算法与数据结构基础 - 字典树(Trie)
Trie基础
Trie字典树又叫前缀树(prefix tree),用以较快速地进行单词或前缀查询,Trie节点结构如下:
//208. Implement Trie (Prefix Tree)
class TrieNode{
public:
TrieNode* children[]; //或用链表、map表示子节点
bool isWord; //标识该节点是否为单词结尾
TrieNode(){
memset(children,,sizeof(children));
isWord=false;
}
};
插入单词的方法如下:
void insert(string word) {
TrieNode* p=root;
for(auto w:word){
if(p->children[w-'a']==NULL) p->children[w-'a']=new TrieNode;
p=p->children[w-'a'];
}
p->isWord=true;
}
假如有单词序列 ["a", "to", "tea", "ted", "ten", "i", "in", "inn"],则完成插入后有如下结构:
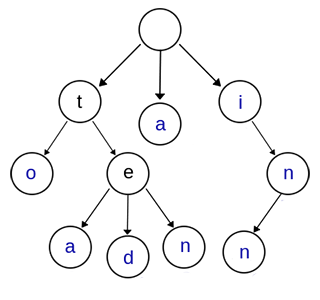
Trie的root节点不包含字符,以上蓝色节点表示isWord标记为true。在建好的Trie结构里查找单词或单词前缀的方法如下:
/** Returns if the word is in the trie. */
bool search(string word) {
TrieNode* p=root;
for(auto w:word){
if(p->children[w-'a']==NULL) return false;
p=p->children[w-'a'];
}
return p->isWord;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
TrieNode* p=root;
for(auto w:prefix){
if(p->children[w-'a']==NULL) return false;
p=p->children[w-'a'];
}
return true;
}
相关LeetCode题:
208. Implement Trie (Prefix Tree) 题解
Trie与Hash table比较
同样用于快速查找,经常会拿Hash table和Trie相互比较。从以上Trie的构建和查找代码可知,构建Trie的时间复杂度和文本长度线性相关、查找时间复杂度和单词长度线性相关;对Trie空间复杂度来说,如果数据按前缀聚拢,那么有利于减少Trie的存储空间。
对Hash table而言,虽然查找过程是O(1),但另需考虑hash函数本身的时间消耗;另对于字符串prefix查找问题,并不能直接用Hash table解决,要么做一些提前功夫,将各个prefix也提前存入Hash table。
相关LeetCode题:
648. Replace Words Trie题解 HashTable题解
Trie的应用
Trie除了可以用于字符串检索、前缀匹配外,还可以用于词频统计、字符串排序、搜索自动补全等场景。
相关LeetCode题:
642. Design Search Autocomplete System 题解
算法与数据结构基础 - 字典树(Trie)的更多相关文章
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
- 『字典树 trie』
字典树 (trie) 字典树,又名\(trie\)树,是一种用于实现字符串快速检索的树形数据结构.核心思想为利用若干字符串的公共前缀来节约储存空间以及实现快速检索. \(trie\)树可以在\(O(( ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- 算法与数据结构基础 - 广度优先搜索(BFS)
BFS基础 广度优先搜索(Breadth First Search)用于按离始节点距离.由近到远渐次访问图的节点,可视化BFS 通常使用队列(queue)结构模拟BFS过程,关于queue见:算法与数 ...
- 算法与数据结构基础 - 二叉树(Binary Tree)
二叉树基础 满足这样性质的树称为二叉树:空树或节点最多有两个子树,称为左子树.右子树, 左右子树节点同样最多有两个子树. 二叉树是递归定义的,因而常用递归/DFS的思想处理二叉树相关问题,例如Leet ...
- 算法与数据结构基础 - 图(Graph)
图基础 图(Graph)应用广泛,程序中可用邻接表和邻接矩阵表示图.依据不同维度,图可以分为有向图/无向图.有权图/无权图.连通图/非连通图.循环图/非循环图,有向图中的顶点具有入度/出度的概念. 面 ...
- 算法与数据结构基础 - 深度优先搜索(DFS)
DFS基础 深度优先搜索(Depth First Search)是一种搜索思路,相比广度优先搜索(BFS),DFS对每一个分枝路径深入到不能再深入为止,其应用于树/图的遍历.嵌套关系处理.回溯等,可以 ...
- 字典树trie学习
字典树trie的思想就是利用节点来记录单词,这样重复的单词可以很快速统计,单词也可以快速的索引.缺点是内存消耗大 http://blog.csdn.net/chenleixing/article/de ...
- 算法与数据结构基础 - 堆(Heap)和优先级队列(Priority queue)
堆基础 堆(Heap)是具有这样性质的数据结构:1/完全二叉树 2/所有节点的值大于等于(或小于等于)子节点的值: 图片来源:这里 堆可以用数组存储,插入.删除会触发节点shift_down.shif ...
随机推荐
- easyui 使用jquery动态添加组件样式问题
可以使用$.parser.parse();这个方法进行处理: 例如: $.parser.parse(); 表示对整个页面重新渲染,渲染完就可以看到easyui原来的样式了: var targe ...
- [AI开发]目标跟踪之速度计算
基于视频结构化的应用中,目标在经过跟踪算法后,会得到一个唯一标识和它对应的运动轨迹,利用这两个数据我们可以做一些后续工作:测速(交通类应用场景).计数(交通类应用场景.安防类应用场景)以及行为检测(交 ...
- c++ 逆序对
c++ 求逆序对 例如数组(3,1,4,5,2)的逆序对有(3,1)(3,2)(4,2)(5,2)共4个 逆序对就是左边的元素比右边的大,那么左边的元素和右边的元素就能产生逆序对 代码跟归并排序差不多 ...
- Linux命令学习-ps命令
Linux中,ps命令的全称是process status,即进程状态的意思,主要作用是列出系统中当前正在运行的进程信息. ps命令的功能很强大,参数也非常多,下面只举几个简单的实例. 显示所有进程信 ...
- Java是如何实现平台无关性的
相信对于很多Java开发来说,在刚刚接触Java语言的时候,就听说过Java是一门跨平台的语言,Java是平台无关性的,这也是Java语言可以迅速崛起并风光无限的一个重要原因.那么,到底什么是平台无关 ...
- React躬行记(8)——样式
由于React推崇组件模式,因此会要求HTML.CSS和JavaScript混合在一起,虽然这与过去的关注点分离正好相反,但是更有利于组件之间的隔离.React已将HTML用JSX封装,而对CSS只进 ...
- C#开发中常用的加密算法总结
相信很多人在开发过程中经常会遇到需要对一些重要的信息进行加密处理,今天给大家分享我个人总结的一些加密算法: 常见的加密方式分为可逆和不可逆两种方式 可逆:RSA,AES,DES等 不可逆:常见的MD5 ...
- NOIP2018&2013提高组T1暨洛谷P5019 铺设道路
题目链接:https://www.luogu.org/problemnew/show/P5019 花絮:普及蒟蒻终于A了一道提高的题目?emm,写一篇题解纪念一下吧.求过! 分析: 这道题我们可以采用 ...
- RSA premaster secret error 错误解决
报错信息如下: Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: 驱动程序无法使用安全套接字层(SSL)加密与 SQL Serve ...
- MySql的数据库优化到底优啥了都??(1)
嘟嘟最不愿意做的就是翻招聘信息. 因为一翻招聘信息,工作经历你写低于两年都不好意思,前后端必须炉火纯青融汇贯通,各式框架必须如数家珍不写精通咋的你也得熟练熟练, 对了你是985吗?你是211吗??你不 ...