算法与数据结构基础 - 字典树(Trie)
Trie基础
Trie字典树又叫前缀树(prefix tree),用以较快速地进行单词或前缀查询,Trie节点结构如下:
//208. Implement Trie (Prefix Tree)
class TrieNode{
public:
TrieNode* children[]; //或用链表、map表示子节点
bool isWord; //标识该节点是否为单词结尾
TrieNode(){
memset(children,,sizeof(children));
isWord=false;
}
};
插入单词的方法如下:
void insert(string word) {
TrieNode* p=root;
for(auto w:word){
if(p->children[w-'a']==NULL) p->children[w-'a']=new TrieNode;
p=p->children[w-'a'];
}
p->isWord=true;
}
假如有单词序列 ["a", "to", "tea", "ted", "ten", "i", "in", "inn"],则完成插入后有如下结构:
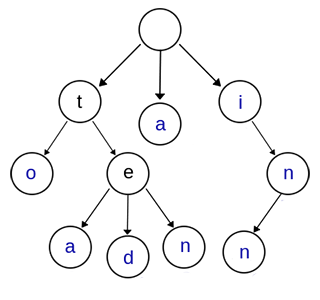
Trie的root节点不包含字符,以上蓝色节点表示isWord标记为true。在建好的Trie结构里查找单词或单词前缀的方法如下:
/** Returns if the word is in the trie. */
bool search(string word) {
TrieNode* p=root;
for(auto w:word){
if(p->children[w-'a']==NULL) return false;
p=p->children[w-'a'];
}
return p->isWord;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
TrieNode* p=root;
for(auto w:prefix){
if(p->children[w-'a']==NULL) return false;
p=p->children[w-'a'];
}
return true;
}
相关LeetCode题:
208. Implement Trie (Prefix Tree) 题解
Trie与Hash table比较
同样用于快速查找,经常会拿Hash table和Trie相互比较。从以上Trie的构建和查找代码可知,构建Trie的时间复杂度和文本长度线性相关、查找时间复杂度和单词长度线性相关;对Trie空间复杂度来说,如果数据按前缀聚拢,那么有利于减少Trie的存储空间。
对Hash table而言,虽然查找过程是O(1),但另需考虑hash函数本身的时间消耗;另对于字符串prefix查找问题,并不能直接用Hash table解决,要么做一些提前功夫,将各个prefix也提前存入Hash table。
相关LeetCode题:
648. Replace Words Trie题解 HashTable题解
Trie的应用
Trie除了可以用于字符串检索、前缀匹配外,还可以用于词频统计、字符串排序、搜索自动补全等场景。
相关LeetCode题:
642. Design Search Autocomplete System 题解
算法与数据结构基础 - 字典树(Trie)的更多相关文章
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
- 『字典树 trie』
字典树 (trie) 字典树,又名\(trie\)树,是一种用于实现字符串快速检索的树形数据结构.核心思想为利用若干字符串的公共前缀来节约储存空间以及实现快速检索. \(trie\)树可以在\(O(( ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- 算法与数据结构基础 - 广度优先搜索(BFS)
BFS基础 广度优先搜索(Breadth First Search)用于按离始节点距离.由近到远渐次访问图的节点,可视化BFS 通常使用队列(queue)结构模拟BFS过程,关于queue见:算法与数 ...
- 算法与数据结构基础 - 二叉树(Binary Tree)
二叉树基础 满足这样性质的树称为二叉树:空树或节点最多有两个子树,称为左子树.右子树, 左右子树节点同样最多有两个子树. 二叉树是递归定义的,因而常用递归/DFS的思想处理二叉树相关问题,例如Leet ...
- 算法与数据结构基础 - 图(Graph)
图基础 图(Graph)应用广泛,程序中可用邻接表和邻接矩阵表示图.依据不同维度,图可以分为有向图/无向图.有权图/无权图.连通图/非连通图.循环图/非循环图,有向图中的顶点具有入度/出度的概念. 面 ...
- 算法与数据结构基础 - 深度优先搜索(DFS)
DFS基础 深度优先搜索(Depth First Search)是一种搜索思路,相比广度优先搜索(BFS),DFS对每一个分枝路径深入到不能再深入为止,其应用于树/图的遍历.嵌套关系处理.回溯等,可以 ...
- 字典树trie学习
字典树trie的思想就是利用节点来记录单词,这样重复的单词可以很快速统计,单词也可以快速的索引.缺点是内存消耗大 http://blog.csdn.net/chenleixing/article/de ...
- 算法与数据结构基础 - 堆(Heap)和优先级队列(Priority queue)
堆基础 堆(Heap)是具有这样性质的数据结构:1/完全二叉树 2/所有节点的值大于等于(或小于等于)子节点的值: 图片来源:这里 堆可以用数组存储,插入.删除会触发节点shift_down.shif ...
随机推荐
- Flags Over Objects
The Flags Over Objects anti-pattern occurs when behavior is written outside of an object by inspecti ...
- golang 单元测试&&性能测试
一:单元测试 1.为什么要做单元测试和性能测试 减少bug 快速定位bug 减少调试时间 提高代码质量 2.golang的单元测试 单元测试代码的go文件必须以_test.go结尾 单元测试的函数名必 ...
- 跟我学SpringCloud | 终篇:文章汇总(持续更新)
SpringCloud系列教程 | 终篇:文章汇总(持续更新) 我为什么这些文章?一是巩固自己的知识,二是希望有更加开放和与人分享的心态,三是接受各位大神的批评指教,有任何问题可以联系我: inwsy ...
- 基于SpringBoot从零构建博客网站 - 设计可扩展上传模块和开发修改头像密码功能
上传模块在web开发中是很常见的功能也是很重要的功能,在web应用中需要上传的可以是图片.pdf.压缩包等其它类型的文件,同时对于图片可能需要回显,对于其它文件要能够支持下载等.在守望博客系统中对于上 ...
- C语言学习书籍推荐《C和指针 Pointers On C》下载
<C和指针 POINTERS ON C>提供与C语言编程相关的全面资源和深入讨论.本书通过对指针的基础知识和高 级特性的探讨,帮助程序员把指针的强大功能融入到自己的程序中去. 全书共18 ...
- Java学习笔记之---方法和数组
Java学习笔记之---方法与数组 (一)方法 (1)什么是方法? 方法是解决一类问题的步骤的有序组合 方法包含于类或对象中 方法在程序中被创建,在其他地方被引用 (2)方法的优点 使程序变得更简短而 ...
- SQL Server Update 链接修改和when的应用
一.自链接方式 update b1 set b1.money = b1.money + b2.money from (select * from wallet where type='余额') b1 ...
- Ray-基础部分目录
基础部分: 引言 Actor编写-ESGrain与ESRepGrain 消息发布器与消息存储器 Event编写 Handler之CoreHandler编写 Handler之ToReadHandler编 ...
- Python重试模块retrying
Python重试模块retrying 工作中经常碰到的问题就是,某个方法出现了异常,重试几次.循环重复一个方法是很常见的.比如爬虫中的获取代理,对获取失败的情况进行重试. 刚开始搜的几个博客讲的有点问 ...
- Java编程思想:泛型方法
import java.util.*; public class Test { public static void main(String[] args) { // GenericMethods.t ...