacoco统计自动化代码覆盖率 1. 简介 1.1. 什么是Jacoco Jacoco是一个开源的代码覆盖率工具,可以嵌入到Ant .Maven中,并提供了EclEmma Eclipse插件,也可以 ...
- C++ STL priority_queue 优先队列
优先队列: 与队列的用法是一样的,优先队列内部是通过堆来排序实现的, #include<iostream> #include <queue> using namespace s ...
- 剑指Offer-21.栈的压入、弹出序列(C++/Java)
题目: 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序.假设压入栈的所有数字均不相等.例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈 ...
- Manthan, Codefest 18 (rated, Div. 1 + Div. 2) E bfs + 离线处理
https://codeforces.com/contest/1037/problem/E 题意 有n个人,m天,在第i天早上,x和y会成为朋友,每天晚上大家都要上车,假如一个人要上车那么他得有至少k ...
- Paper | UNet++: A Nested U-Net Architecture for Medical Image Segmentation
目录 1. 故事 2. UNet++ 3. 实验 3.1 设置 作者的解读,讲得非常好非常推荐:https://zhuanlan.zhihu.com/p/44958351 这篇文章提出的嵌套U-Net ...
- pwntools出现的一些问题
pwntools用的好好的突然就不能用了总结了一些问题:ImportError:cannot import name ENUM_P_TYPE 解决方法为:将/usr/local/lib/python2 ...